算法与数据结构索引
https://www.cnblogs.com/kaituorensheng/p/3522017.html?spm=a2c4e.10696291.0.0.8d4119a4SmSgqO
判断一棵树是否为另一棵树的子树
https://www.cnblogs.com/anzhsoft/p/3602981.html
https://blog.csdn.net/qq_42673507/article/details/85260617
T1是一棵含有几百万个节点的树,T2含有几百个节点。判断T2是否是T1 的子树。
首先考虑小数据量的情况,可以根据树的前序和中序遍历所得的字符串,来通过判断T2生成的字符串是否是T1字符串的子串,来判断T2是否是T1的子树。假设T1的节点数为N,T2的节点数为M。遍历两棵树算法时间复杂性是O(N + M), 判断字符串是否为另一个字符串的子串的复杂性也是O( N + M)(比如使用KMP算法)。所需要的空间也是O(N + M)。
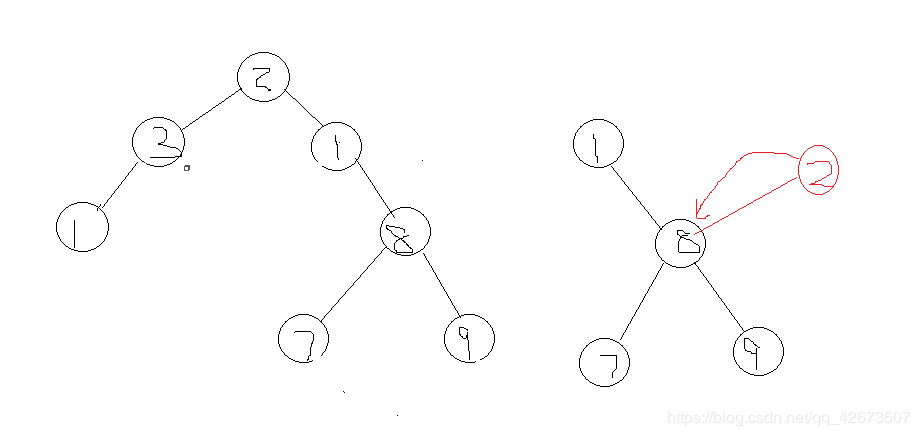
这里有一个问题需要注意:对于左节点或者右节点为null的情况,需要在字符串中插入特殊字符表示。否则对于下面这种情形将会判断错误:

因此如果插入特殊字符,上述两棵树的中序和前序遍历的结果是相同的。
由于本例有几百万的节点,需要占用O(N + M)的内存。
如果换一种思路,就是遍历T1,每当T1的某个节点与T2的根节点值相同时,就判断两棵子树是否相同。这个算法的复杂度是O(N*M)。我们再仔细思考一下。因为只有在节点值与T2的根节点值相同才会调用O(M)。假设有K次这种情况,那么算法的复杂度就是O(N + K*M)。下面是代码实现:
struct TreeNode{
TreeNode *leftChild;
TreeNode *rightChild;
int data;
};
// check sub tree n1 == sub tree n2
bool checkSubTree(const TreeNode* n1, const TreeNode* n2){
if( n1 == nullptr && n2 == nullptr )
return true;
if( n1 == nullptr || n2 == nullptr )
return false;
if( n1->data != n2->data )
return false;
return checkSubTree(n1->leftChild, n2->leftChild) && checkSubTree(n1->rightChild, n2->rightChild);
}
bool subTree(const TreeNode *n1, const TreeNode *n2){
if( n1 == nullptr){
return false; // the bigger tree is empty, so t2 is not subtree of t1
}
if( n1->data == n2->data){
if( checkSubTree(n1, n2))
return true;
}
return subTree(n1->leftChild, n2) || subTree(n2->rightChild, n2);
}
对于上面讨论的2种解法,哪种解法比较好呢?其实有必要好好讨论一番:
1)方法一会占用O(N + M)的内存,而另外一种解法只会占用O(logN + logM)的内存(递归的栈内存)。当考虑scalability扩展性时,内存使用的多寡是个很重要的因素。
2)方法一的时间复杂度为O(N + M),方法二最差的时间复杂度是O(N*M)。所以要通过工程实践或者是历史数据看一下哪种方法更优。当然了,方法二也可能会很早发现两棵树的不同,早早的退出了checkSubTree。
总的来说,在空间使用上,方法二更好。在时间上,需要通过实际数据来验证。
T1是一棵含有几百万个节点的树,T2含有几百个节点。判断T2是否是T1 的子树。
首先考虑小数据量的情况,可以根据树的前序和中序遍历所得的字符串,来通过判断T2生成的字符串是否是T1字符串的子串,来判断T2是否是T1的子树。假设T1的节点数为N,T2的节点数为M。遍历两棵树算法时间复杂性是O(N + M), 判断字符串是否为另一个字符串的子串的复杂性也是O( N + M)(比如使用KMP算法)。所需要的空间也是O(N + M)。
这里有一个问题需要注意:对于左节点或者右节点为null的情况,需要在字符串中插入特殊字符表示。否则对于下面这种情形将会判断错误:
因此如果插入特殊字符,上述两棵树的中序和前序遍历的结果是相同的。
由于本例有几百万的节点,需要占用O(N + M)的内存。
如果换一种思路,就是遍历T1,每当T1的某个节点与T2的根节点值相同时,就判断两棵子树是否相同。这个算法的复杂度是O(N*M)。我们再仔细思考一下。因为只有在节点值与T2的根节点值相同才会调用O(M)。假设有K次这种情况,那么算法的复杂度就是O(N + K*M)。下面是代码实现:
struct TreeNode{
TreeNode *leftChild;
TreeNode *rightChild;
int data;
};
// check sub tree n1 == sub tree n2
bool checkSubTree(const TreeNode* n1, const TreeNode* n2){
if( n1 == nullptr && n2 == nullptr )
return true;
if( n1 == nullptr || n2 == nullptr )
return false;
if( n1->data != n2->data )
return false;
return checkSubTree(n1->leftChild, n2->leftChild) && checkSubTree(n1->rightChild, n2->rightChild);
}
bool subTree(const TreeNode *n1, const TreeNode *n2){
if( n1 == nullptr){
return false; // the bigger tree is empty, so t2 is not subtree of t1
}
if( n1->data == n2->data){
if( checkSubTree(n1, n2))
return true;
}
return subTree(n1->leftChild, n2) || subTree(n2->rightChild, n2);
}
对于上面讨论的2种解法,哪种解法比较好呢?其实有必要好好讨论一番:
1)方法一会占用O(N + M)的内存,而另外一种解法只会占用O(logN + logM)的内存(递归的栈内存)。当考虑scalability扩展性时,内存使用的多寡是个很重要的因素。
2)方法一的时间复杂度为O(N + M),方法二最差的时间复杂度是O(N*M)。所以要通过工程实践或者是历史数据看一下哪种方法更优。当然了,方法二也可能会很早发现两棵树的不同,早早的退出了checkSubTree。
总的来说,在空间使用上,方法二更好。在时间上,需要通过实际数据来验证。