java爬虫HttpClient爬取jsoup解析
java爬虫HttpClient爬取jsoup解析
使用httpclientDemo爬取数据
HttpClient 是Apache Jakarta Common 下的子项目,可以用来提供高效的、最新的、功能丰富的支持 HTTP 协议的客户端编程工具包,并且它支持 HTTP 协议最新的版本和建议。
引入依赖
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.8</version>
</dependency>
新建一个包,写一个测试类
HttpClientTest
public class HttpClientTest {
public static void main(String[] args) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet("https://taolitop.com/");
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
System.out.println(html);
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
}
执行上面的代码,会得到一个完整的html的代码
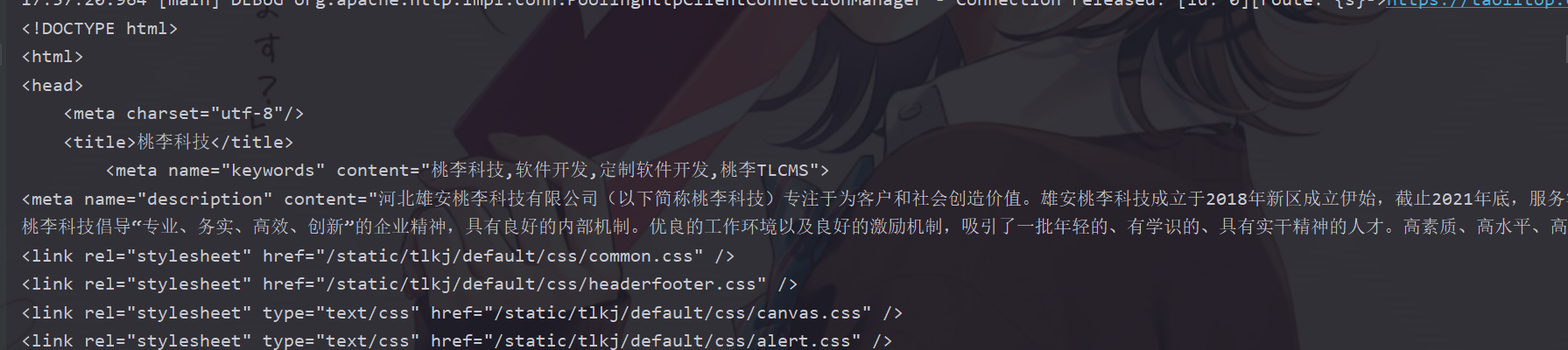
如上,这是一个简单的例子
这个网站没有设置反爬虫,所以我们没有怎么设置就轻松获取了相关的资源,如果对应的网站有识别了爬虫程序,怎么办?
爬下面的网站,我们会发现
https://www.tuicool.com/
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
</head>
<body>
<p>系统检测亲不是真人行为,因系统资源限制,我们只能拒绝你的请求。如果你有疑问,可以通过微博 http://weibo.com/tuicool2012/ 联系我们。</p>
</body>
</html>
这就表示爬虫程序被识别了。
解决方法:
- 伪装浏览器:对请求头进行伪装
伪装成浏览器,其实如果你伪装了之后,如果短时间内一直多次访问的话,网站会对你的ip进行封杀,这个时候就需要换个ip地址了,使用代理IP
- 代理IP
网上有一些免费的代理ip网站,比如xici
我们选择那些存活时间久并且刚刚被验证的ip,我这里选择了“112.85.168.223:9999”
- 放慢爬取的速度,让程序sleep一段时间再爬下一个也是一种反爬虫的简单方法。
- 有些网站休要登录后才可以请求对应的资源,这时候就需要进行一个模拟登录
HttpGet request = new HttpGet("https://www.tuicool.com/");
//设置请求头,将爬虫伪装成浏览器
request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");
HttpHost proxy = new HttpHost("112.85.168.223", 9999);
RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
request.setConfig(config);
示例代码
public class HttpClientTest2 {
public static void main(String[] args) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet("https://www.tuicool.com/");
//这里的地址网站有反爬虫的设计,下面是对反爬虫的处理
//方法一,最简单的是对请求头进行伪装,伪装成浏览器
// request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");
//设置请求头,将爬虫伪装成浏览器
request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");
//如果你伪装了之后,如果短时间内一直多次访问的话,网站会对你的ip进行封杀,这个时候就需要换个ip地址了,使用代理IP
HttpHost proxy = new HttpHost("112.85.168.223", 9999);
RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
request.setConfig(config);
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
System.out.println(html);
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
}
使用jsoup解析html
jsoup 是一款 Java 的 HTML 解析器,可直接解析某个 URL 地址、HTML 文本内容。它提供了一套非常省力的 API,可通过 DOM,CSS 以及类似于 jQuery 的操作方法来取出和操作数据。
详情可以参考博客https://blog.csdn.net/weixin_44540681/article/details/116378094
导入依赖
<dependency>
<!-- jsoup HTML parser library @ htt p://jsoup.org/ -->
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.2</version>
</dependency>
以爬取https://taolitop.com/为例,我们之前已经获取了html代码,我们现在只想要获取图片资源
我们修改一下上面的代码(使用jsoup)
Document doc = Jsoup.parse(html);
Elements links = doc.getElementsByTag("img");
for (Element link : links) {
String linkHref = link.attr("src");
linkHref = "https://taolitop.com" +linkHref;
System.out.println(linkHref);
}
public class HttpClientTest {
public static void main(String[] args) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet("https://taolitop.com/");
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
// System.out.println(html);
Document doc = Jsoup.parse(html);
Elements links = doc.getElementsByTag("img");
for (Element link : links) {
String linkHref = link.attr("src");
linkHref = "https://taolitop.com" +linkHref;
System.out.println(linkHref);
}
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
}
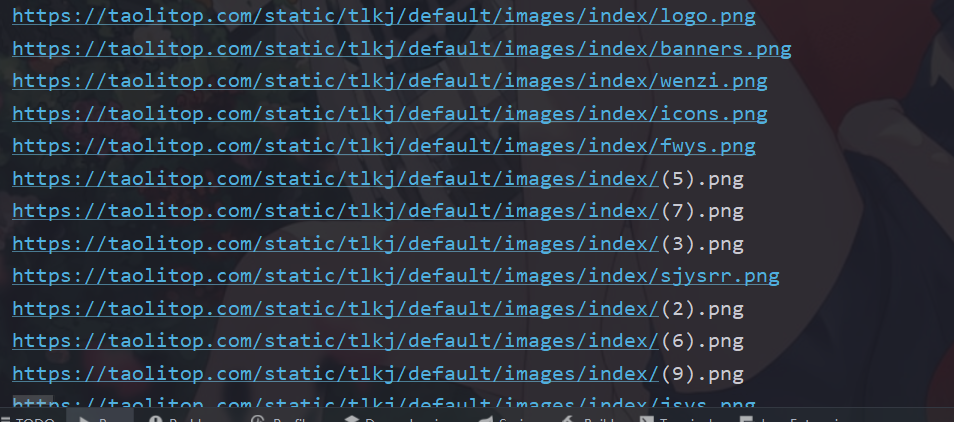
我们现在就获取了全部的图片资源