版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
课程链接:阿里云大学_分布式系统开发-调度技术
分布式调度的主要作用
像使用台式机一样使用云计算
分布式调度能将成千上万台硬件的运算能力汇合起来,提供可靠的云计算服务
分布式调度的两大任务
任务调度
在分布式系统中存在大量计算任务,这其中涉及了以下几个问题:
- 任务如何切分?
- 数据如何分割、运算?
- 如何监控运算状态?
资源调度
资源调度属于业务供给方的问题
- 如何平衡业务之间的资源分配?
- 如何支持优先级抢占?
分布式调度系统的比较
Hadoop MapReduce
这是Hadoop 1.X版本中采用的调度系统。
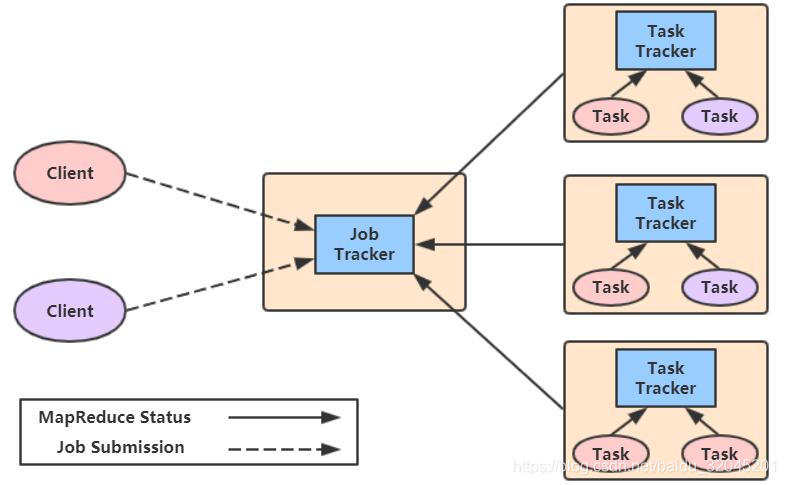
- Job Tracker:即负责资源调度,也负责任务调度
- Task Tracker:负责任务调度,和执行任务
这是一个典型的主从架构,同时其中存在很严重的缺陷:
- 规模扩展存在瓶颈,最大4000台:因为Task Tracker注册到Job Tracker需要消耗Job Tracker的内存资源,因此规模扩展到瓶颈就在于Job Tracker的内存上限
- 容错性差,Job Tracker单点没有failover:Job Tracker是一个单节点进程,如果Job Tracker进程崩溃或是其所在的服务器宕机,会导致丢失全部作业情况和资源分配信息
- 不利于功能扩展,不同任务采用不同的调度策略:无法支持热拔插(即在不停止进程的情况下,改变系统的调度行为)
YARN
YARN(Yet Another Resource Negotiator),是为了解决Hadoop 1.X中资源调度的缺陷,而在Hadoop 2.X中进行改进的资源调度系统
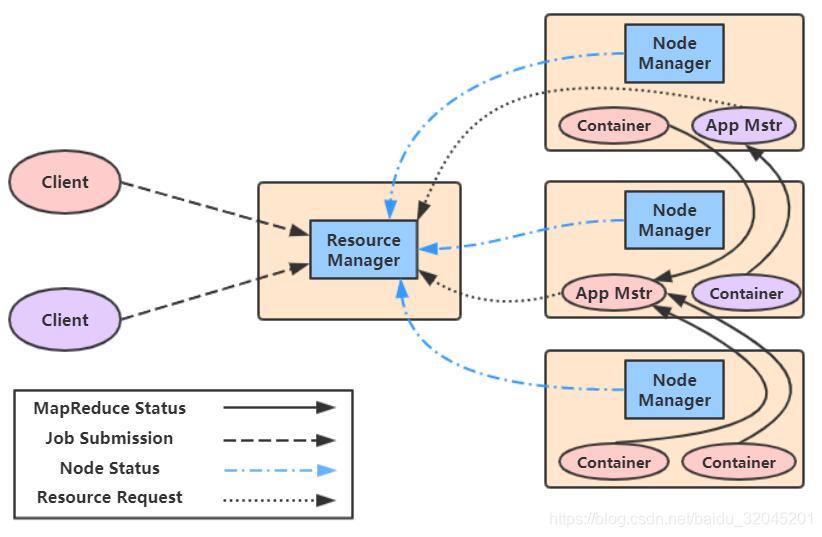
YARN与Hadoop MapReduce的区别在于:
- 将资源调度与任务调度做了区分:当用户提交任务到Resource Manager后,Resource Manager只做资源调度,并将调度结果发送给Application Master,接着Application Master做任务调度,它将决定在哪些节点上运行作业
- 能支撑起更大的运算规模
但是YARN还是存在一些缺陷:
- Resource Manager目前仅支持memory调度:它无法支持CPU,磁盘,网络等调度。调度是一个背包问题,只考虑内存调度时,调度是一维线性规划问题;若增加资源时,调度是高维背包问题
- 资源交互性能:Node Manager执行完作业后会立即将资源归还给Resource Manager,这样一来,如果还有等待运行的作业时,还需要重新经历一边资源调度过程,增加了交互链路,降低性能
Mesos
Mesos最初时由加州伯克利分校的AMPLab开发,后来由于作者加入了Twitter,Mesos得以在Twitter广泛应用
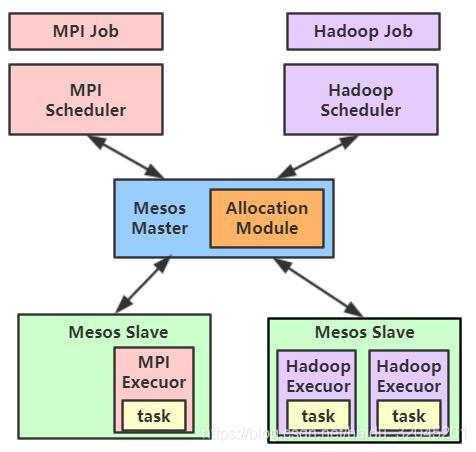
存在的问题:
- scheduler与Mesos Master之间不能描述精确的资源需求
- 一次资源分配需要两次通信交互(offer & accept),调度效率低
- 不支持资源抢占
Aliyun-Fuxi
伏羲系统时阿里巴巴自主研发的分布式调度系统
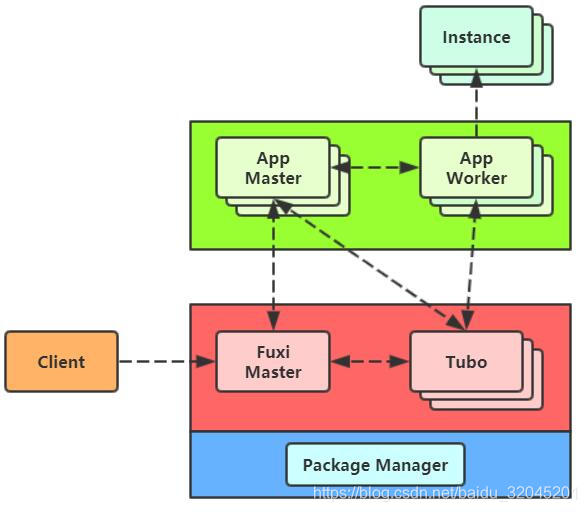
- Fuxi Master:负责中心资源调度
- Tubo:每个节点都有,负责管理用户进程和获取节点硬件资源信息,并发送给Fuxi Master
- Package Manager:当用户使用飞天系统提供的SDK完成自己的MR作业后,将作业编译并打包发送到Package Manager,当用户进行后续作业时,Tubo会知道作业存储位置,并从Package Manager上下载并解压,然后拉起用户进程
伏羲系统运行流程:
- 用户提交一个任务到Fuxi Master
- Fuxi Master找到一个较为空闲的节点并启动App Master
- App Master启动后会向Fuxi Master发起一个资源请求,其中资源请求的描述形式十分丰富,这样能够避免Master系统中资源交互链路较长的问题,准确描述所需资源的要求
- Fuxi Master收到请求后,会在毫秒级时间内响应,并分配资源
- App Master收到分配的资源后就会知道在哪些节点上可以启动App Worker,于是它会通知响应节点上的Tubo进程拉起一个App Worker
- App Worker进程被拉起后,会到App Master进行注册,告知其可以运行
- App Master会向App Worker下发一个Instance,其中包括数据分片,存储位置,处理结果等信息
伏羲系统相关资料: