版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
基于jsoup框架的爬虫系统,包括接口爬、定时爬、多线程爬
GitHub地址:https://github.com/HappyWjl/spider-jsoup
如果该项目对您有帮助,您可以点右上角 “Star” 支持一下 谢谢!
或者您可以 “follow” 一下,该项目将持续更新,不断完善功能。
转载还请注明出处,谢谢了
博主QQ:820155406
一、简介
- 本博客基于jsoup框架搭建爬虫系统,属于入门案例,仅爬取静态网页(代码案例基于古诗文网进行演示https://www.gushiwen.org/),动态网页可自行研究puppeteer,或者其他高大上的技术方案~
- jsoup:百度百科地址 https://baike.baidu.com/item/jsoup
- 个人理解,这个框架就是根据url,将整个网页抓取成一份文档(Document),然后通过select方法进行标签筛选,过滤符合要求的内容,还可以根据attr方法进行属性值获取。整体简单高效,但局限在静态网页的爬取中,动态网页或者网站规范不正确时,爬取会比较困难。
二、环境搭建
- IDEA:http://www.ilearn1234.com/#/tool?id=1&type=tool
- JDK11:http://www.ilearn1234.com/#/tool?id=4&type=tool 注意:这里需要下载jdk11的版本
- Postman:http://www.ilearn1234.com/#/tool?id=9&type=tool
三、项目讲解
- 项目结构如图:
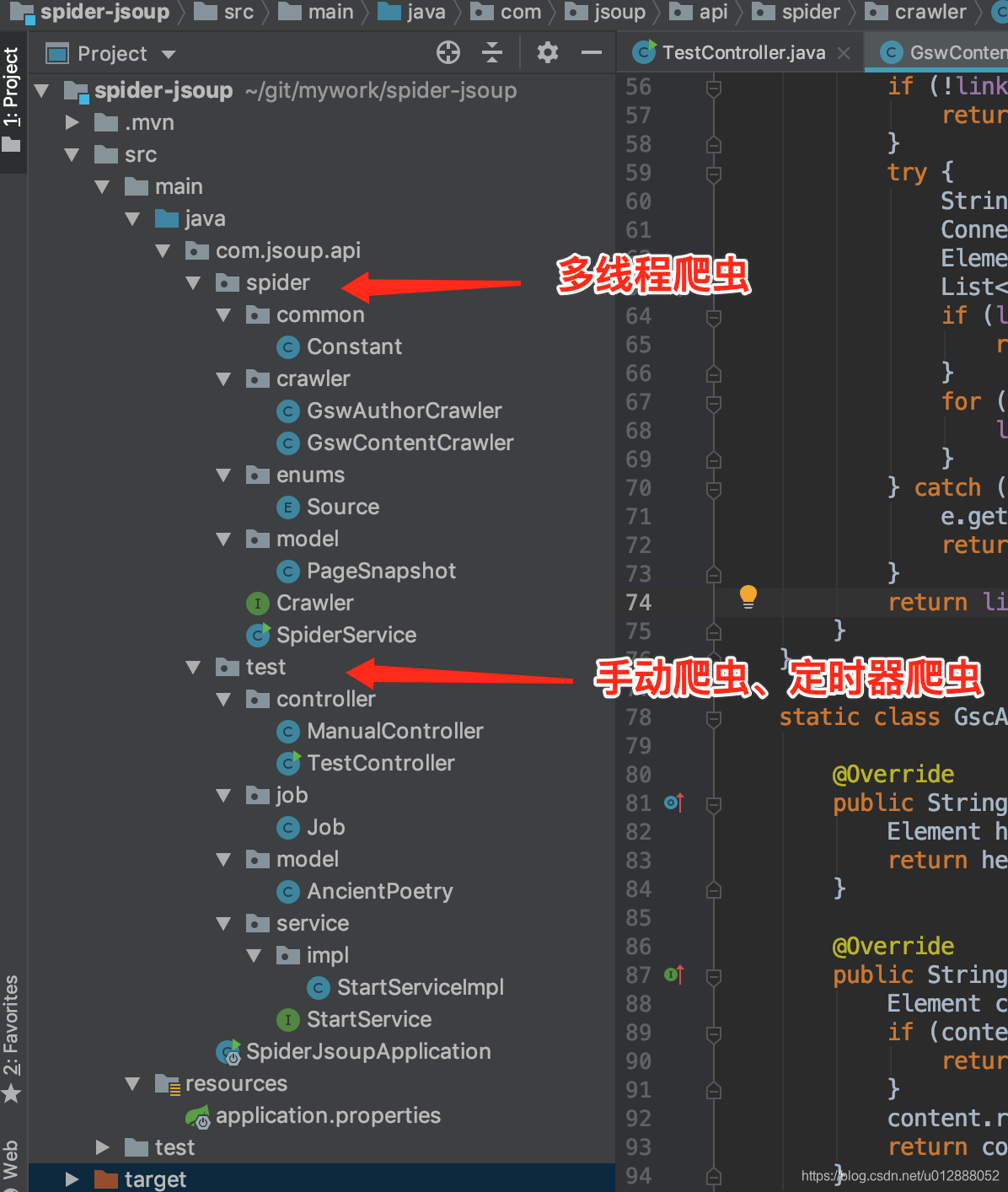
- 手动爬虫
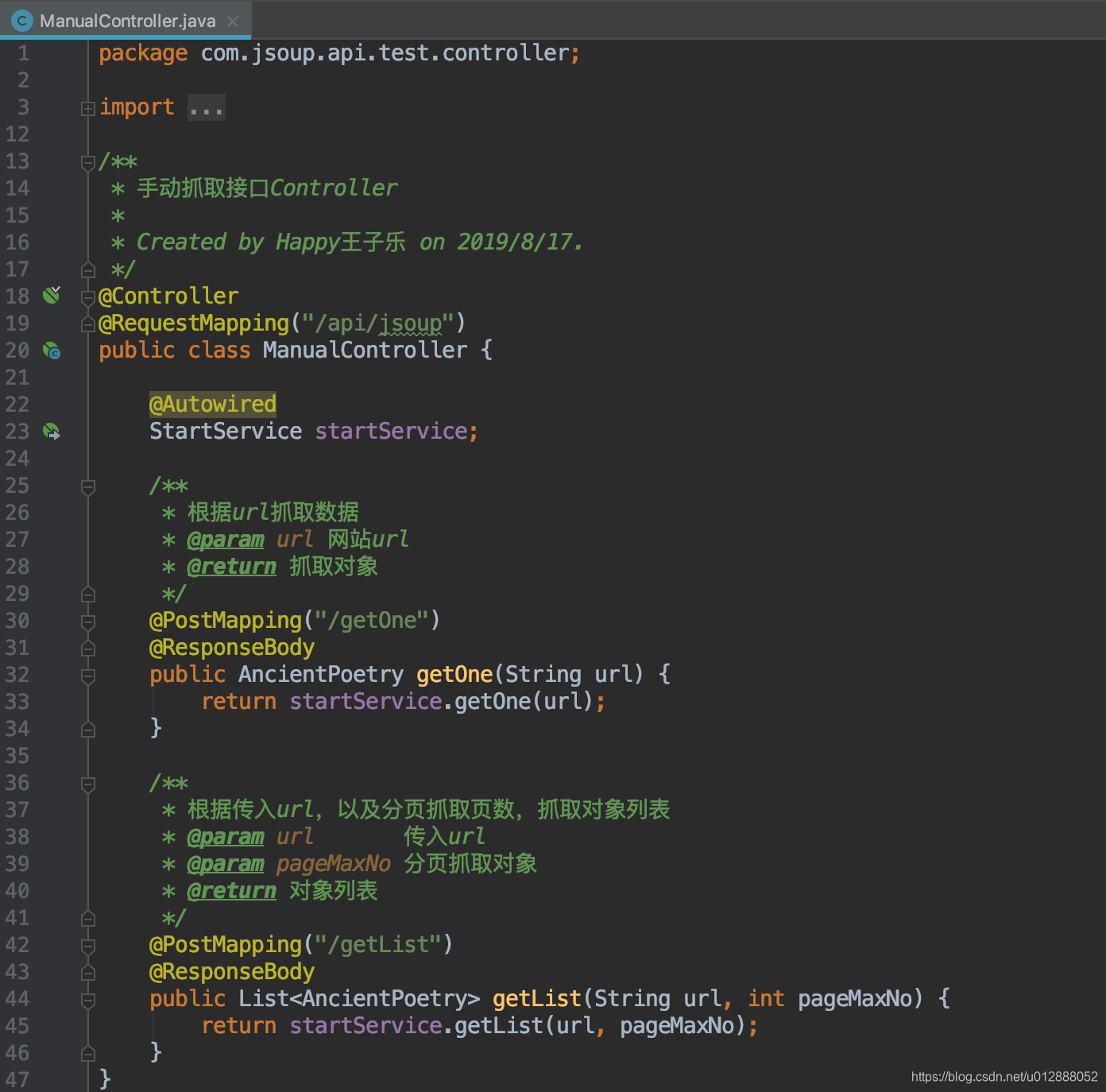
- 首先打开ManualController,可以看到有两个接口,“根据url抓取数据”、“根据url抓取数据列表”
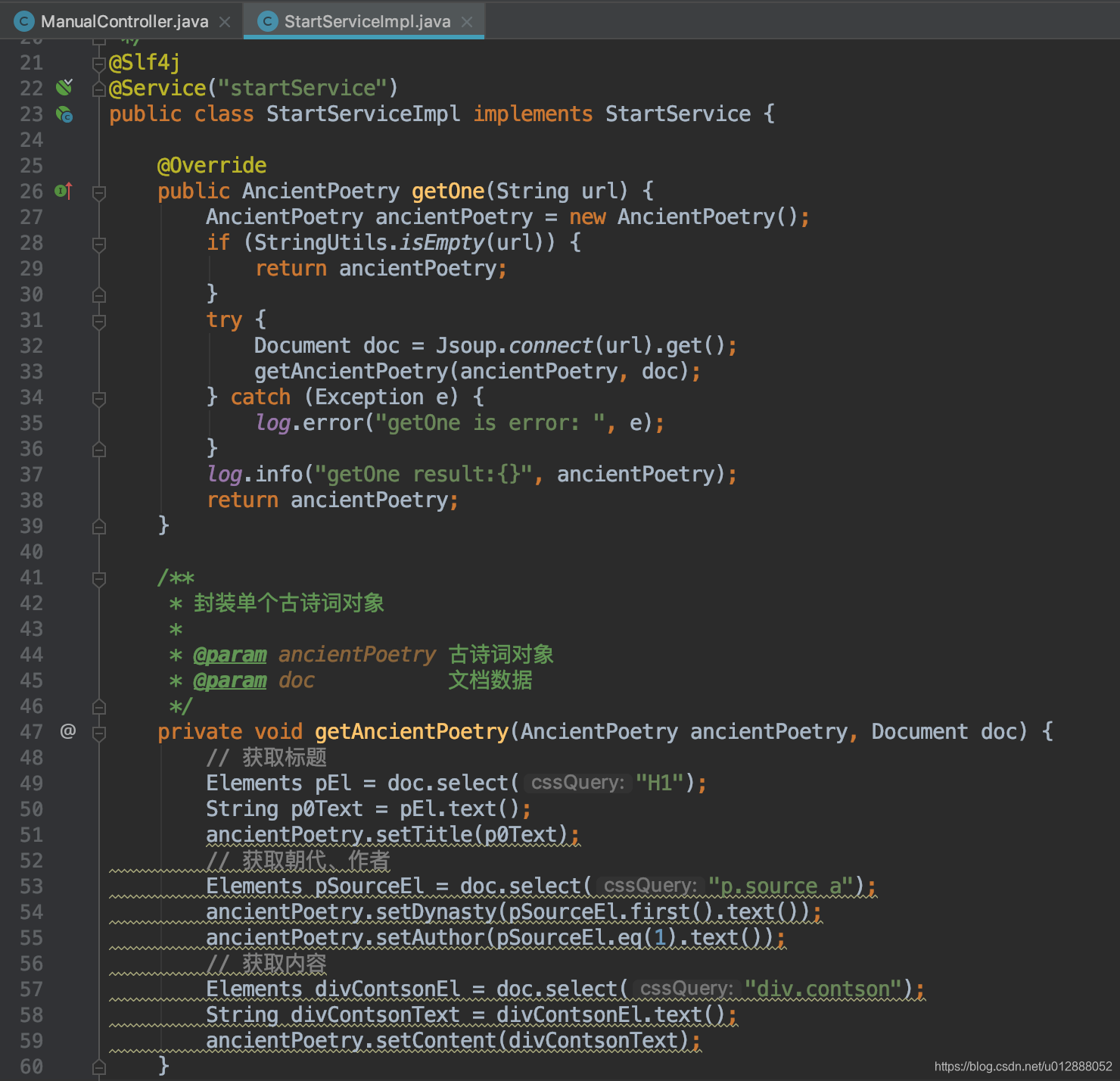
- 我们打开StartServiceImpl文件,可以看到具体的实现方法
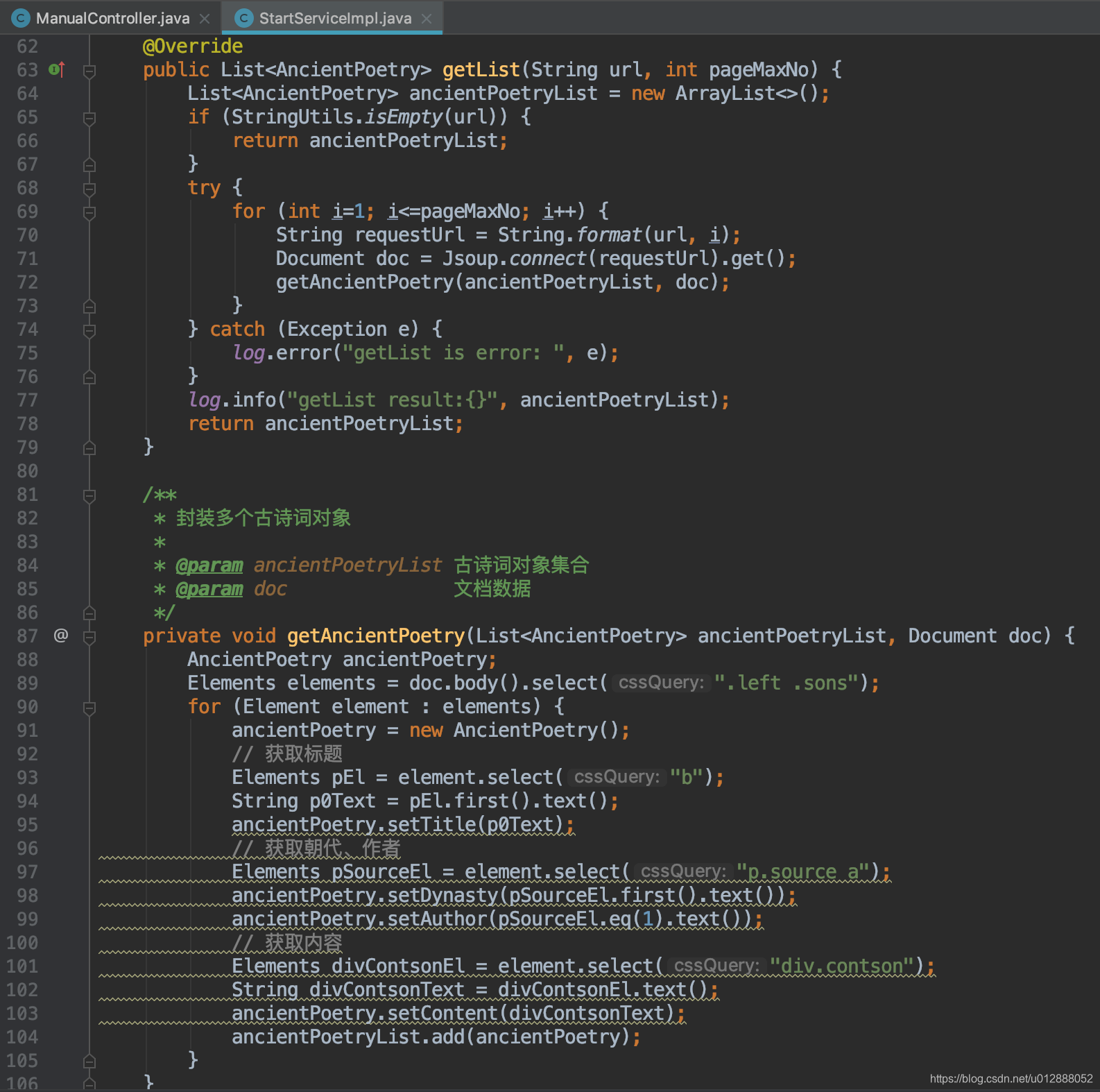
- 第一个测试抓取url为:https://so.gushiwen.org/shiwenv_ee16df5673bc.aspx,第二个测试抓取的url为:https://so.gushiwen.org/shiwen/default.aspx?page=1&type=4&id=1(PS:注意下方第二个请求截图传参是这个地址:https://so.gushiwen.org/shiwen/default.aspx?page=%s&type=4&id=1,因为需要拼接分页参数)
- 由于两个地址内容结构有点差异,所以写了两个封装古诗词对象的方法
- 首先启动项目,打开SpiderJsoupApplication文件,启动main方法,正常启动无报错即可
- 然后我们使用postman,模拟第一个接口的请求:
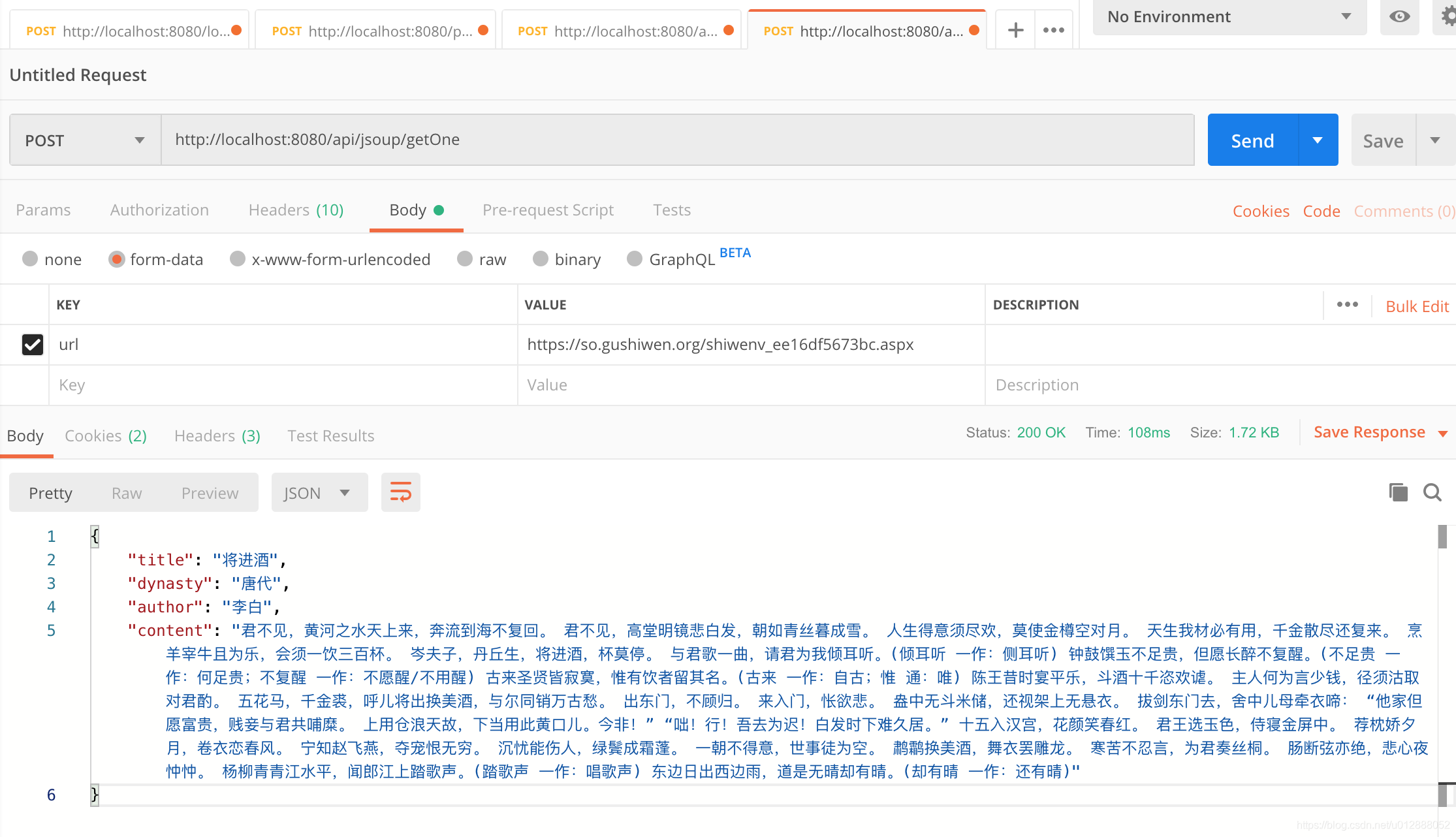
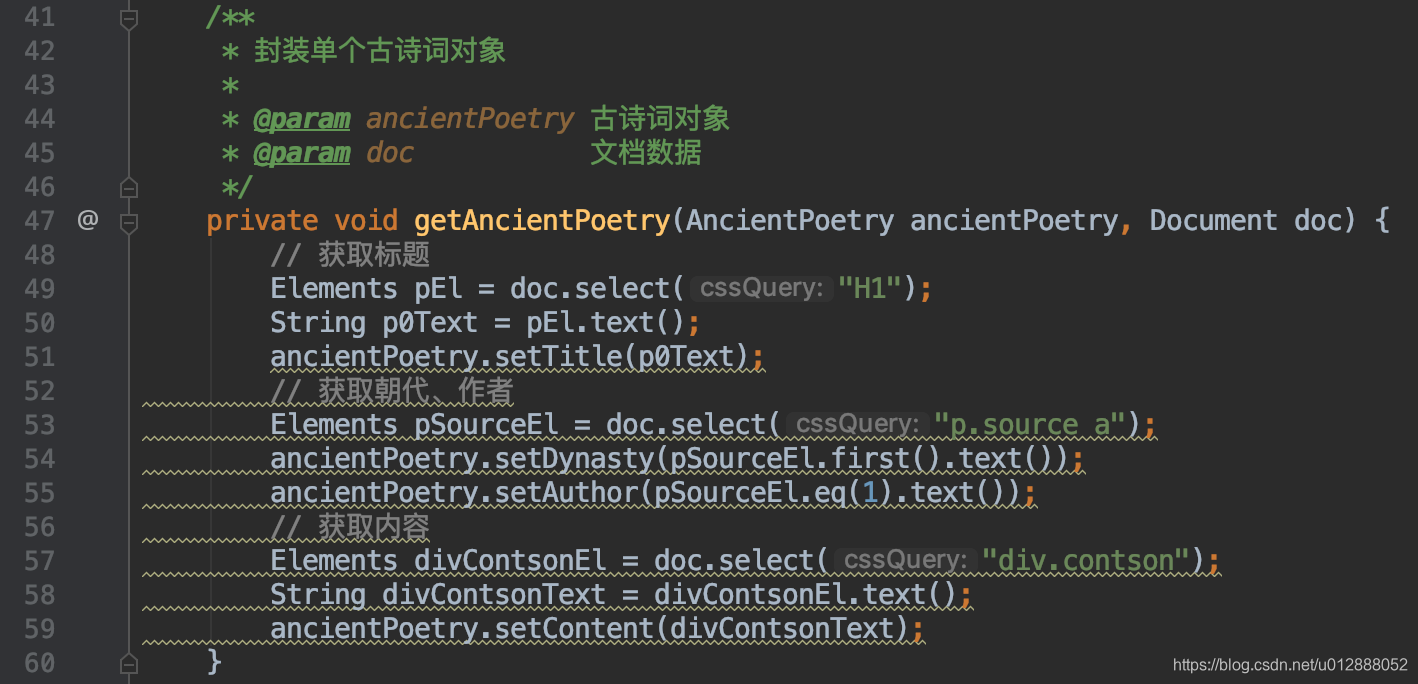
- 接口成功返回了我们需要的数据,核心代码为下图,这段代码根据网页上的标签,进行解析,将包含的内容成功地赋值到ancientPoetry中:
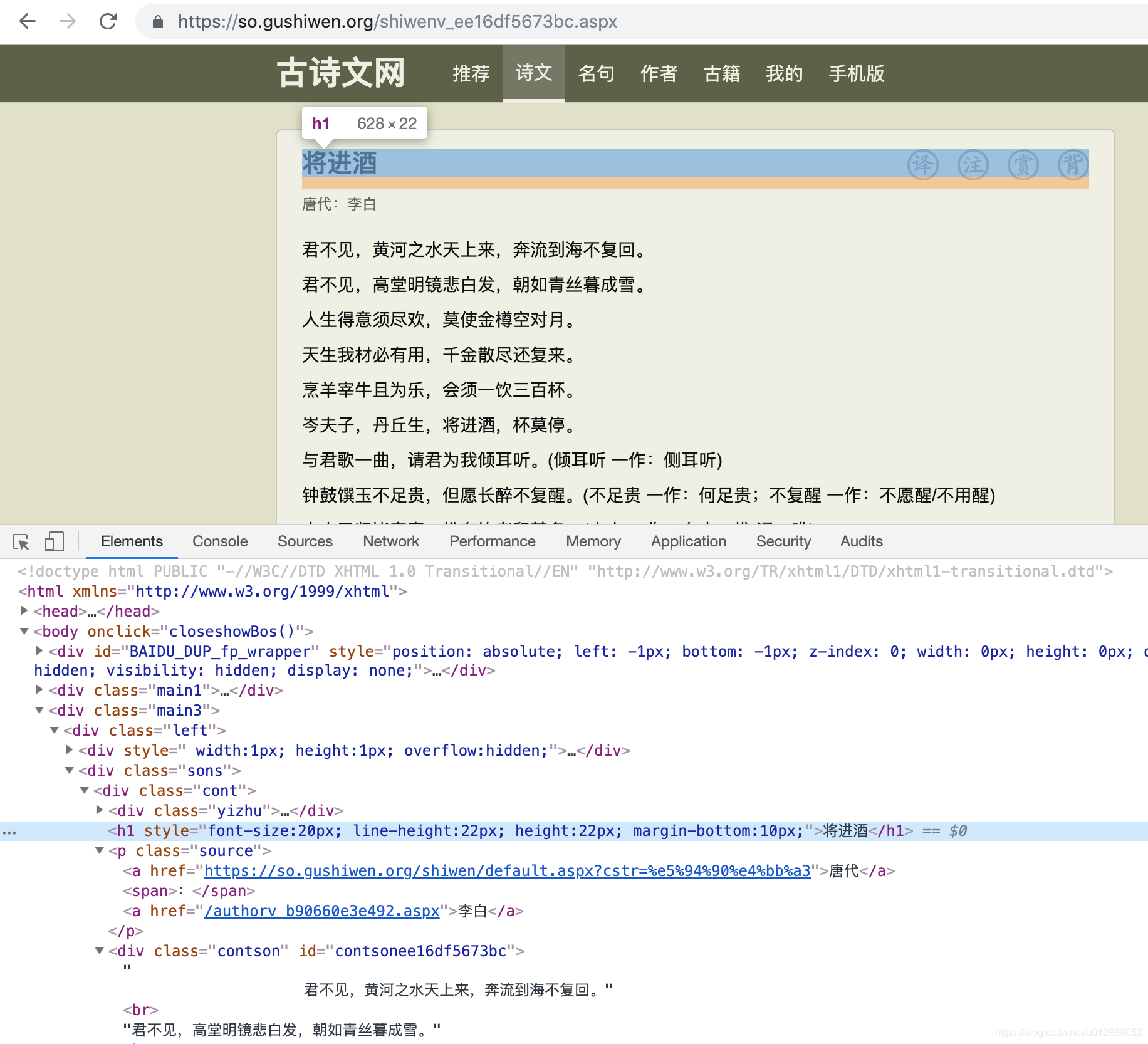
- 我们检查一下对应的页面内容,可以发现网页标签中和抓取代码是匹配的,根据特定的标签+类选择器,即可爬取到对应的内容:
其实剩下的博文,都类似上方讲解,介意的勿往下看,可以直接下载源码,自行研究就好。
GitHub地址:https://github.com/HappyWjl/spider-jsoup
如果该项目对您有帮助,您可以点右上角 “Star” 支持一下 谢谢!
或者您可以 “follow” 一下,该项目将持续更新,不断完善功能。
转载还请注明出处,谢谢了
博主QQ:820155406
- 再然后我们使用postman,模拟第二个接口的请求:
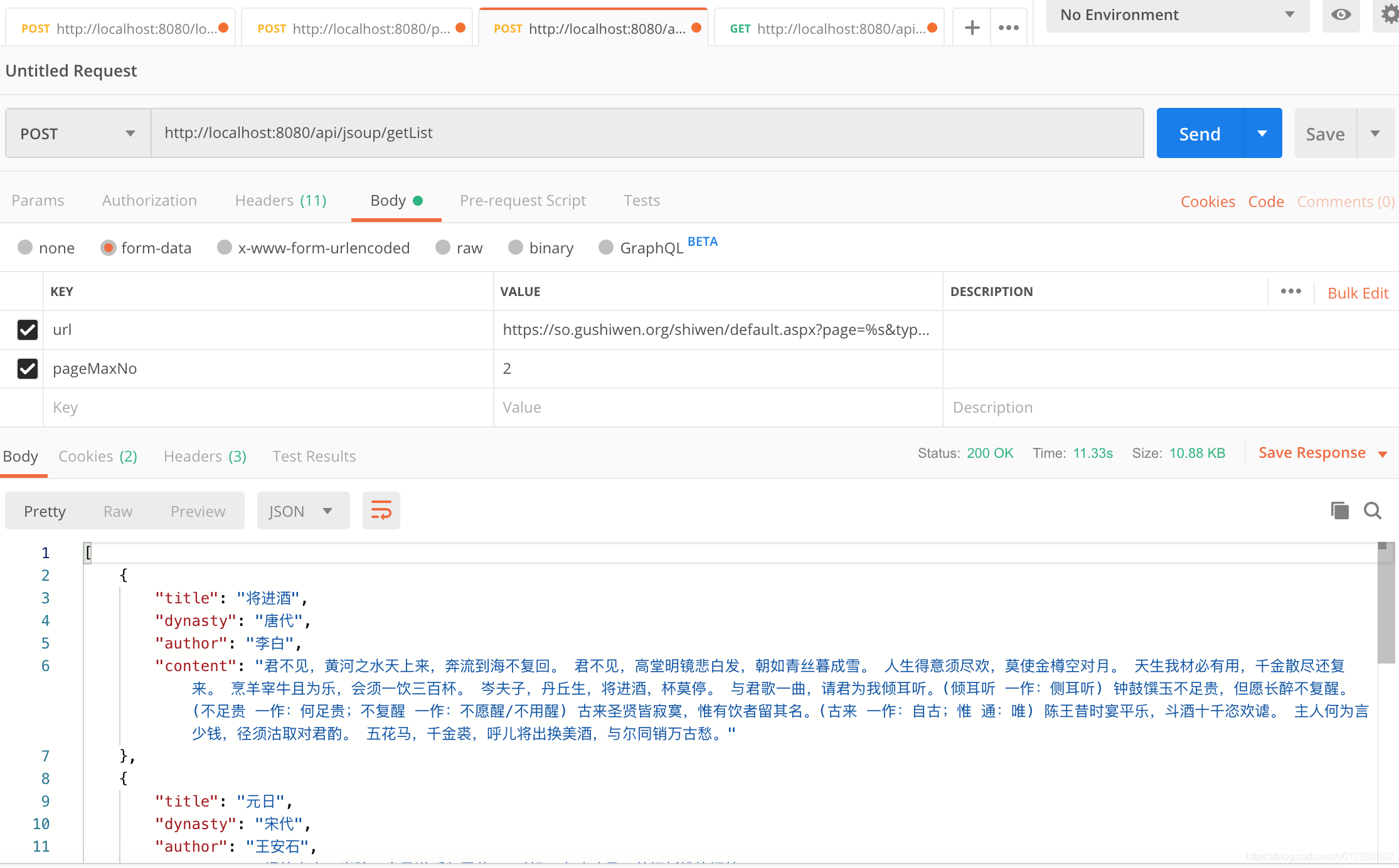
- 可以看到,接口已经将结果返回,这个接口定义了循环几页去抓取内容,通过pageMaxNo进行控制(PS:分页是从1开始的,这个需要注意下,接口最好使用POST请求,入股采用GET请求,url的除第一个参数外,其他参数会丢失)
- 具体代码如下,采用for循环,进行分页轮询,将每页的抓取结果,存放到ancientPoetryList中,最后返回:
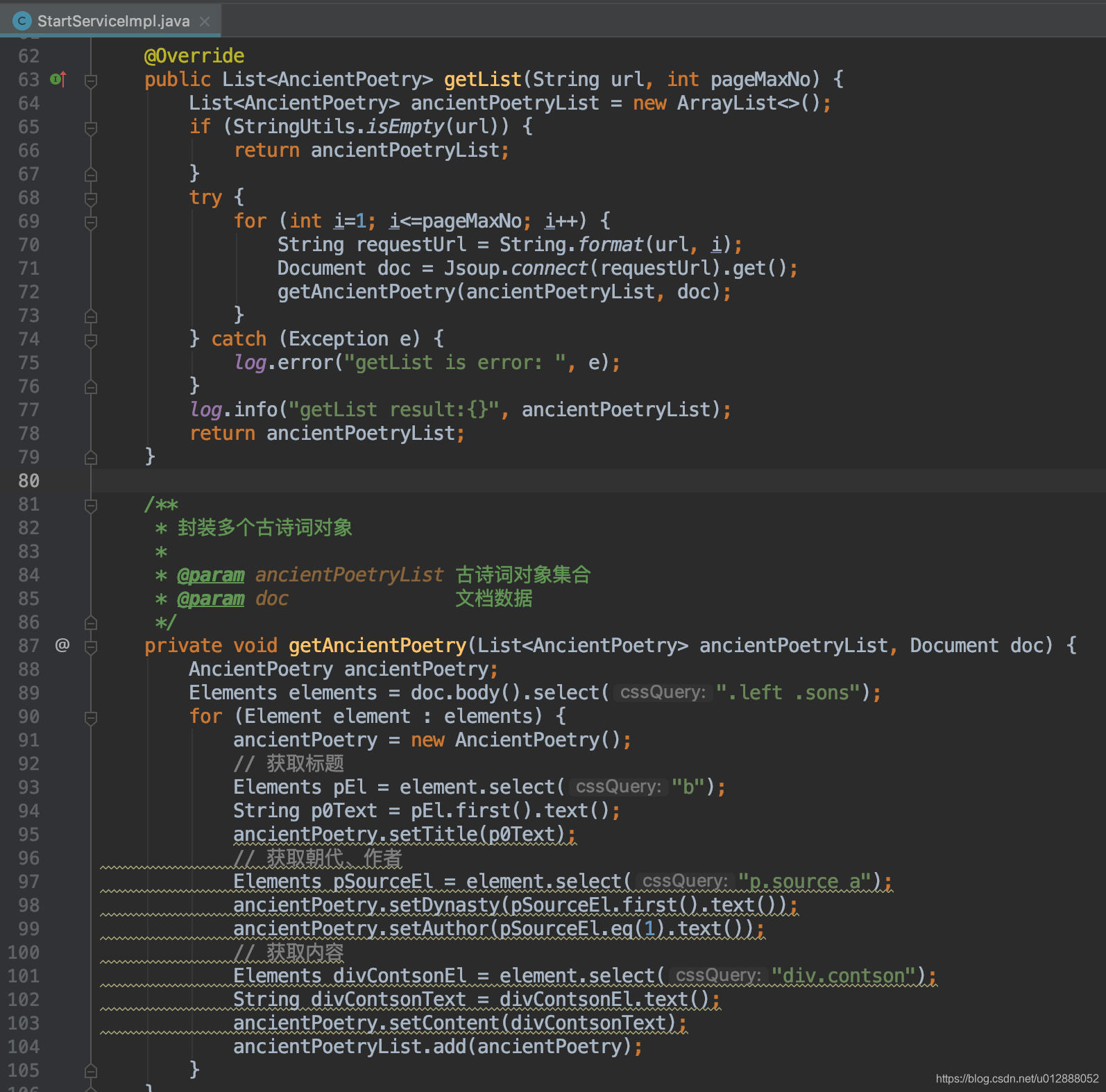
- 讲完接口手动抓取,再来讲讲job定时触发,因为很多网站晚上12点才会更新内容,为了更快地抓取新的数据,我们需要定时去抓取的,代码里延迟2小时进行数据抓取
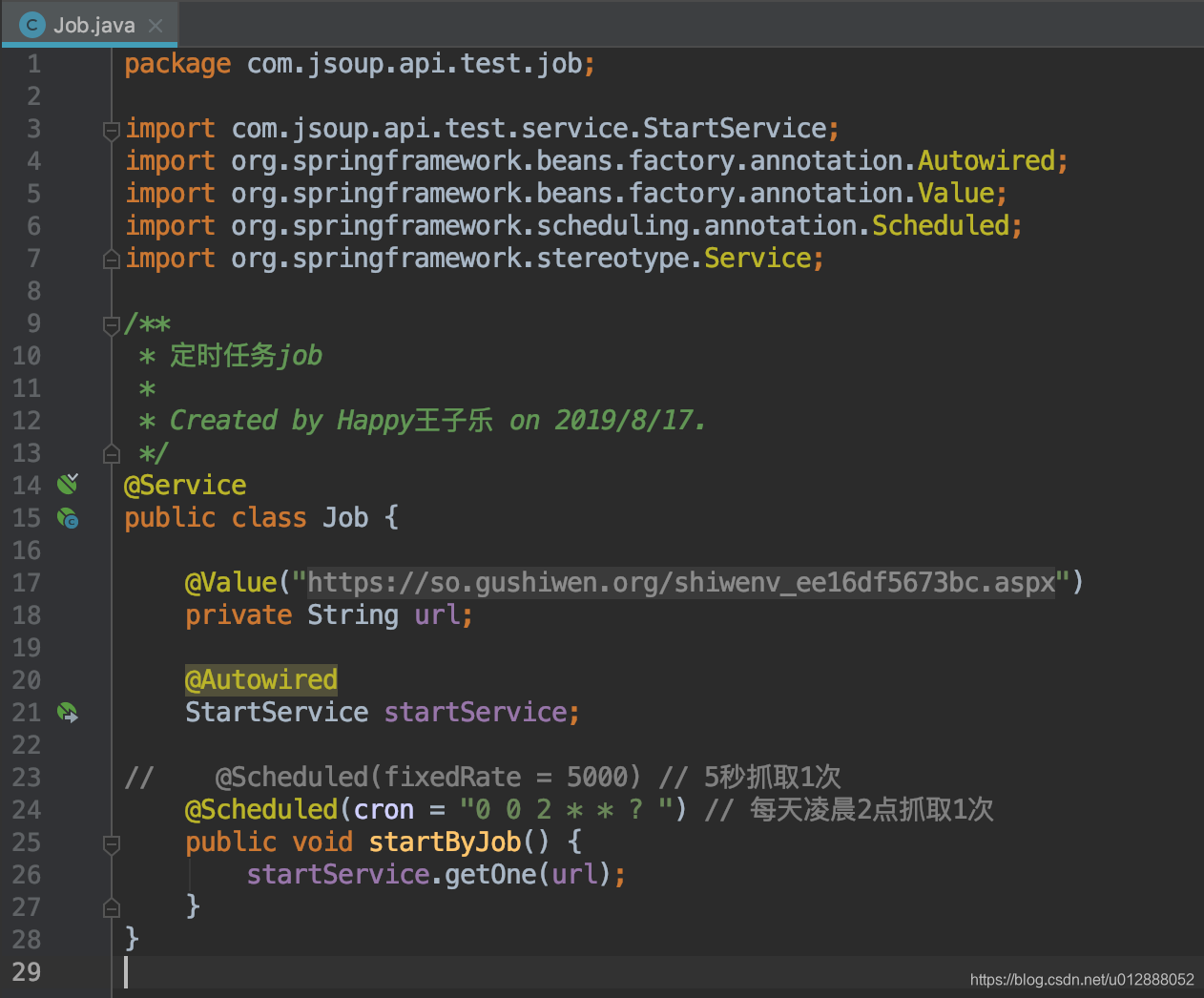
- 我们打开job文件,可以看到代码很简单,cron的定时器语法,可参见百度。job任务结合已经写好的接口,只需要将url传入进去触发。url可以配置到application.properties中,或者自行放到数据库中,再写个查询方法即可
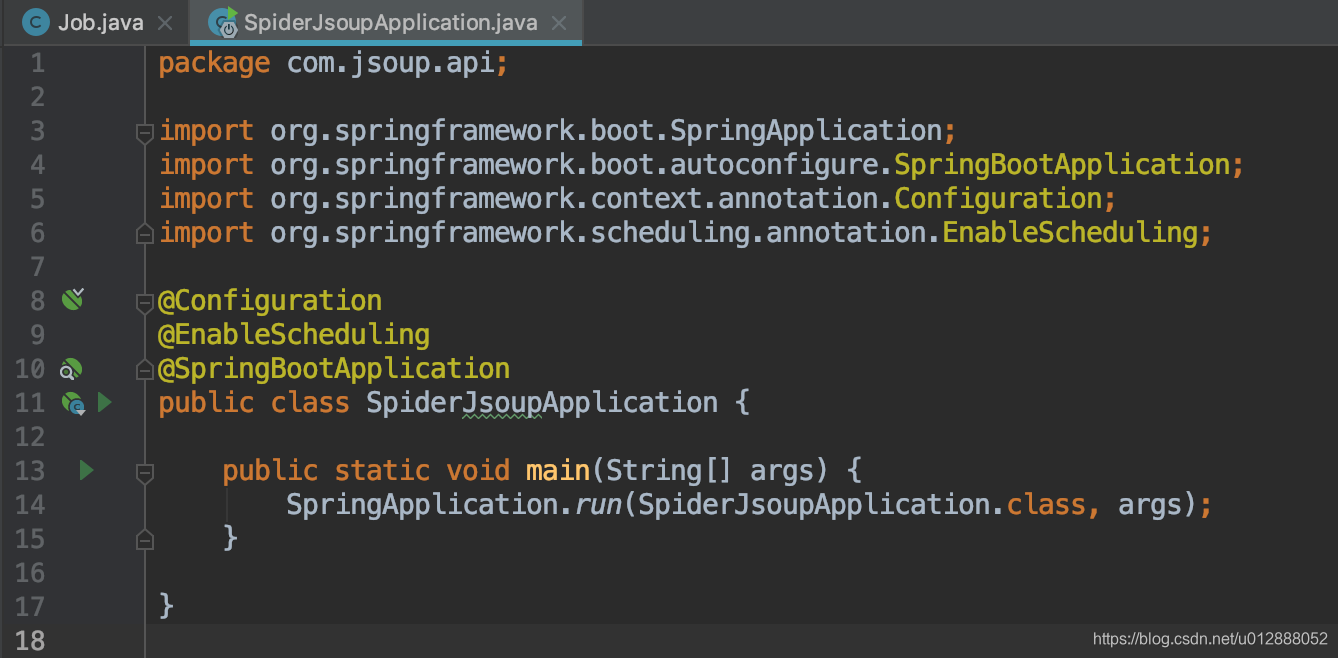
- 使用job定时器时,启动文件需要加上指定注解,方便在启动时,加载相关配置
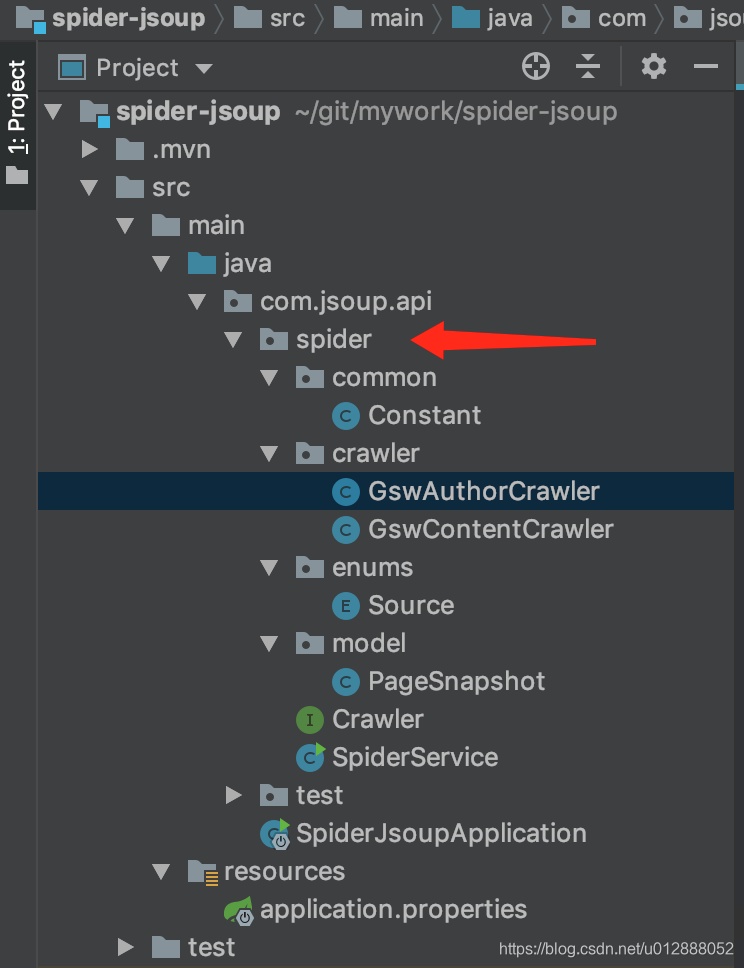
- 最后讲讲多线程抓取,参见spider包中代码,这里的代码非博主原创,由博主同事提供,多谢我大坤哥~
- 多线程抓取,启动文件为SpiderService,调用main方法,即可开启多线程抓取
- 这里采用了建造者模式,通过传入的列表url,再进行列表中url抓取每个文章的跳转链接,根据抓取的链接,分别访问每一个详情页,进行抓取详细内容
- GswAuthorCrawler(古诗文网作者信息爬虫)和GswContentCrawler(古诗文网内容爬虫)是演示的两个页面的爬虫文件,里面个性化定义了网站地址、分页次数、抓取标签、组装内容等操作
package com.jsoup.api.spider.crawler;
import com.jsoup.api.spider.Crawler;
import lombok.extern.slf4j.Slf4j;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.stereotype.Service;
import org.springframework.util.CollectionUtils;
import java.util.LinkedList;
/**
* 自定义网站抓取爬虫(古诗文作者)
*
* Created by Happy王子乐 on 2019/8/17.
*/
@Service
public class GswAuthorCrawler implements Crawler {
@Override
public String name() {
return "古诗文作者";
}
@Override
public Spider newSpider() {
return new BaiDuImgSpider();
}
@Override
public Analyzer analyzer() {
return new BaiDuImgAnalyzer();
}
@Slf4j
static class BaiDuImgSpider implements Spider {
static final String LIST_LINK_FORMAT = "https://so.gushiwen.org/authors/";
private int page = 3;
private boolean last = false;
private LinkedList<String> linkList = new LinkedList<>();
@Override
public String nextLink() {
if (last) {
return null;
}
if (!linkList.isEmpty()) {
return linkList.removeFirst();
}
try {
String url = String.format(LIST_LINK_FORMAT, page++);
Connection conn = Jsoup.connect(url);
Elements elements = conn.get().body().select(".sonspic .cont p");
if (last = CollectionUtils.isEmpty(elements)) {
return null;
}
for (Element element : elements) {
String jumpUrl = element.select("a").attr("abs:href");
if (jumpUrl.contains("authors")) {
continue;
}
linkList.add(jumpUrl);
}
} catch (Exception e) {
e.getStackTrace();
return null;
}
return linkList.removeFirst();
}
}
static class BaiDuImgAnalyzer implements Analyzer {
@Override
public String title(Document document) {
Element headline = document.select("h1").first();
return headline != null ? headline.text() : null;
}
@Override
public String content(Document document) {
Element content = document.select(".sonspic .cont").first();
if (content == null) {
return null;
}
content.removeClass("*");
return content.html();
}
}
}
package com.jsoup.api.spider.crawler;
import com.jsoup.api.spider.Crawler;
import lombok.extern.slf4j.Slf4j;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.stereotype.Service;
import org.springframework.util.CollectionUtils;
import java.util.LinkedList;
import java.util.List;
import java.util.stream.Collectors;
/**
* 自定义网站抓取爬虫(古诗文网内容)
*
* Created by Happy王子乐 on 2019/8/17.
*/
@Service
public class GswContentCrawler implements Crawler {
@Override
public String name() {
return "古诗文内容";
}
@Override
public Spider newSpider() {
return new GscSpider();
}
@Override
public Analyzer analyzer() {
return new GscAnalyzer();
}
@Slf4j
static class GscSpider implements Spider {
static final String LIST_LINK_FORMAT = "https://so.gushiwen.org/shiwen/default.aspx?page=%s&type=4&id=1";
private int page = 3;
private boolean last = false;
private LinkedList<String> linkList = new LinkedList<>();
@Override
public String nextLink() {
if (last) {
return null;
}
if (!linkList.isEmpty()) {
return linkList.removeFirst();
}
try {
String url = String.format(LIST_LINK_FORMAT, page++);
Connection conn = Jsoup.connect(url);
Elements elements = conn.get().body().select(".sons .cont p");
List<Element> elementList = elements.stream().filter(element -> element.select(".source").size() == 0).collect(Collectors.toList());
if (last = CollectionUtils.isEmpty(elementList)) {
return null;
}
for (Element element : elementList) {
linkList.add(element.select("a").attr("abs:href"));
}
} catch (Exception e) {
e.getStackTrace();
return null;
}
return linkList.removeFirst();
}
}
static class GscAnalyzer implements Analyzer {
@Override
public String title(Document document) {
Element headline = document.select("h1").first();
return headline != null ? headline.text() : null;
}
@Override
public String content(Document document) {
Element content = document.select(".contson").first();
if (content == null) {
return null;
}
content.removeClass("*");
return content.html();
}
}
}
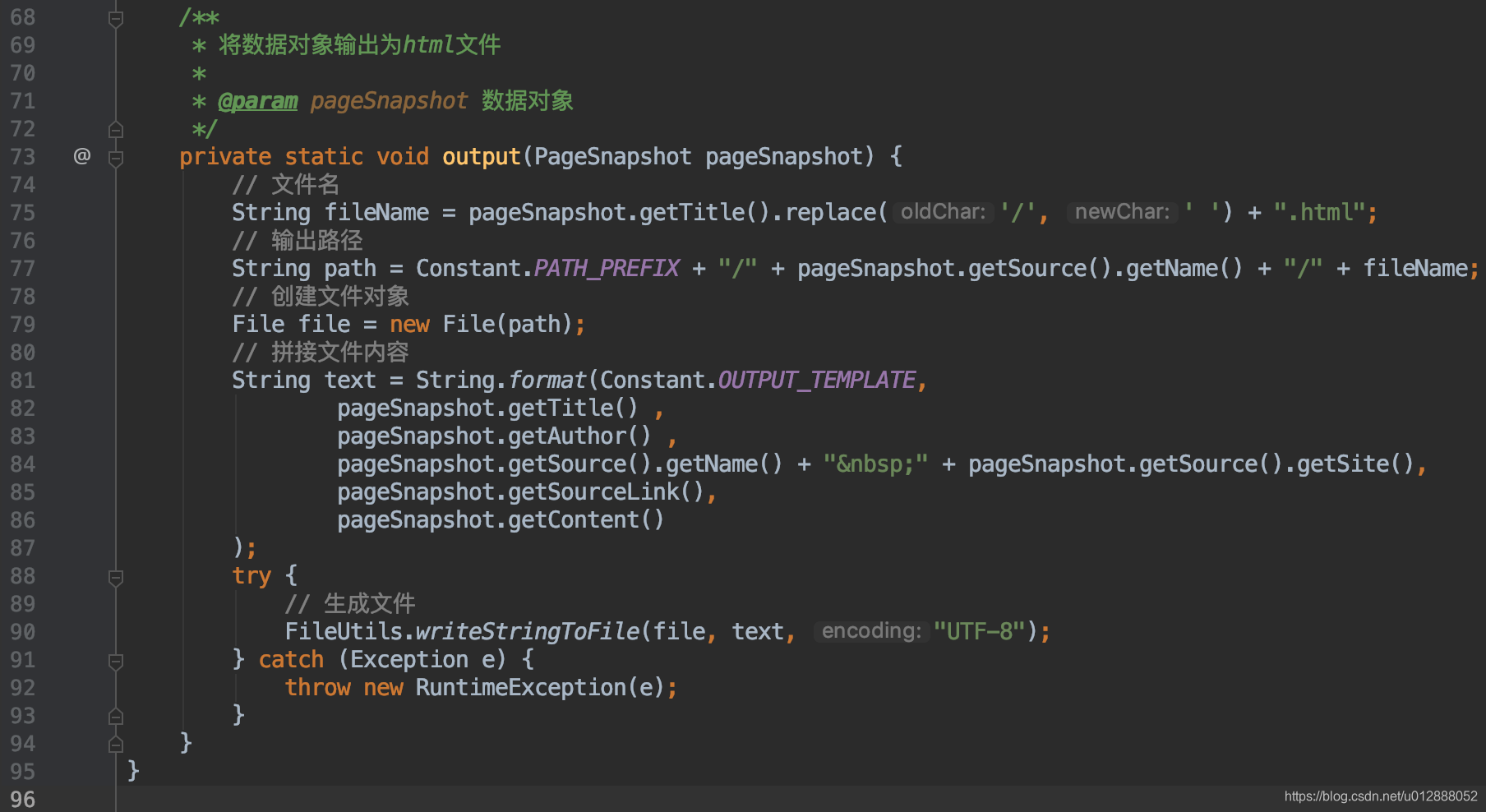
- 最后通过数据组装,结合html模版,生成html文件,输出到指定文件夹中
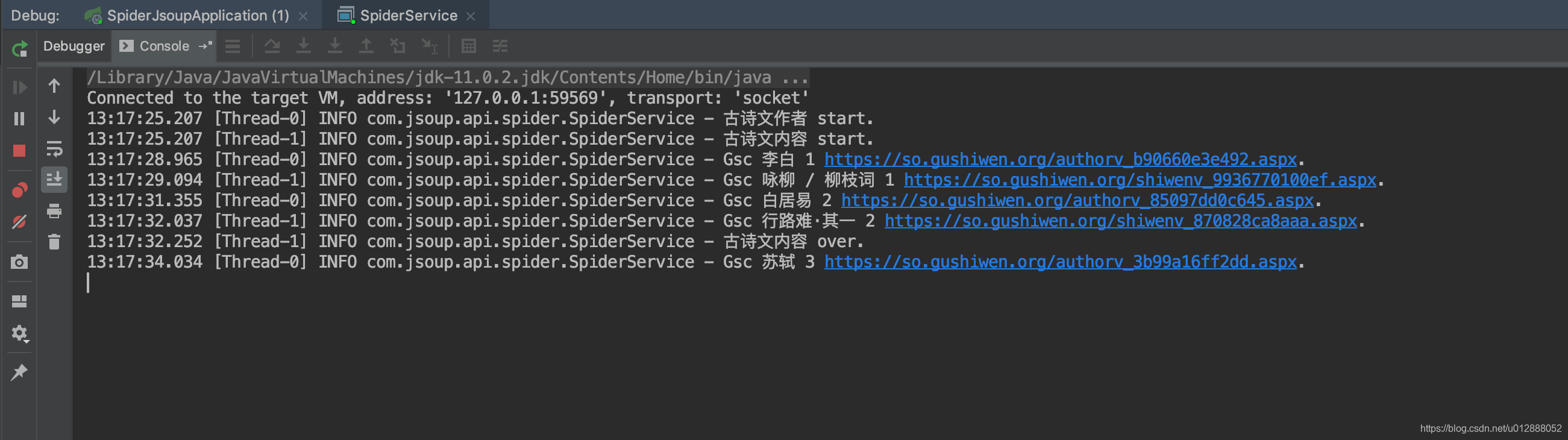
- 启动SpiderService中的main方法,找到输出路径文件夹,可以看到抓取内容已经生成为html文件
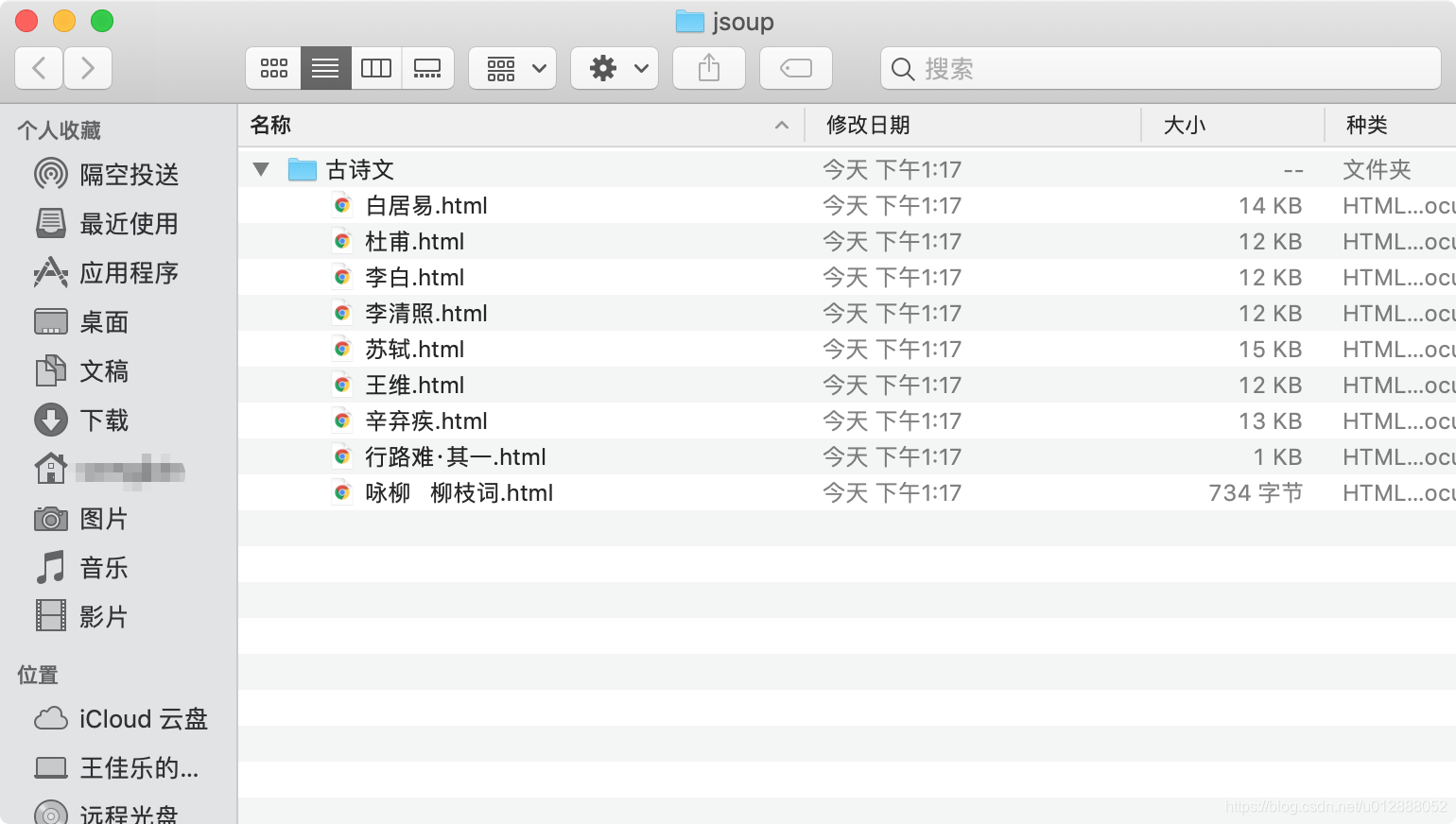
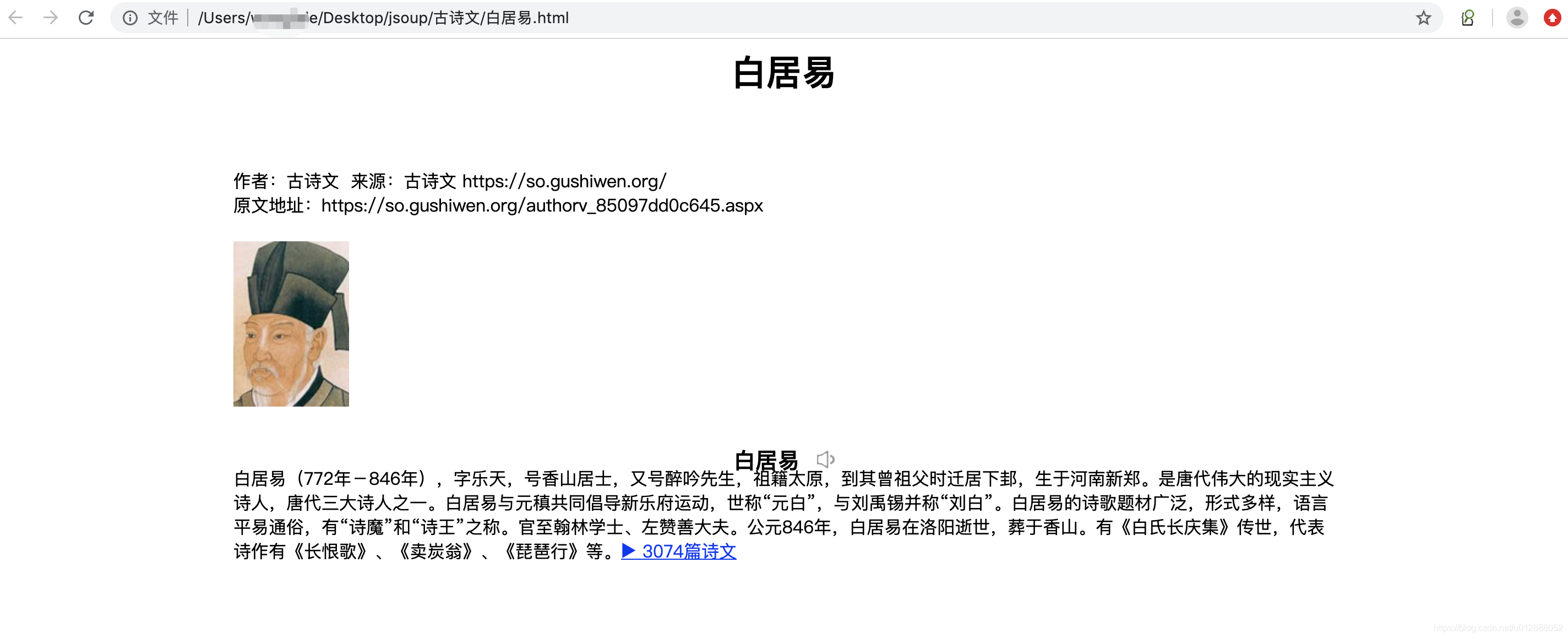
- 我们打开一个白居易.html文件,可以看到图片带作者信息已经抓取下来
- 至此,爬虫项目的大致讲解到这里,入门项目简单,可根据源码自行研究
基于jsoup框架的爬虫系统,包括接口爬、定时爬、多线程爬
GitHub地址:https://github.com/HappyWjl/spider-jsoup
如果该项目对您有帮助,您可以点右上角 “Star” 支持一下 谢谢!
或者您可以 “follow” 一下,该项目将持续更新,不断完善功能。
转载还请注明出处,谢谢了
博主QQ:820155406