在Linux内核中,绝大对数的数据结构都是通过链表来连接的,所以链表在内核中起着异常重要的作用。在Linux中链表的使用是以一个非常巧妙的,非常有意思的方式来实现的。这种使用方式和我们平时在传统数据结构课程所教导的使用有很大的差异。先看一下最终使用时的结构。
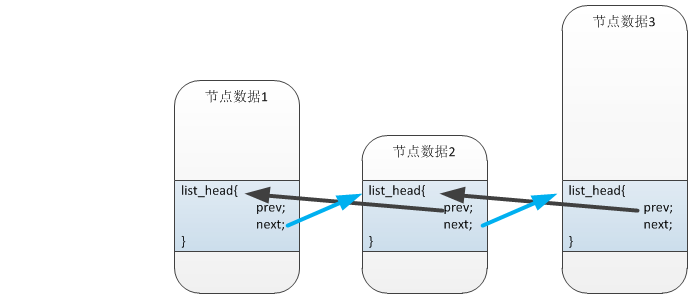
下面我先来分析一下linux内核对于链表的实现。
里面好多的操作我本人都是通过画图方式理解的。大家也可以尝试。
下面是双向链表的基本定义。
struct list_head {
struct list_head *next, *prev;
};链表的初始化,让链表的前后指向都指向自己。
#define LIST_HEAD_INIT(name) { &(name), &(name) } 定义一个名字为name的链表,并初始化该链表。
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
链表的初始化(和前面那个使用方法和作用完全一样,历史原因造成有两个的)
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}下面这个__list_add是在系统没有配置链表调试宏的情况下使用的,如果开启了调试宏__list_add就会使用debug_list.c里面的,
/* 在两个已知的两个连续的链表(next and prev)之间插入一个新的(new)链表
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
/* 这个操作只在内部使用,因为只有特定的人才能知道prev和next之前是不是相连接的,没其它链表 */
#ifndef CONFIG_DEBUG_LIST
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
#else
extern void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next);
#endif下面这个注释很清晰了,在head的后面增加一个元素new。看懂上面的__list_add,这个就超级容易了。
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks. /* 可以用来实现栈 */
*/
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}在head的前面增加一个元素。通常head是链表的头,而在双向链表中,头结点的前一个节点就是尾节点了,所以这个的命名结尾增加了一个tail,表明是在链表尾部插入。
/**
* list_add_tail - add a new entry
* @new: new entry to be added
* @head: list head to add it before
*
* Insert a new entry before the specified head.
* This is useful for implementing queues. /* 可以用来实现队列 */
*/
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}/*
* Delete a list entry by making the prev/next entries
* point to each other.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
/* 这个函数是一个内部函数(所有已__开头的函数都不应该被应用直接调用),其作用是删除prev和next之间的那个元素,具体使用和__list_add类似 */
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
prev->next = next;
}非调试版本的链表删除函数
/**
* list_del - deletes entry from list.
* @entry: the element to delete from the list.
* Note: list_empty() on entry does not return true after this, the entry is
* in an undefined state.
*/
#ifndef CONFIG_DEBUG_LIST
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next); //删除entry元素
entry->next = LIST_POISON1; //entry已经被删除了,其里面的next和prev赋值为无效指针
entry->prev = LIST_POISON2;
}
#else
extern void list_del(struct list_head *entry);
#endif注释很明了,即用new元素取代old元素
/**
* list_replace - replace old entry by new one
* @old : the element to be replaced
* @new : the new element to insert
*
* If @old was empty, it will be overwritten.
*/
static inline void list_replace(struct list_head *old,
struct list_head *new)
{
new->next = old->next; /* new的next指向后面节点 */
new->next->prev = new; /* 后面节点的prew指向新节点new */
new->prev = old->prev; /* new的prev指向前面节点 */
new->prev->next = new; /* 前面节点的next指向新节点new */
}看懂上面的替换函数,下面这个就很加单了,把替换出来的old节点重新初始化。防止它被乱用。
static inline void list_replace_init(struct list_head *old,
struct list_head *new)
{
list_replace(old, new);
INIT_LIST_HEAD(old);
}
注释很清晰,删除entry节点,同时把删除后的原entry初始化
/**
* list_del_init - deletes entry from list and reinitialize it.
* @entry: the element to delete from the list.
*/
static inline void list_del_init(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
INIT_LIST_HEAD(entry);
}
注释很明确,把list节点删除掉,之后把list节点加入到head的后面(这种操作通常是排序或其它操作用来交换连个元素使用)
/**
* list_move - delete from one list and add as another's head
* @list: the entry to move
* @head: the head that will precede our entry
*/
static inline void list_move(struct list_head *list, struct list_head *head)
{
__list_del(list->prev, list->next);
list_add(list, head);
}注释很明确,把list节点删除掉,之后把list节点加入到head的前面。在head是链表头的情况下,头节点的前面就是尾节点了,所以函数命名的尾部加了一个tail表示是把list节点移动到尾部位置。
/**
* list_move_tail - delete from one list and add as another's tail
* @list: the entry to move
* @head: the head that will follow our entry
*/
static inline void list_move_tail(struct list_head *list,
struct list_head *head)
{
__list_del(list->prev, list->next);
list_add_tail(list, head);
}判断list节点是不是,链表的尾节点(双向链表就是这么好判断)
/**
* list_is_last - tests whether @list is the last entry in list @head
* @list: the entry to test
* @head: the head of the list
*/
static inline int list_is_last(const struct list_head *list,
const struct list_head *head)
{
return list->next == head;
}判断链表是不是为空(还记得链表的初始化吗,指向自己的链表即为空链表)
/**
* list_empty - tests whether a list is empty
* @head: the list to test.
*/
static inline int list_empty(const struct list_head *head)
{
return head->next == head;
}
和上面的作用一样,检查链表是否为空,并且不是正在操作的的状态。不过这个操作必须要有同步技术的支持的时候在起作用,在单个cpu执行相关代码时才能其作用。
/**
* list_empty_careful - tests whether a list is empty and not being modified
* @head: the list to test
*
* Description:
* tests whether a list is empty _and_ checks that no other CPU might be
* in the process of modifying either member (next or prev)
*
* NOTE: using list_empty_careful() without synchronization
* can only be safe if the only activity that can happen
* to the list entry is list_del_init(). Eg. it cannot be used
* if another CPU could re-list_add() it.
*/
static inline int list_empty_careful(const struct list_head *head)
{
struct list_head *next = head->next;
return (next == head) && (next == head->prev);
}
旋转链表,具体是将链表的第一个节点放到链表的最后一个节点
/**
* list_rotate_left - rotate the list to the left
* @head: the head of the list
*/
static inline void list_rotate_left(struct list_head *head)
{
struct list_head *first;
if (!list_empty(head)) {
first = head->next;
list_move_tail(first, head);
}
}判断链表是不是只有一个元素。判断方法是,非空链表,且head的next节点和prev节点是同一个节点。
/**
* list_is_singular - tests whether a list has just one entry.
* @head: the list to test.
*/
static inline int list_is_singular(const struct list_head *head)
{
return !list_empty(head) && (head->next == head->prev);
}
这个是带__的,是一个内部函数,可以先看下面调用它的函数后再分析这个函数,这样会简单很多。
static inline void __list_cut_position(struct list_head *list,
struct list_head *head, struct list_head *entry)
{
struct list_head *new_first = entry->next; //先保存,否则会覆盖
list->next = head->next;
list->next->prev = list;
list->prev = entry;
entry->next = list;
head->next = new_first;
new_first->prev = head;
}链表剪切。
该操作的作用是把head这个链表里,从表头元素(除去head),到entry(包含)这个元素之间的所有元素放到list链表中。head头则与enrty后面的元素重新连接形成一个新的链表。这里要求entry必须输属于head这个链表的。如果head是一个空链表,则直接返回。如果entry就是head,则那直接初始化list(插入空节点)。
/**
* list_cut_position - cut a list into two
* @list: a new list to add all removed entries
* @head: a list with entries
* @entry: an entry within head, could be the head itself
* and if so we won't cut the list
*
* This helper moves the initial part of @head, up to and
* including @entry, from @head to @list. You should
* pass on @entry an element you know is on @head. @list
* should be an empty list or a list you do not care about
* losing its data.
*
*/
static inline void list_cut_position(struct list_head *list,
struct list_head *head, struct list_head *entry)
{
if (list_empty(head))
return;
if (list_is_singular(head) &&
(head->next != entry && head != entry))
return;
if (entry == head)
INIT_LIST_HEAD(list);
else
__list_cut_position(list, head, entry);
}
这个是带__的,是一个内部函数,可以先看下面调用它的函数后再分析这个函数,这样会简单很多。
内部使用必须保证传入的prev和next之前是相邻的两个节点。
static inline void __list_splice(const struct list_head *list,
struct list_head *prev,
struct list_head *next)
{
struct list_head *first = list->next;
struct list_head *last = list->prev;
first->prev = prev;
prev->next = first;
last->next = next;
next->prev = last;
}该函数的作用是把 两个链表合成为一个链表。
把head(head本身也会插入)插入到原来list链表的头节点后面。【也可以理解为把list插入到head里面,道理一样】
/**
* list_splice - join two lists, this is designed for stacks
* @list: the new list to add.
* @head: the place to add it in the first list.
*/
static inline void list_splice(const struct list_head *list,
struct list_head *head)
{
if (!list_empty(list))
__list_splice(list, head, head->next);
}和前一个的作用类似,只不过把head放到了list的头结点前面去了。【也可以理解为把list插入到head里面,道理一样】
/**
* list_splice_tail - join two lists, each list being a queue
* @list: the new list to add.
* @head: the place to add it in the first list.
*/
static inline void list_splice_tail(struct list_head *list,
struct list_head *head)
{
if (!list_empty(list))
__list_splice(list, head->prev, head);
}
和前面多了一步,就是把list初始化一下,之后用head访问就可以了。(不然有两个头节点了【list,head】)
/**
* list_splice_init - join two lists and reinitialise the emptied list.
* @list: the new list to add.
* @head: the place to add it in the first list.
*
* The list at @list is reinitialised
*/
static inline void list_splice_init(struct list_head *list,
struct list_head *head)
{
if (!list_empty(list)) {
__list_splice(list, head, head->next);
INIT_LIST_HEAD(list);
}
}和前面一样,只不过是尾插发加初始化。
/**
* list_splice_tail_init - join two lists and reinitialise the emptied list
* @list: the new list to add.
* @head: the place to add it in the first list.
*
* Each of the lists is a queue.
* The list at @list is reinitialised
*/
static inline void list_splice_tail_init(struct list_head *list,
struct list_head *head)
{
if (!list_empty(list)) {
__list_splice(list, head->prev, head);
INIT_LIST_HEAD(list);
}
}
container_of宏的作用是通过结构体内某个成员变量的地址和该变量名,以及结构体类型。找到该结构体变量的地址。
container_of宏我在platform驱动模型使用总结的结尾有说到,不动的可以去看一下。
这个是内核链表的使用精髓,必须要一眼看到就猜到要做什么。
https://mp.csdn.net/postedit/81145148
/**
* list_entry - get the struct for this entry
* @ptr: the &struct list_head pointer.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_struct within the struct.
*/
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
看懂上面的,这个就很简单了。找到链表下一个元素的地址(注意元素已经不是head_list了,而是包含head_list的一个结构体了,这样head_list可以适用各种链表的构成【精髓】,这也是前面那么多链表操作没有带待具体数据的原因。)。
/**
* list_first_entry - get the first element from a list
* @ptr: the list head to take the element from.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_struct within the struct.
*
* Note, that list is expected to be not empty.
*/
#define list_first_entry(ptr, type, member) \
list_entry((ptr)->next, type, member)从这后面的要特备注意看注释,因为可能前一个和后一个里面的操作参数命名一样,但意义不一样。
下面这个函数是链表的遍历。注意,该for循环后面没有分号。所以使用的话,要注意。
pos被初始化为head->next即第一个有效元素。
里面通过逗号表达式,在逗号前面定义了一个prefetch指定,这个指令是把数据从内存或磁盘预期到高速缓冲区,方便快递遍历。该指令的使用可以查看gcc相关文档。
/**
* list_for_each - iterate over a list
* @pos: the &struct list_head to use as a loop cursor.
* @head: the head for your list.
*/
#define list_for_each(pos, head) \
for (pos = (head)->next; prefetch(pos->next), pos != (head); \
pos = pos->next)
另一个版本的遍历函数,没有加prefetch指令优化。
/**
* __list_for_each - iterate over a list
* @pos: the &struct list_head to use as a loop cursor.
* @head: the head for your list.
*
* This variant differs from list_for_each() in that it's the
* simplest possible list iteration code, no prefetching is done.
* Use this for code that knows the list to be very short (empty
* or 1 entry) most of the time.
*/
#define __list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)从面往后遍历。和前面的遍历顺序相反。
/**
* list_for_each_prev - iterate over a list backwards
* @pos: the &struct list_head to use as a loop cursor.
* @head: the head for your list.
*/
#define list_for_each_prev(pos, head) \
for (pos = (head)->prev; prefetch(pos->prev), pos != (head); \
pos = pos->prev)遍历链表,和前面那些就多了一个保存pos的后一个元素数据在n中。可以用来在删除pos后,方便接续等。
/**
* list_for_each_safe - iterate over a list safe against removal of list entry
* @pos: the &struct list_head to use as a loop cursor.
* @n: another &struct list_head to use as temporary storage
* @head: the head for your list.
*/
#define list_for_each_safe(pos, n, head) \
for (pos = (head)->next, n = pos->next; pos != (head); \
pos = n, n = pos->next)
反向遍历链表,保存了pos的前一个元素在n中,方便某些时候使用。
/**
* list_for_each_prev_safe - iterate over a list backwards safe against removal of list entry
* @pos: the &struct list_head to use as a loop cursor.
* @n: another &struct list_head to use as temporary storage
* @head: the head for your list.
*/
#define list_for_each_prev_safe(pos, n, head) \
for (pos = (head)->prev, n = pos->prev; \
prefetch(pos->prev), pos != (head); \
pos = n, n = pos->prev)真正的遍历带有数据的链表操作。
/**
* list_for_each_entry - iterate over list of given type
* @pos: the type * to use as a loop cursor. 此时的pos的类型和前面的不一样了,是包含head_list类型结构体的类型
* @head: the head for your list.
* @member: the name of the list_struct within the struct. 结构体内成员head_list类型变量的名字
*/
#define list_for_each_entry(pos, head, member) \
for (pos = list_entry((head)->next, typeof(*pos), member); \
prefetch(pos->member.next), &pos->member != (head); \
pos = list_entry(pos->member.next, typeof(*pos), member))
和上面那个类似,只不过是反方向的遍历带有数据的链表。
/**
* list_for_each_entry_reverse - iterate backwards over list of given type.
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*/
#define list_for_each_entry_reverse(pos, head, member) \
for (pos = list_entry((head)->prev, typeof(*pos), member); \
prefetch(pos->member.prev), &pos->member != (head); \
pos = list_entry(pos->member.prev, typeof(*pos), member))
判断pos是不是为空,为空则返回返回head指针所在结构体的地址,不为空则返回自己本身。
细心的朋友注意到了,在pos为true的时候,返回项里面没有任何数据,这个需要自己在 机器上实践了。我的确实是返回的pos本身,这个是内核中编写的小技巧吧,但不建议使用。
/**
* list_prepare_entry - prepare a pos entry for use in list_for_each_entry_continue()
* @pos: the type * to use as a start point
* @head: the head of the list
* @member: the name of the list_struct within the struct.
*
* Prepares a pos entry for use as a start point in list_for_each_entry_continue().
*/
#define list_prepare_entry(pos, head, member) \
((pos) ? : list_entry(head, typeof(*pos), member))下面两个函数和前面的遍历其实类似。只不过前面的是从head的next和prev开始遍历。
而下面的两个则是pos的next和prev开始遍历,
/**
* list_for_each_entry_continue - continue iteration over list of given type
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*
* Continue to iterate over list of given type, continuing after
* the current position.
*/
#define list_for_each_entry_continue(pos, head, member) \
for (pos = list_entry(pos->member.next, typeof(*pos), member); \
prefetch(pos->member.next), &pos->member != (head); \
pos = list_entry(pos->member.next, typeof(*pos), member))
/**
* list_for_each_entry_continue_reverse - iterate backwards from the given point
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*
* Start to iterate over list of given type backwards, continuing after
* the current position.
*/
#define list_for_each_entry_continue_reverse(pos, head, member) \
for (pos = list_entry(pos->member.prev, typeof(*pos), member); \
prefetch(pos->member.prev), &pos->member != (head); \
pos = list_entry(pos->member.prev, typeof(*pos), member))
从pos处向后遍历。
/**
* list_for_each_entry_from - iterate over list of given type from the current point
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*
* Iterate over list of given type, continuing from current position.
*/
#define list_for_each_entry_from(pos, head, member) \
for (; prefetch(pos->member.next), &pos->member != (head); \
pos = list_entry(pos->member.next, typeof(*pos), member))
遍历整个链表。从head的next开始遍历pos类型元素的链表,并且用pos保存n前一个链表的地址。
/**
* list_for_each_entry_safe - iterate over list of given type safe against removal of list entry
* @pos: the type * to use as a loop cursor.
* @n: another type * to use as temporary storage
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*/
#define list_for_each_entry_safe(pos, n, head, member) \
for (pos = list_entry((head)->next, typeof(*pos), member), \
n = list_entry(pos->member.next, typeof(*pos), member); \
&pos->member != (head); \
pos = n, n = list_entry(n->member.next, typeof(*n), member))
从pos的下一个开始遍历链表,遍历的范围是pos+1到 head。而head到pos的位置则没遍历。
/**
* list_for_each_entry_safe_continue - continue list iteration safe against removal
* @pos: the type * to use as a loop cursor.
* @n: another type * to use as temporary storage
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*
* Iterate over list of given type, continuing after current point,
* safe against removal of list entry.
*/
#define list_for_each_entry_safe_continue(pos, n, head, member) \
for (pos = list_entry(pos->member.next, typeof(*pos), member), \
n = list_entry(pos->member.next, typeof(*pos), member); \
&pos->member != (head); \
pos = n, n = list_entry(n->member.next, typeof(*n), member))
从pos的开始遍历链表,遍历的范围是pos到 head。而head到pos-1的位置则没遍历。上面的版本已经没法访问pos本身,而该宏还可以访问到pos的数据。
/**
* list_for_each_entry_safe_from - iterate over list from current point safe against removal
* @pos: the type * to use as a loop cursor.
* @n: another type * to use as temporary storage
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*
* Iterate over list of given type from current point, safe against
* removal of list entry.
*/
#define list_for_each_entry_safe_from(pos, n, head, member) \
for (n = list_entry(pos->member.next, typeof(*pos), member); \
&pos->member != (head); \
pos = n, n = list_entry(n->member.next, typeof(*n), member))
反向从head的prev开始遍历整个链表。
/**
* list_for_each_entry_safe_reverse - iterate backwards over list safe against removal
* @pos: the type * to use as a loop cursor.
* @n: another type * to use as temporary storage
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*
* Iterate backwards over list of given type, safe against removal
* of list entry.
*/
#define list_for_each_entry_safe_reverse(pos, n, head, member) \
for (pos = list_entry((head)->prev, typeof(*pos), member), \
n = list_entry(pos->member.prev, typeof(*pos), member); \
&pos->member != (head); \
pos = n, n = list_entry(n->member.prev, typeof(*n), member))不经常使用的一个。把pos所在结构体的首地址赋值给n
/**
* list_safe_reset_next - reset a stale list_for_each_entry_safe loop
* @pos: the loop cursor used in the list_for_each_entry_safe loop
* @n: temporary storage used in list_for_each_entry_safe
* @member: the name of the list_struct within the struct.
*
* list_safe_reset_next is not safe to use in general if the list may be
* modified concurrently (eg. the lock is dropped in the loop body). An
* exception to this is if the cursor element (pos) is pinned in the list,
* and list_safe_reset_next is called after re-taking the lock and before
* completing the current iteration of the loop body.
*/
#define list_safe_reset_next(pos, n, member) \
n = list_entry(pos->member.next, typeof(*pos), member)
写得有点长了,好累。有时间再把单向的哈希表分析一下。