大家好,我是小木,小木课堂又开课了o(∩_∩)o 。
哈哈,今天我要讲的是卷积神经网络(CNN Convolutional Neural Network)。看这个名字,卷积神经网络(CNN),好TMD高大上啊,听起来挺唬人的,其实也就那么回事儿,当初我讲过深度信念神经网络(DBN),也讲过生成式对抗网络(GAN),这都是深度学习中的算法。这些东西说实话差不了多少,都是BP的改进。要说CNN是谁发明的,这里的争议比较大,我就不说了。它能干啥呢,很多呀,比如说它可以做图像识别啦、语音识别啦。
其实,卷积神经网络CNN说白了也就是在BP神经网络中加入卷积运算的一种处理数据的方法罢了。
什么叫卷积运算呢?
问的好!我现在就来给大家讲一下:
我们假设有5个原始数据,分别是:
X1 |
X2 |
X3 |
X4 |
X5 |
但我们嫌这5个数据不爽,我们不想要,于是我们创造了两个滤波器H1、H2。
因为我们不想要这5个数据,所以我们要让这些数据与滤波器做一些运算得到更好的数据。这样的运算就叫做卷积。

那么怎么运算呢,如果我们新得到的数据的数量仍然保持5个不变,
那么我们第一步应该把原始数据的开头和末尾加上0变成:
0 |
X1 |
X2 |
X3 |
X4 |
X5 |
0 |
第二步,我们让H1和H2分别和0,X1做乘积得到H1*0、H2*X1,并作和得到D1=H1*0+H2*X1=H2*X1。
第三步,我们把H1和H2往右移动一个格子,分别和X1、X2做乘积,然后加和,得到D2=H1*X1+H2*X2。
同理,把H1和H2再往右移动一个格子,分别和X2、X3做乘积,然后加和,得到D3=H1*X2+H2*X3。以此类推得到D4=H1*X3+H2*X4;D5=H1*X4+H2*X5;D6=H1*X5+H2*0=H1*X5。
这样卷积运算就完成了,我们得到了D1~D6的6个数据。如果大家看文字还是很懵B,那么请看下面的图就一目了然了:
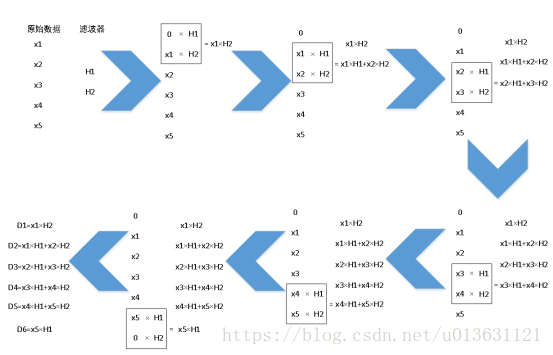
图1:卷积运算
卷积我们讲完了,现在我们再看卷积运算时候,是不是就像当范伟坐在轮椅上时候回答赵本山问题的感觉呀?是的话继续往下看。
除了卷积运算以外,CNN中还有一种算法叫做池化(pooling),听名字感觉太TMD的坑了,范伟又从轮椅上面站起来了。其实别怕,这个更是一个四岁小孩儿的脑筋急转弯,一只纸老虎。
刚才不是得到了6个D1~D6了么,对,如下:
D1 |
D2 |
D3 |
D4 |
D5 |
D6 |
池化是啥意思呢,就是筛选数据,怎么筛选呢,我们要定义一个叫做采样器的东西,这个听起来又213了,不知道是啥,别管它是啥,我们先假定采样器的参数值a为2可以吧。
那么,我们把6个数据分为6/a=6/2=3组,分组规则是从左到右依次读取:第一组是[D1,D2],第二组是[D3,D4],第三组是[D4,D5]。
然后我们选择每组最大的数据,假设第一组是D2>D1,第二组是D4>D3,第三组是D6>D5。那么我们舍弃D1,D3,D5保留三个最大的数据D2,D4,D6。
D2 |
D4 |
D6 |
这样的过程我们就叫做池化。纸老虎吧,名字高大上其实都是坑货,如果还是不清晰,看下面这个图。

图2:池化
现在呢,卷积池化的概念讲解完成了,如果像当范伟坐在轮椅上时候回答问题的感觉,那么我们就再继续。
我们讲完两个概念之后,就可以进入卷积神经网络CNN的讲解过程中了,一般别人都是开始就讲解的是正向传播。我不这样做,在讲正向传播之前,我还是要继续说一下我们放入卷积神经网络中的数据,也叫做输入数据(包括自变量及标签),自变量就是刚才我们说的X,而标签就是因变量Y。
由于CNN解决的问题通常是人工智能,那么我们需要大量数据、大量因素的分析和处理,那么数据就不可能是只有几个,应该是成千上万组的数据!因素就不可能只有X1~X5五个自变量的数据了,应该是好几百个!
我们假定有6W张28*28的数字图片,假定CNN要做的事情是识别这些图片里面的数字是几。

图3:100张数字图片
这些图片中,每一个图片都有一个数字,上图中共有100张图片。这些图片我们还得继续思考。首先我们看图片有什么特点?你猜?
猜不出来我告诉你,这些图每个图中都有数字,是数字图片(废话,不是刚刚说完?),而每一个数字图片都是一个灰度图。

啥意思?比如其中的一张图,就拿0这张举例,它是一个28*28的图片,也就是说他横向有28个点,纵向它也有28个点。我们把这些点编号,用表格表示为:
1 |
2 |
... |
28 |
29 |
30 |
... |
56 |
... |
... |
... |
... |
757 |
... |
... |
784 |
每一个编号中它有一个数字,表示这个小格子的颜色,0代表的是黑色,255代表的是白色,而介于0~255中间的颜色是黑色一点点渐变到白色的灰色。这784个点有序的排列组成了0图片,这样的图就叫做灰度图。
我们把这些小点都作为自变量,我们就得到了x1~x784,共784个自变量。而这些自变量你也发现了它是一个矩形的表格,而不是我们刚才X1~X5的一个长条形。那么我们就需要做一些处理,处理的方式就是把第二行的数据搬到第一行末尾,第三行搬到第二行末尾,以此类推,形成一个长条形的表格。
X1 |
X2 |
... |
X28 |
X29 |
... |
X784 |
做完长方形表格之后,我们的自变量就创造成功了,那么标签呢?更简单了,什么叫标签?说白了就是因变量Y,就是说这个图中的数字到底是几?那么怎么表示这个数字是几呢?我们想数字一共就0~9共10个,那么我们做一个1*10的表格可不可以,然后每一个表格中有一个数字,数字是0或者是1,0表示不是这个数字,1表示是这个数字。于是一个表格就出现了:
Y1 |
Y2 |
Y3 |
Y4 |
Y5 |
Y6 |
Y7 |
Y8 |
Y9 |
Y10 |
一共因变量共有十个,如果是上面的图,数字是0,那么第一个格子中就是1,其余的就是0,可以写成:
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
这样,我们一张图已经做完了,
这张图最后的形式就是:
自变量 |
X1 |
X2 |
... |
X784 |
标签 |
Y1 |
Y2 |
Y3 |
Y4 |
Y5 |
Y6 |
Y7 |
Y8 |
Y9 |
Y10 |
因为一共有6W张图,其余的图也是一样的,我们会得到6W组这样的变量,这样的变量就是我们输入到卷积神经网络中的变量,最后我们会得到一个自变量、标签的表格:
自变量1 |
X_1,1 |
X_1,2 |
... |
X_1,784 |
自变量2 |
X_2,1 |
X_2,2 |
... |
X_2,784 |
... |
... |
... |
... |
... |
自变量6W |
X_6W,1 |
X_6W,2 |
... |
X_6W,784 |
表中,X_a,b指的是第a张图中的第b个自变量。
标签1 |
Y_1,1 |
Y_1,2 |
... |
Y_1,10 |
标签2 |
Y_2,1 |
Y_2,2 |
... |
Y_2,10 |
... |
... |
... |
... |
... |
标签6W |
Y_6W,1 |
Y_6W,2 |
... |
Y_6W,10 |
表中,Y_a,b指的是第a张图中的第b个标签。
这样,我们的输入变量就都完成了。也就是说第一步变量处理已经做完了,把变量导入到CNN中就可以开始下一步正向传播了。
第一课就讲到这里,第二节课讲正向传播。
————————————————
如果对我的课程感兴趣的话,欢迎关注小木希望学园-微信公众号:
mutianwei521
也可以扫描二维码哦!
