导语
这篇博客主要是为大家分享一下关于Kafka集群消息的处理与集群的维护,之前的博客中简单的描述了Kafka的基本的原理以及集群架构,这篇博客主要是详细介绍一下Kafka集群的消息处理以及集群的维护
Kafka消息组织原理
&emep;在大学时候学习计算机组成原理的时候都接触过下面这张图
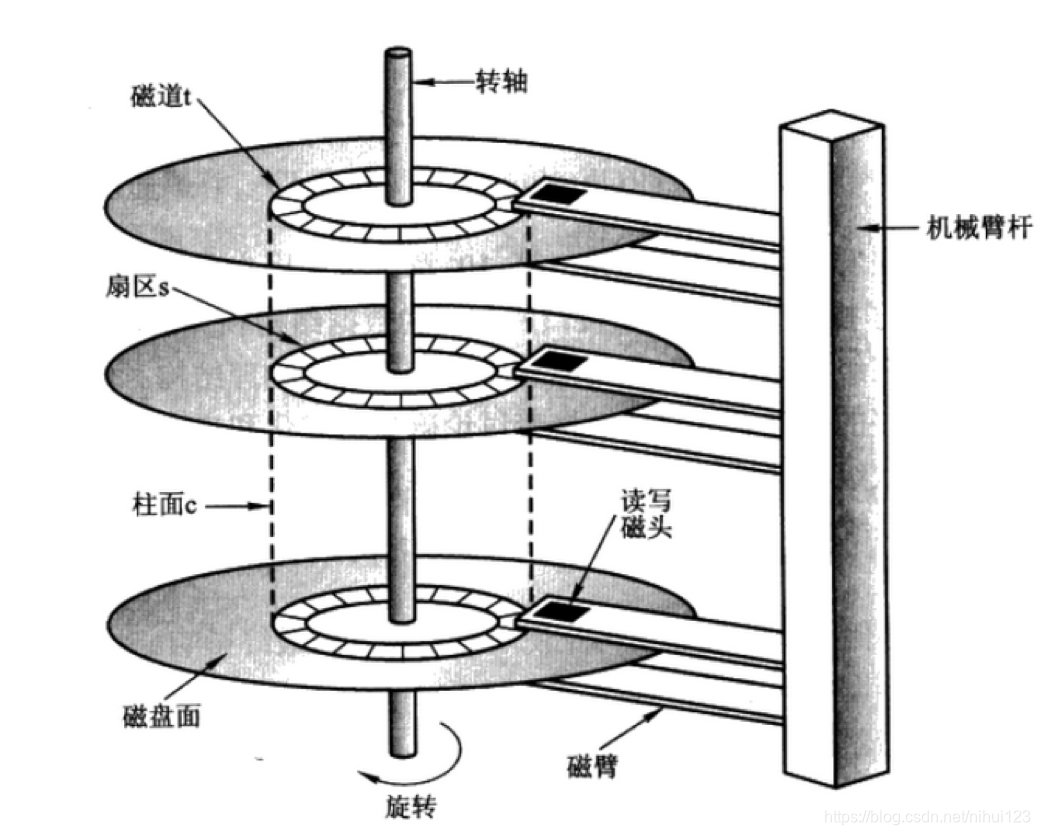
从上面这张图中可以详细的看到我们普通的磁盘的内部结构,在服务器中使用的磁盘也是这样样子的,数据通过磁盘面进行记录数据。通过转轴的旋转以及磁头的上下跳动来进行数据的读写操作,说是跳动是有点夸张了,但是原理就是这样子。那么这个与Kafka又有什么关系呢?下面就来详细介绍一下工作原理。
当从磁盘中读取数据的时候,首先需要确定的就是数据在哪个磁盘面上,哪个扇区,然后从最开始进行遍历。
- 1、第一步就是磁头进行巡道,也就是找到在哪个磁道上,找到在哪个磁道上就需要消耗时间去进行旋转。
- 2、第二步 找到目标扇区,磁头上下进行读写操作。
- 3、第三步 数据在磁盘内存网络三者之间进行传输。
通过上面的分析可以看出,整个的磁盘的存储是比较耗时的一件事情,虽然现在的磁盘转速在不断的提高,但是与CPU的运算速度还是不能相提并论的。这个时候就出现了一个Cache,对于缓存来讲,就是用来解决处理速度不匹配的问题,这个在之前的博客中多次提到。很多的场景下使用缓存都是为了解决处理能力不对等的问题。
怎么样解决这个问题?
从数据的角度上来说有以下的两种解决方案
- 1、提前读
- 2、合并写
也就是说,采用磁盘顺序读写(省去了巡道的时间),根据有人统计,在一个67200rpm SATA RAID-5 的磁盘阵列上线性写的速度大概是300M/秒,但是随机写的速度只有50K/秒,两者的差距还是比较大的。
了解完磁盘的读写原理之后,再来了解一下kafka的读写原理
Kafka消息的写入操作原理
一般的情况下,将数据传输到套接字路径有以下的集中方式,也是LinuxIO的操作原理
- 1、操作系统将数据从磁盘读取到内核空间缓存页中,数据由磁盘状态改变为内核状态。
- 2、应用将数据从内核空间中读取到用户空间,也就是从内核态变为用户态
- 3、应用数据将数据写入到内存空间的套接字缓存中
- 4、操作系统将数据从套接字缓存中写入到网卡缓存中,通过网卡将数据发送出去。
通过上面的描述明显可以感觉到,从内核状态到用户状态,一共有四次拷贝,两次的系统调用。如果使用sendfile,两次拷贝可以避免;允许操作系统直接从缓存页发送到网络中,优化之后,只需要最后一步将数据拷贝到网卡中就可以了。
Kafka topic信息

Kafka消息文件存储
Kafka消息删除原理
Kafka对于消息的删除是从最久的日志段开始删除,也就是说按照日志段删除,直到某个日志段不满足条件为止,删除的条件如下
- 满足给定条件predicate(配置项log.retention.{ms,minutes,hours}和log.retention.bytes指定);
- 不能是当前激活日志段
- 大小不能小于日志段的最小大小(配置项log.segment.bytes配置)
- 要删除的是否是有日志段,如果是的话直接调用roll方法进行切分在Kafka中至少要保留一个日志段。

Kafka消息检索原理
Segment file 组成和物理结构
Partition file
分区文件存储方式,在kafka集群中,每个broker(一个kafka实例称为一个broker)中有多个topic,topic数量可以自己设定。在每个topic中又有多个partition,每个partition为一个分区。kafka的分区有自己的命名的规则,它的命名规则为topic的名称+有序序号,这个序号从0开始依次增加。
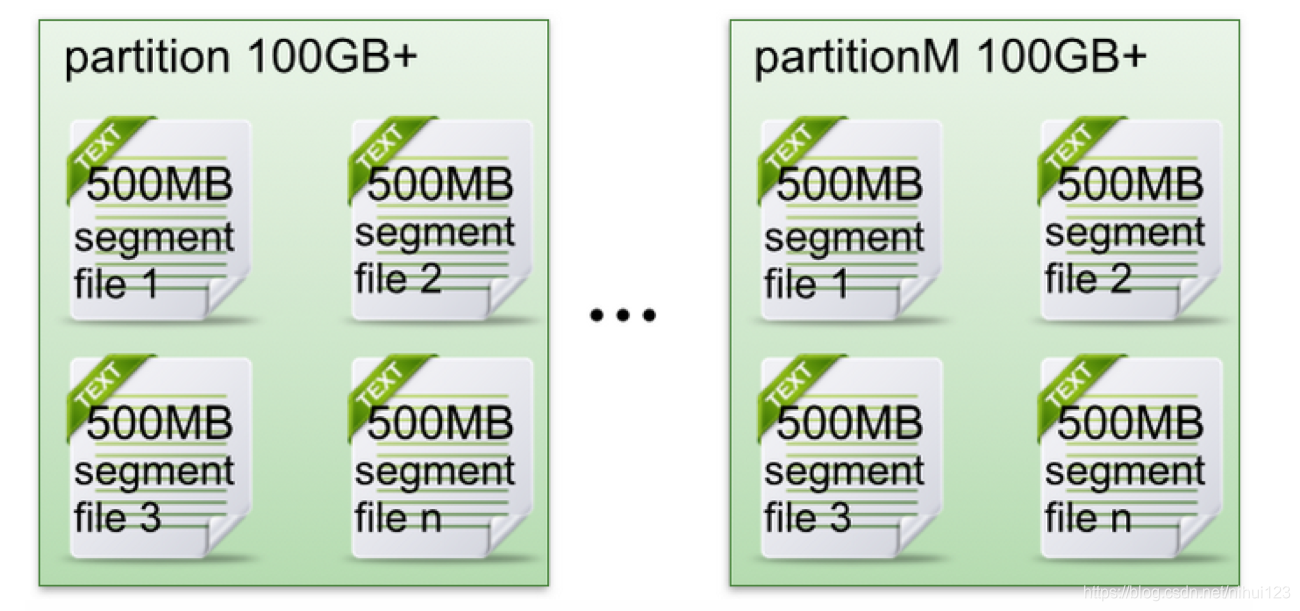
Segment file
在每个partition中有可以分为多个segment file。当生产者往partition中存储数据时,内存中存不下了,就会往segment file里面存储。kafka默认每个segment file的大小是500M,在存储数据时,会先生成一个segment file,当这个segment file到500M之后,再生成第二个segment file 以此类推。每个segment file对应两个文件,分别是以.log结尾的数据文件和以.index结尾的索引文件。在服务器上,每个partition是一个文件夹,每个segment是一个文件。这个文件类似于在上面看到的文件存储内容。
消息的物理结构

说明
| 内容 | 描述 |
|---|---|
| 8 byte offset | 表示partition的第多少message |
| 4 byte message size | Message 大小 |
| 4 byte CRC32 | CRC32校验 |
| 1 byte “magic” | 本次发布Kafka服务程序协议版本号 |
| 1 byte “attributes” | 独立版本、或标识压缩类型、或编码类型 |
| 4 byte key length | key的长度,当key为-1时,K byte key 字段不填 |
| K byte key | 选填 |
| value bytes length | 实际消息数据 |
| payload | 实际消息 |
index file 组成和物理结构
Partition file 存储方式

Index file 和date file

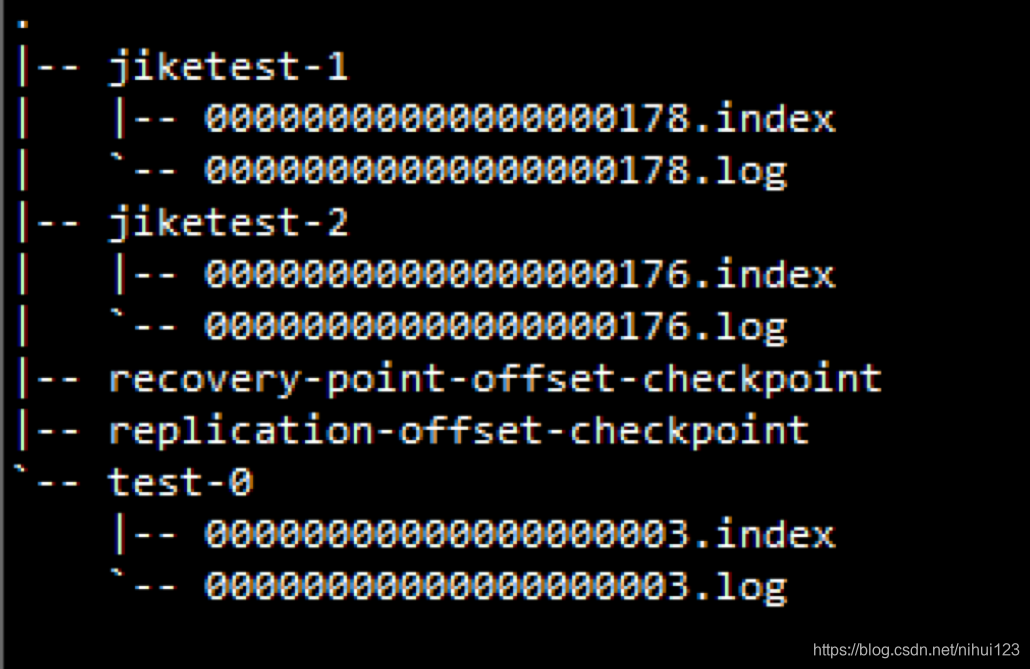
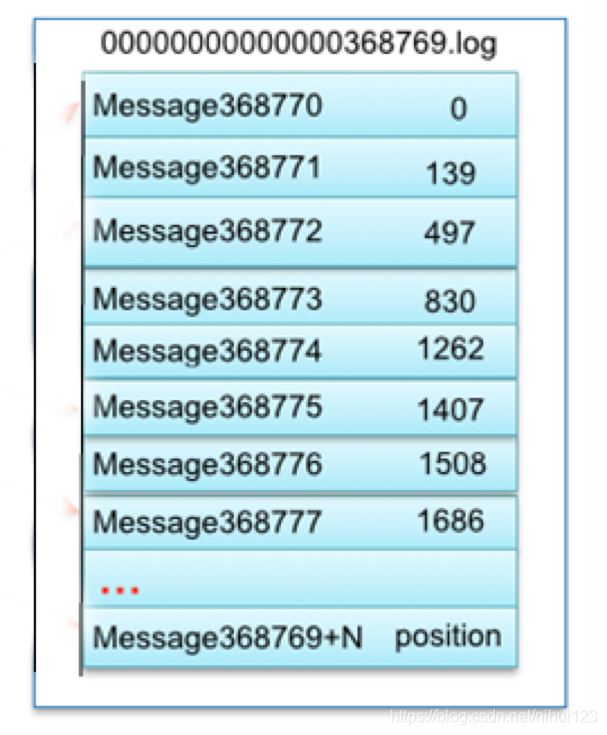
每个segment file也有自己的命名规则,每个名字有20个字符,不够用0填充。每个名字从0开始命名,下一个segment file文件的名字就是,上一个segment file中最后一条消息的索引值。在.index文件中,存储的是key-value格式的,key代表在.log中按顺序开始第条消息,value代表该消息的位置偏移。但是在.index中不是对每条消息都做记录,它是每隔一些消息记录一次,避免占用太多内存。即使消息不在index记录中,在已有的记录中查找,范围也大大缩小了
以上面读取offset=368776的message为例,需要通过如下的步骤进行查找
- 第一步
第一个00000000000000000000.index 标识最开始的文件,起始偏移量为0,第二个文件00000000000000368769.index 的消息量起始偏移量为368770=368769+1,只要根据offset二分法查找文件列表,就可以快速定位到具体文件,当offset=368776时定位到00000000000000368769.index|log - 第二步 通过segment file 查找message;
算出368776-368770=6,取00000000000000368769.index文件第三项(6,1407),得出从00000000000000368769.log文件头偏移1407字节读取一条消息即可
总结
到这里整个的Kafka消息处理机制底层原理就描述完了,从简单的开始到复杂的Kafka数据存储。从这里也可以体会到kafka消息处理的优势,通过本次的分享也对自己对于kafka的理解更近一步。更加深入的理解了kafka底层原理