1.通过Jsoup来解析xml的步骤
1.导入jar包
2.获取Document对象
3.获取对应的标签Element对象
4.获取数据
代码如下:
Demo1.java
package main.java;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
import java.net.URL;
/**
* Jsoup快速入门
*/
public class Demo1 {
public static void main(String[] args) throws IOException {
//2.获取Document对象,根据xml文档获取
//2.1获取student.xml的path
String path = Demo1.class.getClassLoader().getResource("student.xml").getPath();
//2.2解析xml文档,加载文档进内存,获取dom树--->Document
Document document = Jsoup.parse(new File(path), "utf-8");
//3.获取元素对象 Element
Elements elements = document.getElementsByTag("name");
System.out.println(elements.size());
//3.1获取第一个name的Element对象
Element element = elements.get(0);
//3.2获取数据
String name = element.text();
System.out.println(name);
}
}
student.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE students SYSTEM "student.dtd">
<!--<!DOCTYPE students [
<!ELEMENT students (student+) >
<!ELEMENT student (name,age,sex)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ELEMENT sex (#PCDATA)>
<!ATTLIST student number ID #REQUIRED>
]>-->
<students>
<student number="s001">
<name>zhangsan</name>
<age>abc</age>
<sex>hehe</sex>
</student>
<student number="s002">
<name>lisi</name>
<age>24</age>
<sex>female</sex>
</student>
</students>
效果:
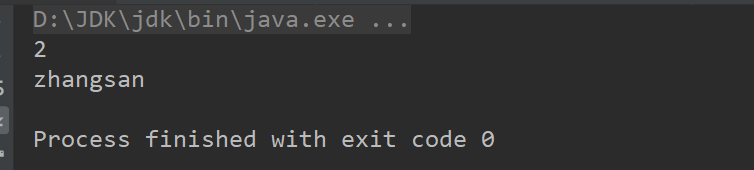
总结:
解析的具体步骤在代码上方都有注释,可以看到xml中第二个name的值被打印出来。来说一下在操作中遇到的困难(本人使用的时Idea):首先要把所有的文件夹名称都改为英语(因为这里的编码方式是UTF-8,有中文会出现乱码)。其次需要注意一下这里的文件结构,如图所示:
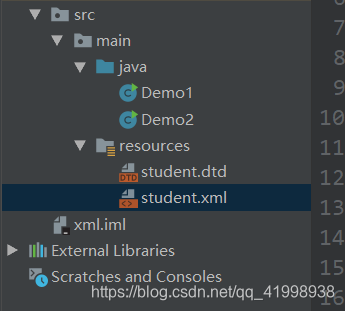
resources文件夹放置需要解析的文件,java文件放置解析的具体步骤(注意这里的文件夹的类型都是不一样的需要格外注意)。resources和java文件都需要放在src文件夹之中。
2.归纳Jsoup的方法
在上述代码中
Document document = Jsoup.parse(new File(path), “utf-8”);
这句话是来获取Document对象的(也就是获取DOM树), 获取过程中用到了Jsoup.parse方法。
Jsoup.parse方法有很多重载下面我来介绍以下其中的三种:
1.*parse(File in,String charsetName):解析xml或html文件的。
这种方法就是上述代码种用到的方法,第一个参数为文件,第二个参数是需要解析的文件所使用的编码方式。
2.parse(String html):解析xml或html字符串
这种方式需要传入字符串内容,也就是把解析文件所有的内容都当作字符串传入进去。
代码如下:
package main.java;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
import java.net.URL;
/**
* Jsoup对象功能
*/
public class Demo2 {
public static void main(String[] args) throws IOException {
//2.1获取student.xml的path
String path = Demo2.class.getClassLoader().getResource("student.xml").getPath();
// 2.parse(String html):解析xml或html字符串
String str = "<?xml version=\"1.0\" encoding=\"UTF-8\" ?>\n" +
"<students>\n" +
"\n" +
" <student number=\"s001\">\n" +
" <name>zhangsan</name>\n" +
" <age>abc</age>\n" +
" <sex>hehe</sex>\n" +
" </student>\n" +
"\n" +
" <student number=\"s002\">\n" +
" <name>lisi</name>\n" +
" <age>24</age>\n" +
" <sex>female</sex>\n" +
" </student>\n" +
"\n" +
"</students>";
Document document = Jsoup.parse(str);
System.out.println(document);
}
}
效果如下:
<!--?xml version="1.0" encoding="UTF-8" ?-->
<html>
<head></head>
<body>
<students>
<student number="s001">
<name>
zhangsan
</name>
<age>
abc
</age>
<sex>
hehe
</sex>
</student>
<student number="s002">
<name>
lisi
</name>
<age>
24
</age>
<sex>
female
</sex>
</student>
</students>
</body>
</html>
可以看到xml文件种的所有内容又被打印出来,可以证实Document确实获得了DOM树。
3.parse(URL url,int timeoutMillis):通过网络路径获取指定的html或xml的文档对象
这种方式传入的第一个参数是具体网站的链接,第二个参数是延迟的时间。
代码如下:
package main.java;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
import java.net.URL;
/**
* Jsoup对象功能
*/
public class Demo2 {
public static void main(String[] args) throws IOException {
//2.1获取student.xml的path
URL url = new URL("https://www.baidu.com/"); //代表网络中的资源路径
Document document = Jsoup.parse(url,10000);
System.out.println(document);
}
}
效果太长了,简单来说就是https://www.baidu.com这个页面的的代码(在该页面种按F12可以看到)。这种方法在日后可以用来做网站爬虫。
