
有了前面Linux内核复用实现栈的基础,使用相同的思想实现队列,也是非常简单的。普通单链表复用实现队列,总会在出队或入队的时候有一个O(n)复杂度的操作,大多数采用增加两个变量,一个head,一个tail来将O(n)降成O(1)。但是在内核链表中,天然的双向循环链表,复用实现队列,无论出队还是入队,都是O(1)时间复杂度。
/* main.c */ #include <stdio.h> #include <stdlib.h> #include "queue.h" struct person { int age; struct list_head list; }; int main(int argc,char **argv) { int i; int num =5; struct person *p; struct person head; struct person *pos,*n; queue_creat(&head.list); p = (struct person *)malloc(sizeof(struct person )*num); for (i = 0;i < num;i++) { p->age = i*10; in_queue(&p->list,&head.list); p++; } printf("original==========>\n"); list_for_each_entry_safe(pos,n,&head.list,list) { printf("age = %d\n",pos->age); } printf("size = %d\n",get_queue_size(&head.list)); struct person test; test.age = 100; printf("out_queue %d\n",get_queue_head(pos,&head.list,list)->age); out_queue(&head.list); printf("out_queue %d\n",get_queue_head(pos,&head.list,list)->age); out_queue(&head.list); printf("in_queue %d\n",test.age); in_queue(&test.list,&head.list); printf("current==========>\n"); list_for_each_entry_safe(pos,n,&head.list,list) { printf("age = %d\n",pos->age); } printf("size = %d\n",get_queue_size(&head.list)); printf("all member out_queue\n"); list_for_each_entry_safe(pos,n,&head.list,list) { out_queue(&head.list); } printf("size = %d\n",get_queue_size(&head.list)); if (is_empt_queue(&head.list)) { printf("is_empt_queue\n"); } return 0; }
/* queue.c */ #include "queue.h" void queue_creat(struct list_head *list) { INIT_LIST_HEAD(list); } void in_queue(struct list_head *new, struct list_head *head) { list_add_tail(new,head); } void out_queue(struct list_head *head) { struct list_head *list = head->next; /* 保存链表的最后节点 */ list_del(head->next);/* 头删法 */ INIT_LIST_HEAD(list); /* 重新初始化删除的最后节点,使其指向自身 */ } int get_queue_size(struct list_head *head) { struct list_head *pos; int size = 0; if (head == NULL) { return -1; } list_for_each(pos,head) { size++; } return size; } bool is_empt_queue(struct list_head *head) { return list_empty(head); }
/* queue.h */ #ifndef _QUEUE_H_ #define _QUEUE_H_ #include <stdbool.h> #include "list.h" #define get_queue_head(pos, head, member) \ list_entry((head)->next, typeof(*pos), member) void queue_creat(struct list_head *list); void in_queue(struct list_head *new, struct list_head *head); void out_queue(struct list_head *entry); int get_queue_size(struct list_head *head); bool is_empt_queue(struct list_head *head); #endif /* _QUEUE_H_ */
运行结果:
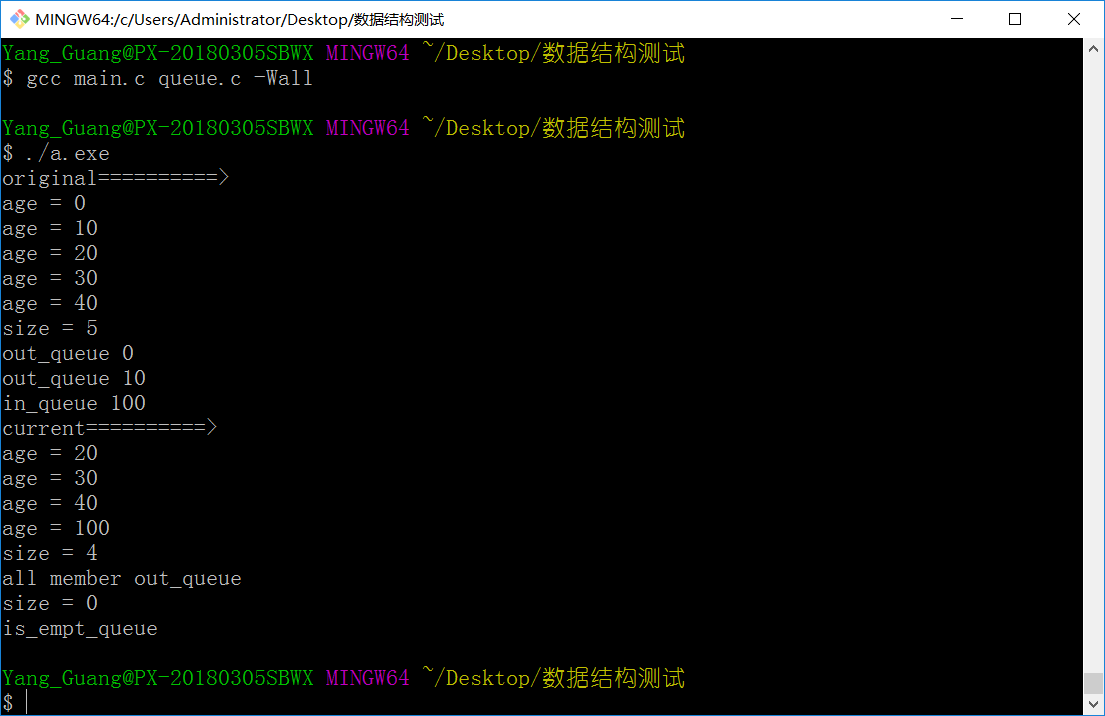
复用Linux内核链表实现队列,时间复杂可以很简单的实现O(1),当然,其中的遍历队列长度是O(n),不过这个在之前的随笔中也说到了,根据具体的应用场景,可以在入队的时候在头结点中size+1,出队的时候在头结点中size-1,获取队列大小的函数就可以直接返回size了,是可以很轻易做到O(1)的时间复杂度的。掌握了Linux内核链表,链表,栈和队列这样的数据结构,就可以很容易的实现复用,并且可以应用在实际项目中。