消费端如何指定消费的分区
通过下面的代码,就可以消费指定该 topic 下的 0 号分区。其他分区的数据就无法接收
// 消费指定分区的时候,不需要再订阅
//kafkaConsumer.subscribe(Collections.singletonList(topic));
// 消费指定的分区
TopicPartition topicPartition=newTopicPartition(topic,0);
kafkaConsumer.assign(Arrays.asList(topicPartition));
消息的消费原理
在实际生产过程中,每个 topic 都会有多个 partitions。多个 partitions 的好处在于,
一方面能够对 broker 上的数据进行分片有效减少了消息的容量从而提升 io 性能。
另外一方面,为了提高消费端的消费能力,一般会通过多个consumer 去消费同一个 topic ,也就是消费端的负载均衡机制
在多个 partition 以及多个 consumer 的情况下,消费者是如何消费消息的?
kafka 存在 consumer group的概念,也就是 group.id 一样的 consumer,这些consumer 属于一个 consumer group,组内的所有消费者一起来消费订阅主题的所有分区。每一个分区只能由一个消费组内的某一个 consumer 来消费。
同一个consumer group 里面的 consumer 是怎么去分配该消费哪个分区里的数据的呢?如下图所示 有三个分区三个消费者,哪个消费者消分哪个分区?
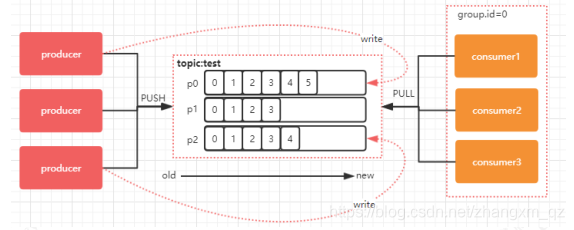
对于上面这个图来说,这 3 个消费者会分别消费 这个topic 的 3 个分区,也就是每个 consumer 消费一个partition,
如果有三个分区 四个消费者 那么会有一个消费者消费不到消息。为什么会这样?
在 kafka 中,存在两种分区分配策略,一种是 Range(默认)、另 一 种 是 RoundRobin ( 轮 询 )。 通 过partition.assignment.strategy 这个参数来设置。
Range strategy(范围分区)
Range 策略是对每个主题而言的,首先对同一个主题里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。假设我们有 10 个分区,3 个消费者,排完序的分区将会是 0, 1, 2, 3, 4, 5, 6, 7, 8, 9;消费者线程排完序将会是C1-0, C2-0, C3-0。然后将 partitions 的个数除于消费者线程的总数来决定每个消费者线程消费几个分区。如果除不尽,那么前面几个消费者线程将会多消费一个分区。
假设我们有 10 个分区,3 个消费者,排完序的分区将会是 0, 1, 2, 3, 4, 5, 6, 7, 8, 9;消费者线程排完序将会是C1-0, C2-0, C3-0。然后将 partitions 的个数除于消费者线程的总数来决定每个消费者线程消费几个分区。如果除不尽,那么前面几个消费者线程将会多消费一个分区。在我
们的例子里面,我们有 10 个分区,3 个消费者线程, 10 /3 = 3,而且除不尽,那么消费者线程 C1-0 将会多消费一个分区,所以最后分区分配的结果是这样的:
C1-0 将消费 0, 1, 2, 3 分区
C2-0 将消费 4, 5, 6 分区
C3-0 将消费 7, 8, 9 分区
假如我们有 2 个主题(T1 和 T2),分别有 10 个分区,那么最后分区分配的结果是这样的:
C1-0 将消费 T1 主题的 0, 1, 2, 3 分区以及 T2 主题的 0,1, 2, 3 分区
C2-0 将消费 T1 主题的 4, 5, 6 分区以及 T2 主题的 4, 5,6 分区
C3-0 将消费 T1 主题的 7, 8, 9 分区以及 T2 主题的 7, 8,9 分区
可以看出,C1-0 消费者线程比其他消费者线程多消费了 2 个分区,这就是 Range strategy 的一个很明显的弊端
RoundRobin strategy(轮询分区)
轮询分区策略是把所有 partition 和所有 consumer 线程都列出来,然后按照 hashcode 进行排序。最后通过轮询算法分配 partition 给消费线程。如果所有 consumer 实例的订阅是相同的,那么 partition 会均匀分布。
比如有2个消费者C0和C1,都订阅了主题t0和t1,并且每个主题都有3个分区,那么所订阅的所有分区可以标识为:t0p0、t0p1、t0p2、t1p0、t1p1、t1p2。最终的分配结果为:
消费者C0:t0p0、t0p2、t1p1
消费者C1:t0p1、t1p0、t1p2
使用轮询分区策略必须满足两个条件:
- 每个主题的消费者实例具有相同数量的流
- 每个消费者订阅的主题必须是相同的
什么时候会触发这个分区分配策略?
当出现以下几种情况时,kafka 会进行一次分区分配操作,也就是 kafka consumer 的 rebalance
- 同一个 consumer group 内新增了消费者
- 消费者离开当前所属的 consumer group,比如主动停机或者宕机
- topic 新增了分区(也就是分区数量发生了变化)
kafka 提供了可插拔的实现方式,除了这两种之外,我们还可以创建自己的分配机制。
谁来执行 Rebalance 以及管理 consumer 的 group
Kafka提供了一个角色:coordinator来执行对于consumergroup 的管理,当 consumer group 的第一个 consumer 启动的时候,它会去和 kafka server 确定谁是它们组的 coordinator。之后该 group 内的所有成员都会和该 coordinator 进行协调通信。
如何确定确定coordinator
当 consumer group 的第一个 consumer 启动时会向 kafka 集群中的任意一个 broker 发送一个GroupCoordinatorRequest 请求,服务端会返回一个负载最 小的 broker 节 点的 id,并将该 broker 设 置为该组的coordinator.
JoinGroup 的过程
在 rebalance 之前,需要保证 coordinator 是已经确定好了的,整个 rebalance 的过程分为两个步骤,Join 和 Sync。
join阶段: 表示加入到 consumer group 中,在这一步中,所有的成员都会向 coordinator 发送 joinGroup 的请求。一旦所有成员都发送了 joinGroup 请求,那么 coordinator 会选择一个 consumer 担任 leader 角色,并把组成员信息和订阅信息发送消费者。如下图:
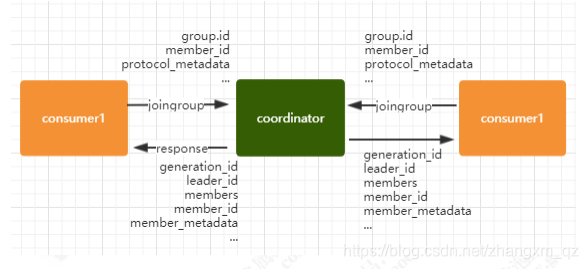
protocol_metadata: 序列化后的消费者的订阅信息
leader_id: 消费组中的消费者,coordinator 会选择一个作为 leader,对应的就是 member_id
member_metadata: 对应消费者的订阅信息
members:consumer group 中全部的消费者的订阅信息
generation_id: 年代信息,类似 zookeeper 中的 epoch 是一样的,对于每一轮 rebalance,generation_id 都会递增。主要用来保护 consumer group。隔离无效的 offset 提交。也就是上一轮的 consumer 成员无法提交 offset 到新的 consumer group 中。
sync阶段:
主 要 逻 辑 是 向 GroupCoordinator 发 送SyncGroup 请求,并且处理 SyncGroup响应,简单来说,就是 leader 将消费者对应的 partition 分配方案同步给 consumer group 中的所有 consumer。

每个消费者都会向 coordinator 发送 syncgroup 请求,不过只有 leader 节点会发送分配方案,其他消费者只是打酱油而已。当 leader 把方案发给 coordinator 以后,coordinator 会把结果设置到 SyncGroupResponse 中。这样所有成员都知道自己应该消费哪个分区。
consumer group 的分区分配方案是在客户端执行的!Kafka 将这个权利下放给客户端主要是因为这样做可以有更好的灵活性。
如何保存消费端的消费位置
什么是 offset
每个 topic可以划分多个分区(每个 Topic 至少有一个分区),同一topic 下的不同分区包含的消息是不同的。每个消息在被添加到分区时,都会被分配一个 offset(称之为偏移量),它是消息在此分区中的唯一编号,kafka 通过 offset 保证消息在分区内的顺序,offset 的顺序不跨分区,即 kafka 只保证在同一个分区内的消息是有序的; 对于应用层的消费来说,每次消费一个消息并且提交以后,会保存当前消费到的最近的一个 offset。
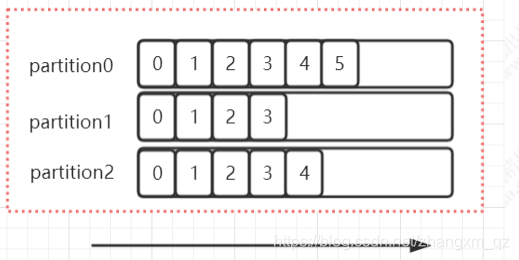
offset 在哪里维护?
在 kafka 中,提供了一个__consumer_offsets_* 的一个topic , 把 offset 信 息 写 入 到 这 个 topic 中 。__consumer_offsets保存了每个 consumer group某一时刻提交的 offset 信息。 __consumer_offsets 默认有50 个分区。
根 据 前 面 我 们 演 示 的 案 例 , 我 们 设 置 了 一 个KafkaConsumerDemo 的 groupid。首先我们需要找到这个 consumer_group 保存在哪个分区中
查看方式
1)找到分组偏移量的分片值:Math.abs(“groupid”.hashCode())%groupMetadataTopicPartitionCount (默认为50) ;
由 于 默 认 情 况 下groupMetadataTopicPartitionCount 有 50 个分区,计算得到的结果为:35, 意味着当前的consumer_group的位移信息保存在__consumer_offsets 的第 35 个分区。
2)执行如下命令,可以查看当前 consumer_goup 中的offset 位移信息
sh kafka-simple-consumer-shell.sh --topic __consumer_offsets --partition 35 --broker-list 192.168.11.153:9092,192.168.11.154:9092,192.168.11.157:9092 --formatter “kafka.coordinator.group.GroupMetadataManager$OffsetsMessageFormatter”