客户流失是指客户终止与企业的服务合同或转向其他公司提供服务,客户流失分析事宜客户的历史通话行为数据,客户的基础信息,客户拥有的产品信息为基础,通过试单的数据挖掘手段,综合考虑流失的特点和与之相关的多种因素,从而发现与流失密切相关的特征,在此基础上简历可以在一定时间范围预测用户流失倾向的预测模型,为相关业务部门提供有流失倾向的用户名单和这些客户的为特征,以便制定恰当的营销策略,采取针对性措施,挽留客户
需解决的问题:
-
哪些客户可能流失
-
客户可能在何时流失
-
客户为什么流失
-
流失的影响
-
制定的保留措施
客户流失的类型
-
公司内客户转移:不同业务之间的转换,这种情况对于公司而言,客户并没有流失
-
客户被动流失:金融服务商主动终止与客户之间的关系。主要是由于在客户的开发过程中忽略了和客户质量造成
-
客户主动流失:
-
第一种情况:客户离开了金融行业
-
第二种情况:客户转移到另一个金融服务商
扫描二维码关注公众号,回复: 7812010 查看本文章
-
客户主动流失的原因主要是客户认为公司不能提供他所期待的价值,即公司为客户提供的服务价值低于另一家服务商。这可能是客户对公司的业务和服务不满意,也可能是客户仅仅想尝试一下别家公司提供而本公司未提供的新业务。这种客户流失形式是研究的主要内容.
如何进行客户流失分析
1 . 定义预测目标,这是建立在对运营商的商业规划和业务流程的准确把握上,
2 . 针对客户流失的不同种类分别定义预测目标,进而区别处理。
在客户流失分析中有俩个核心变量:财务问题/非财务问题,主动流失/被动流失。对不同的流失客户按该原则加以区分,进而制定不同的流失标准。企业真正要保留的是非财务原因被动流失的客户。
哪些客户可能流失
将所有的客户分为俩类,流失与不流失,选择适合的流失客户和为流失客户的属性数据组成训练数据集,包括客户的历史通话行为数据,客户的基础信息,客户拥有的产品信息等,Clementine 提供人工神经网络、决策树、Logistic回归等模型用于建立客户流失的分类模型。
关于流失用户特征的分析,是一个属性约减和规则发现问题。Clementine 提供关联分析方法,可以发现怎样的规则导致客户流失。也可以利用 Clementine 的决策树方法,发现与目标变量(是否流失),关系最为紧密的用户属性。
客户可能在何时流失
生存分析可以解决这类问题。生存分析不仅可以告诉分析人员在某种情况下,客户可能流失,而且还可以告诉分析人员,在这种情况下,客户在何时会流失。生存分析以客户流失的时间为响应变量进行建模,以客户的人口统计学特征和行为特征为自变量,对每个客户计算出初始生存率,随着时间和客户行为的变化,客户的生存率也发生变化,当生存率达到一定的阈值后,客户就可能流失。
流失的影响
流失对客户自身的影响时,主要可以考虑客户的流失成本和客户流失的受益分析。客户流失成本可以考虑流失带来的人际关系损失等因素,通过归纳客户的通话特征来表征。减少客户流失的一个手段就是增加客户的流失成本。客户流失的受益分析就是判断客户流失的动机,是价格因素还是为了追求更好的服务等。这方面内容丰富,需作具体分析。 分析客户流失对公司的影响时,不仅要着眼于对收入的影响,而且要考虑其它方面的影响。单个的客户流失对公司的影响可能是微不足道的,此时需要研究流失客户群对公司收入或业务的影响。这时候可能需要对流失客户进行聚类分析和关联分析,归纳客户流失的原因,有针对性的制定防止客户流失的措施。
在预测出有较大流失可能性的客户后,分析该客户流失对公司的影响。评估保留客户后的收益和保留客户的成本。如果收益大于成本,客户是高价值客户,则采取措施对其进行保留。至于低价值客户,不妨任其流失甚至劝其流失。
案例:
数据说明
选取一定数量的客户(包括流失的和未流失的),选择客户属性,包括客户资料、客户账户信息等。利用直方图、分布图来初步确定哪些因素可能影响客户流失。所选取的数据属性包括:
(1)客户号;(2)储蓄账户余额;(3)活期账户余额;(4)投资账户余额;(5)日均交易次数;(6)信用卡支付方式;(7)是否有抵押贷款;(8)是否有赊账额度;(9)客户年龄;(10)客户性别;(11)客户婚姻状况;(12)客户孩子数目;
(13)客户年收入;
(14)客户是否有一辆以上汽车;
(15)客户流失状态
其中客户流失状态有三种属性:(1)被动流失;(2)主动流失,这是分析中特别关注的一类客户;(3)未流失。
在开发这个应用之前,企业将所有现有的客户归到上述的三个类别中。同时按照常规,所有的人口统计信息(也就是从客户年龄到客户是否有一辆以上汽车)每六个月更新一次,而交易信息(从储蓄账户余额到是否有赊账额度)则是实时更新的。为了让预测模型能预先进行指示以便采取补救措施,在目标变量(因变量)和输入变量(自变量)之间设定了 6个月的延迟。也就是说,输入变量的采集六个月后再将客户流失状态分类;因此该模型提早6 个月预测客户流失在开发这个应用之前,企业 将所有现有的客户归到上述的三个类别中。同时按照常规,所有的人口统计信息(也就是从客户年龄到客户是否有一辆以上汽车)每六个月更新一次,而交易信息(从储蓄账户余额到是否有赊账额度)则是实时更新的。为了让预测模型能预先进行指示以便采取补救措施,在目标变量(因变量)和输入变量(自变量)之间设定了 6个月的延迟。也就是说,输入变量的采集六个月后再将客户流失状态分类;因此该模型提早6 个月预测客户流失。
数据描述及图表分析
在数据理解中,可以利用描述及可视化来帮助探索模式、趋势和关系。Clementine 中数据理解的数据流图,包括:使用数据审核,统计分析,网络图,直方图,两步聚类,关联分析,查看数据属性之间的关系


数据审核结果。可以很清楚地了解 14 个数据字段的基本情况。如数据类型、最大最小值、平均值、标准差、偏度、是否唯一、有效记录个数等。


使用绘图和直方图节点将数据可视化就产生了客户收入和年龄图及日均交易数的直方图,将可视化的结果与目标变量联系起来,可以看出客户流失状态包含在不同的图表中。例如,客户的离中趋势,男性和女性客户的被动流失和主动流失以及每个级别的日均交易次数都包含在了图表中。这种对关系的初步评估对于建模是很有用的。更重要的是,结果表明主动流失在女性客户和不太活跃的客户中较为多见。


网状图表明了客户性别,客户婚姻状况,信用卡支付方式,客户流失状态之间的联系。较强的关系由较粗的线表示。那些在一定标准(由用户定义)之下的联系则不包括在图中(例如在被动流失和选中的一些输入变量之间)。网状图表明现有客户(即非流动者)更多的是那些已婚男性,那些用其它账户进行信用卡支付的人。要注意的是,前面已经提到过,客户流失状态滞后输入变量六个月。
关联分析及聚类的结果为了进一步了解房贷客户可以使用聚类
使用双步聚类节点获得的结果。如图所示,客户似乎分为七种自然的聚类。所产生的聚类特征可用来定义和理解每个聚类以及聚类间的区别。例如,我们比较聚类 1 和聚类 4,聚类 1 中包含的是较年轻并绝大多数已婚(92.2%),并且年收入较高的女性。而聚类 4 中包含的是较年长(平均要比 1 中大 5 岁),59.8%已婚,年收入较低(平均要比 1 中低 4000 美元)的男性。聚类的结果对于市场定位和分割研究是非常有用的,但是对于预测建模的作用则没这么明显


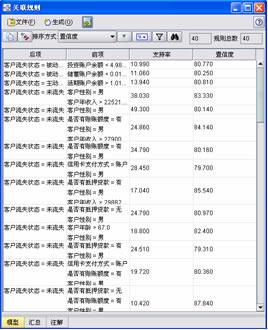
本例使用关联分析来制订规则,寻找输入变量和目标变量间的关系。这些规则不仅对发现模式、关系和趋势很重要,对于预测建模(例如决定采用/不采用哪些输入变量)也很重要。我们使用 Clementine 的 GRI(广义规则归纳)节点来进行联合分析,下图。其中,第一条联合分析规则表明,有 156 名(或 11.0%的)房贷客户的投资账户余额低于 4988 美元,其中 81.0%是被动流失的。同样,第三条规则表明有 198 名(或 13.9%的)房贷客户的活期账户余额超过 1017 美元,其中 81.0%是主动流失的。其它的规则可以类似地进行理解。这些规则表明交易和人口统计信息是如何与客户流失状态联系起来的。要注意的是,客户流失状态滞后输入变量六个月。

数据准备 根据数据理解的结果准备建模用的数据,包括数据选择、新属性的派生,数据合并等。在本例中,利用Clementine 进行数据准备的数据流图如图所示。通过分裂节点,给数据集添加一个新的标志属性。该标志属性是 0-16 之间的随机数。然后再根据标志属性值(<4和)=4),利用过滤节点,将原来的数据样本分成训练集(约占 75%)和测试集(约占 25%)


建立模型及评估
预测建模是本例中最重要的分析,神经网络和决策树尤其适用于对房贷客户的流失建模。
使用 Clementine 训练神经网络模型和建决策树功能得到的神经网络和决策树的结果。
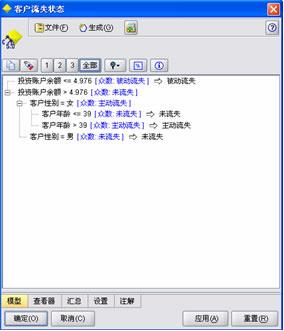



决策树模型中有 4 个终端节点和仅仅 3 个重要的输入变量(按照重要性降序排列):投资账户余额、客户性别和客户年龄。神经网络模型在输入层、隐藏层和输出层分别有 15 个、5 个和 3 个神经元。此外,最终要的 5 个输入变量是(按照重要性降序排列):活期账户余额、客户孩子数目、储蓄账户余额、投资账户余额和客户婚姻状况。Logistic 回归模型统计有效,卡方检验的 p 值为 1.000,表明数据吻合得很好。此外,下列输入变量在统计时在 0.05 的有效水平上预测客户流失状态也统计有效:储蓄账户余额 c(p 值=0.000)、活期账户余额(p 值=0.000)、客户年龄(p 值=0.002)、客户年收入(p 值=0.033)及客户性别(p 值=0.000)。
从用评估图节点产生的提升表中可以看出每个预测模型都是有效的,如下图所示(从左至右分别为 Logistic 回归、决策树和神经网络)。提升表中绘制的是累积提升值与样本百分比的关系(在这里是构造/培训样本)。基准值(即评估每个模型的底限)是 1,它表示当从样本中随机抽取记录的百分点时能成功地“击中”现有客户。提示值衡量的是当来自数据中的某一记录是一个现有客户的降序预测概率能被百分点反映时,预测模型“击中”现有客户的成功可能性(准确度)有多高。如图 (左)所示,每个模型的提升值均大于 1,在 100%时收敛于 1。由于每个预测模型都能以有效精度预测目标变量(起码对于现有客户和非现有客户之间的关系),因此我们可以说它们都是有效的。


模型部署
本例中,决策树模型不仅精度最高,也容易理解。结果表明,那些 39 岁以上,在投资帐户中余额超过 4976 美元的女性更可能主动流失。在 Clementine 中部署模型的数据流图如图所示。运行数据流后,Clementine 自动将结果存储在逗号分隔的文件中。


最后需要指出的是在本例中,模型的总体分类精确率是简化计算的。在实际使用中,一般还需要考虑误分类及其相关成本,还有流失客户和非流失客户在样本和总体中的相对比重。