一:何为缓存穿透
举个栗子,当用户查询一个数据,首先查redis内存数据库发现没有,即缓存没命中。于是向持久层数据库(mongo,mysql等)查询,发现也没有,于是本次查询失败。当用户很多的时候,缓存都没有命中,于是都去请求了持久层数据库。这会给持久层数据库造成很大的压力,这就是缓存穿透。
缓存穿透和缓存击穿的区别:缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求持久层数据库,就像在一个屏障上凿开了一个洞。
二:何为波隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
如果想要判断一个元素是不是在一个集合里,一般想到的是将所有元素保存起来,然后通过比较确定。链表,树等等数据结构都是这种思路. 但是随着集合中元素的增加,我们需要的存储空间越来越大,检索速度也越来越慢(O(n),O(logn))。不过世界上还有一种叫作散列表(又叫哈希表,Hash table)的数据结构。它可以通过一个Hash函数将一个元素映射成一个位阵列(Bit array)中的一个点。这样一来,我们只要看看这个点是不是1就可以知道集合中有没有它了。
三:基本思想
- 当一个元素被加入集合时,通过K个散列函数将这个元素映射到一个位数组中的K个点,把它们置为1。
- 检索某个元素时,再通过这K个散列函数将这个元素映射,看看这些位置是不是都是1就能知道集合中这个元素存不存在。如果这些位置有任何一个0,则该元素一定不存在;如果都是1,则被检元素很可能在。
Bloom Filter 跟单哈希函数Bit-Map不同之处在于,Bloom Filter 使用了k个哈希函数,每个字符串跟k个bit对应。从而降低了冲突的概率。
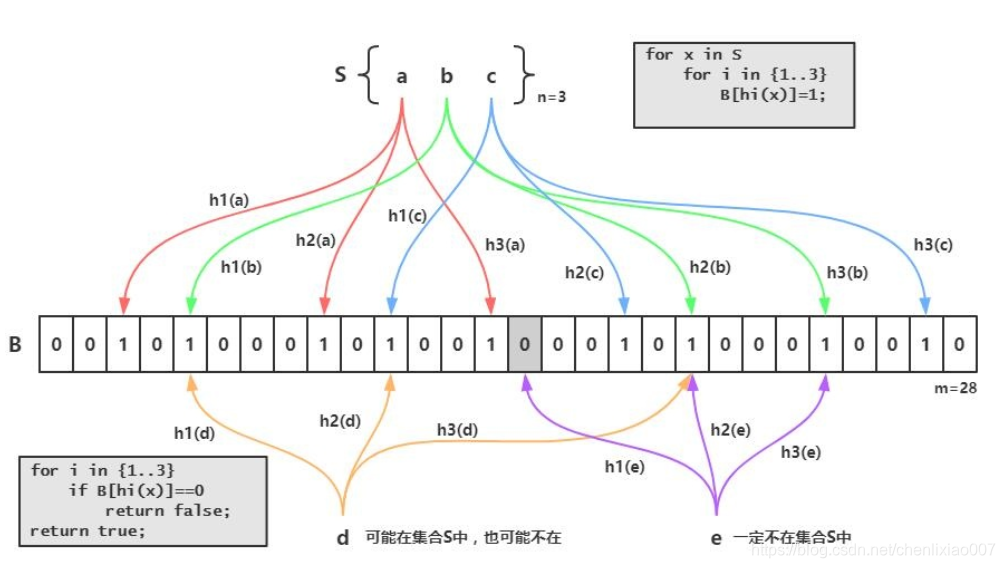
四:应用
- 有了布隆过滤器,在查询数据之前,先在布隆过滤器查询,如果查询不存在,就可以不用去查数据库了,从而避免了缓存穿透,减少了数据库压力。
- 具体应用例如,网页URL的去重,垃圾邮件的判别,集合重复元素的判别,查询加速(比如基于key-value的存储系统)等等。
五:优点
- 相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数。
- Hash函数相互之间没有关系,方便由硬件并行实现。
- 布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
六:缺点
- 误算率是其中之一。随着存入的元素数量增加,误算率随之增加。常见的补救办法是建立一个小的白名单,存储那些可能被误判的元素。但是如果元素数量太少,则使用散列表足矣。
- 删除困难。一个放入容器的元素映射到bit数组的k个位置上是1,删除的时候不能简单的直接置为0,可能会影响其他元素的判断,因为其他元素的映射也有可能在相同的位置置为1。可以采用Counting Bloom Filter。
七:实现
布隆过滤器有许多实现与优化,Guava中就提供了一种实现。Google Guava 提供的布隆过滤器的位数组存储在JVM内存中,故是单机版的,并且最大位长为int类型的最大值。
- 在使用bloom filter时,绕不过的两点是预估数据量n以及期望的误判率fpp,
- 在实现bloom filter时,绕不过的两点就是hash函数的选取以及bit数组的大小。
Bit数组大小选择
根据预估数据量n以及误判率fpp,bit数组大小的m的计算方式:
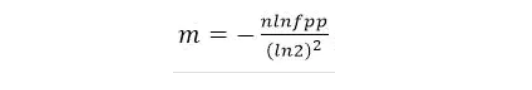
源码:
@VisibleForTesting
static long optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
哈希函数选择
哈希函数的选择对性能的影响应该是很大的,一个好的哈希函数要能近似等概率的将字符串映射到各个Bit。选择k个不同的哈希函数比较麻烦,一种简单的方法是选择一个哈希函数,然后送入k个不同的参数。
由预估数据量n以及bit数组长度m,可以得到一个hash函数的个数k:
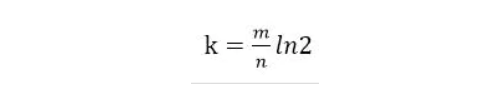
源码:
@VisibleForTesting
static int optimalNumOfHashFunctions(long n, long m) {
// (m / n) * log(2), but avoid truncation due to division!
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
八:实践
1:引入依赖
maven版本:
<!-- https://mvnrepository.com/artifact/com.google.guava/guava -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.2-jre</version>
</dependency>
Gradle版本:
// https://mvnrepository.com/artifact/com.google.guava/guava
compile group: 'com.google.guava', name: 'guava', version: '28.2-jre'
2:代码测试
package com.nobody;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
/**
* 测试布隆过滤器 Bloom Filter
*
* @author Μr.ηobοdy
*
* @date 2020-05-10
*
*/
public class TestBloomFilter {
private static int size = 1000000;
/**
* bloomFilter:位数组
* size:预计要插入多少数据
* fpp:容错率
*/
private static BloomFilter<Integer> bloomFilter =
BloomFilter.create(Funnels.integerFunnel(), size, 0.01);
public static void main(String[] args) {
// 将1至1000000这一百万个数映射到vu龙过滤器中
for (int i = 1; i <= size; i++) {
bloomFilter.put(i);
}
// 检查已在过滤器中的值,是否有匹配不上的
for (int i = 1; i <= size; i++) {
if (!bloomFilter.mightContain(i)) {
System.out.println("存在不匹配的值:" + i);
}
}
// 检查不在过滤器中的10000个值,是否有匹配上的
int matchCount = 0;
for (int i = size + 1; i <= size + 10000; i++) {
if (bloomFilter.mightContain(i)) {
matchCount++;
}
}
System.out.println("误判个数:" + matchCount);
}
}
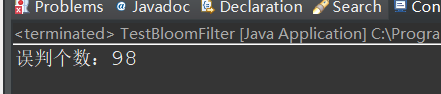
3:结果
当fpp的值为0.01时
当fpp的值为0.001时
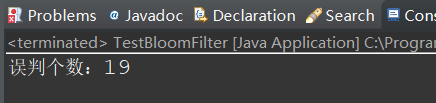
分析结果可知,误判率确实跟我们传入的容错率差不多,而且在布隆过滤器中的元素都匹配到了。
4:源码分析
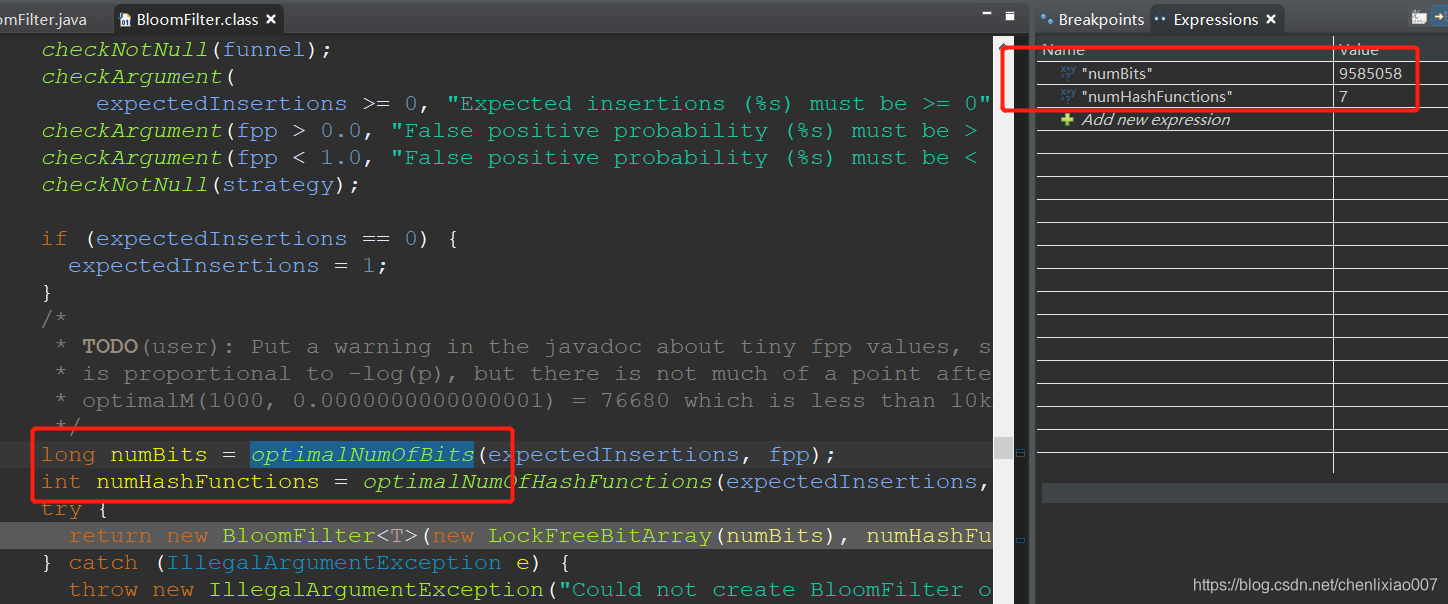
当fpp的值为0.01时,通过打断点可知,需要位数9585058个,hash函数个数为7个。
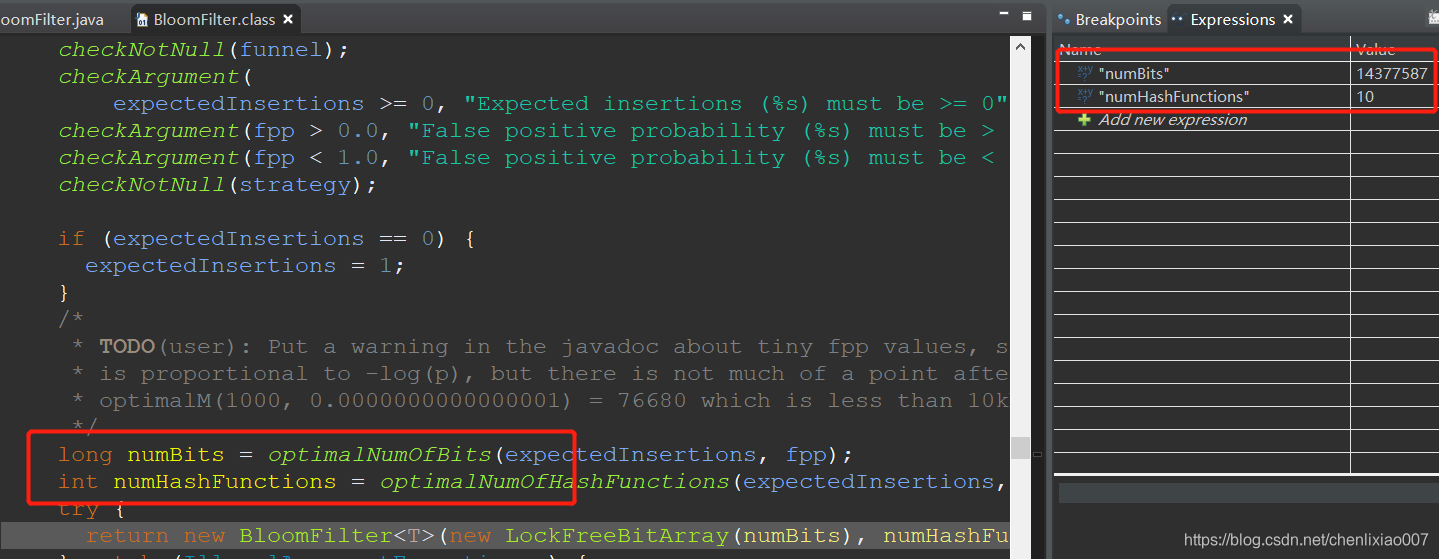
当fpp的值为0.001时,通过打断点可知,需要位数14377587个,hash函数个数为10个。
5:得出结论
- 容错率越大,所需空间和时间越小,容错率越小,所需空间和时间越大。
- 理论上存一百万个数,一个int是4字节32位,需要481000000=3200万位。如果使用HashMap去存,按HashMap50%的存储效率,需要6400万位。而布隆过滤器即使容错率fpp为0.001,也才需要14377587位,可以看出BloomFilter的存储空间很小。
九:扩展
假如有一台服务器,内存只有4GB,磁盘上有2个大文件,分别为文件A里面存储100亿个URL,文件B里面也存储100亿个URL。如何模糊找出两个文件的URL交集,如何精致找出两个文件的URL交集。
模糊交集:
借助布隆过滤器思想,先将一个文件的URL通过hash函数映射到bit数组中,这样大大减少了内存存储,再读取另一个文件URL,去bit数组中进行匹配。
精致交集:
对大文件进行hash拆分成小文件,例如拆分成1000个小文件(如果服务器内存更小,则可以拆分更多个更小的文件),例如文件A拆分为A1,A2,A3…An,文件B拆分为B1,B2,B3…Bn。而且通过相同的hash函数,相同的URL一定被映射到相同顺序的小文件中,例如A文件的www.baidu.com被映射到A1中,那B文件的www.baidu.com也一定被映射到B1文件中。最后再通过求相同下标的小文件(例如A1和B1)(A2和B2)的交集即可。