话说本机保存了大量的网页,多半是技术文章。
浏览器自带的保存方式“还原度”不高,把内容粘贴到word吧又太费劲,是听说有一些现成的工具,但还是决定自己造个轮子。。。

网页本身、引用的脚步文件、样式文件、图片等都可以下载下来,默认不下载脚步文件。
样式文件里单独引用的图片也会下载下来。
我得承认,使用起来有点费劲,需要先粘贴网址到剪贴板然后敲下回车,再粘贴“实际”的网页内容到剪贴板然后再敲下回车。
之所以要求“实际”的网页内容而不是最初由服务器返回的HTML,原因是有很多网页只有当你滚动到页面最下端或者等待脚本文件执行完毕,才会真正渲染完成。
拿Chrome举例, 你可以这样获得实际的网页内容:
打开开发者工具, 切换到Elements标签, 右击 html 元素, 出现上下文菜单, 选择 Copy > Copy outerHTML。
配置文件(config.json)部分属性:
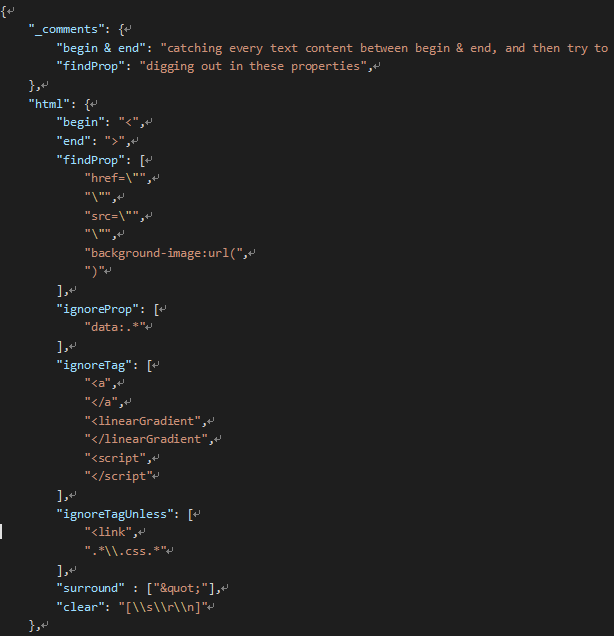
findProp - 从哪些属性里寻找要下载的文件,如<img
src=""/>
ignoreProp - 哪些属性就放弃下载,如<img src=\"
data:image/png;base64,iVBORw0KGgoAAAANSU......
ignoreTag - 哪些标记放弃下载,如<script>
ignoreTagUnless - 哪些标记放弃下载,除非有某些特定的值,如<link>如果引用的样式文件就下载,否则放弃
killScript - 如果设为true,页面上所有的<script>包括大段的写在页面上的javascript代码清除掉。
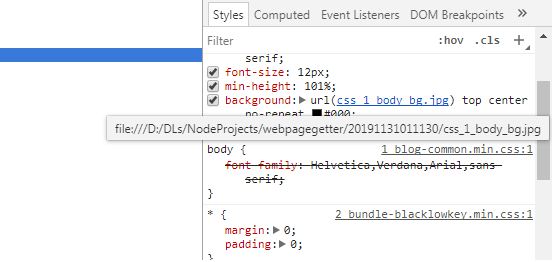
下面看下效果:

注意那个背景,那是一个样式文件所引用的图片,现在也被下载到本地,并且改写了页面的引用地址。
希望这个工具能对大家有点儿小用!
19.11.1
代码压缩成了一个zip文件,网站自带的编辑器没找到显示下载链接的地方,只能手动编辑html了。