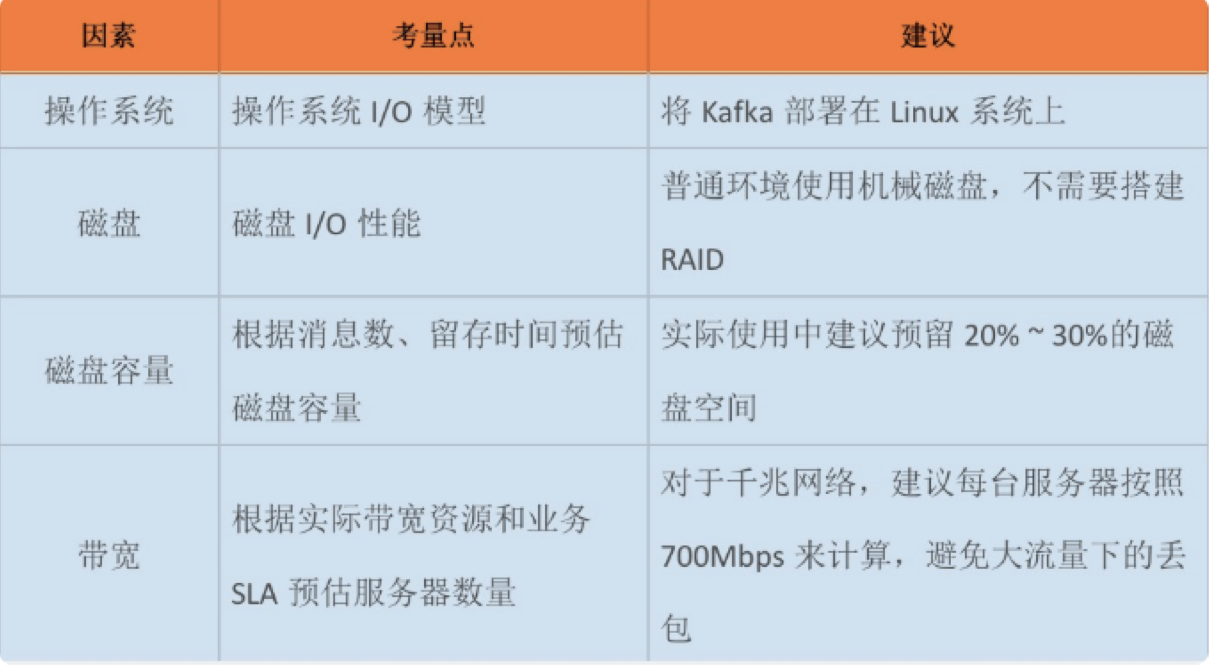
下面我们分别从操作系统、磁盘、磁盘带宽和带宽方面来讨论下。
- 操作系统
说起操作系统,你可能会问kafka不是JVM系的大数据框架吗?java又是跨平台的语言,把kafka安装不同的操作系统上会有什么区别吗?其实区别相当大。
的确,如你所知,kafka是由Scala语言和Java语言编写而写,编译之后的源代码就是普通的“.class”文件。本来部署那个操作系统是应该是一样的,但是不同操作系统的差异环视给kafka带来了相当大的影响。kafka可以部署到:linux、window、macos上面。
如果考虑操作系统与kafka的适配性,linux系统显然要比其他俩个系统更加适合。应为在下面的三个方面linux表现更加的突出:
- I/O模型的使用
- 数据网络传输效率
- 社区支持度
首先看下I/O模型,什么是I/O模型?你可以近似的认为I/O模型就是操作系统执行I/O指令的方法。
主流的I/O模型通常有5中类型: 阻塞式I/O、非阻塞式I/O、I/O多路复用、信号驱动I/O和异步I/O。每种I/O模型都有各自的典型的使用场景,比如Java中Socket对象使用的阻塞模式和非阻塞模式就对应前俩种模型;而linux中的系统调用select函数就属于I/O多路复用模型;大名鼎鼎的epoll系统调用则介于第三种和第四种模型之间;至于第五种模型,其实很少有linux系统的支持,反而是win系统提供了一个叫IOCP线程模型属于这一种。
一般情况下我们认为后一种的模型会比前一种的模型更加高级,比如epoll就比select要好。
实际上kafka客户端底层使用了Java的selector,selector在linux上的实现机制是epoll,而在win系统中实现机制是select。因此,在这一点上kafka部署在linux上可以获取更高效的I/O性能。
其次是网络传输差别,kafka需要在磁盘和网络间进行大量数据传输。在linux中,有零拷贝技术,就是当数据在磁盘和网络进行传输时避免昂贵的内核态数据拷贝从而实现快速的数据传输。因此,部署在linux上是比较合适的。
kafka在win上的bug一般是不修复的,不保证kafka在win系统上的稳定性。
- 磁盘
kafka大量使用磁盘不假,可他使用的方式多是顺序读写,一定程度上避免了机械磁盘(HHD)最大的劣势,即随机读写操作满。而它因易损坏而造成的可靠性差等缺陷,又由kafka在软件层面提供机制来保证,故使用普通机械磁盘是很盘算的。
但是切记,在预算比较多的时候还是能使用ssd就使用ssd,因给SSD的吞吐量确实比较高。
- 带宽
根据实际发送的数据库带下估算使用的带宽,来开服务的带宽服务。