CNN卷积神经网络原理详解(中)
卷积神经网络与全连接神经网络的比较
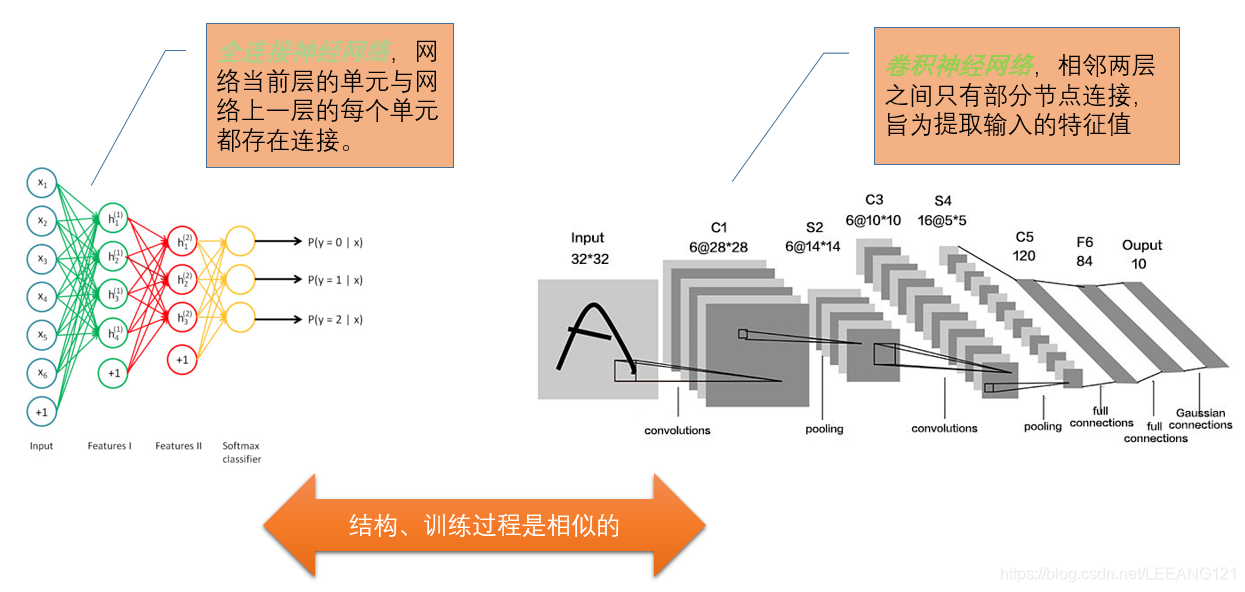
卷积神经网络(Convolutional Neural Network,CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。 它包括卷积层(convolutional layer)和池化层(pooling layer)。
名词解释
前馈神经网络
前馈神经网络是一种最简单的神经网络,各神经元分层排列。每个神经元只与前一层的神经元相连。接收前一层的输出,并输出给下一层.各层间没有反馈。是目前应用最广泛、发展最迅速的人工神经网络之一。研究从20世纪60年代开始,目前理论研究和实际应用达到了很高的水平。
卷积运算的数学解释
为什么用卷积运算
通常情况下,卷积是对两个实变函数的一种数学运算。首先我们从一个例子出发给我卷积的定义。
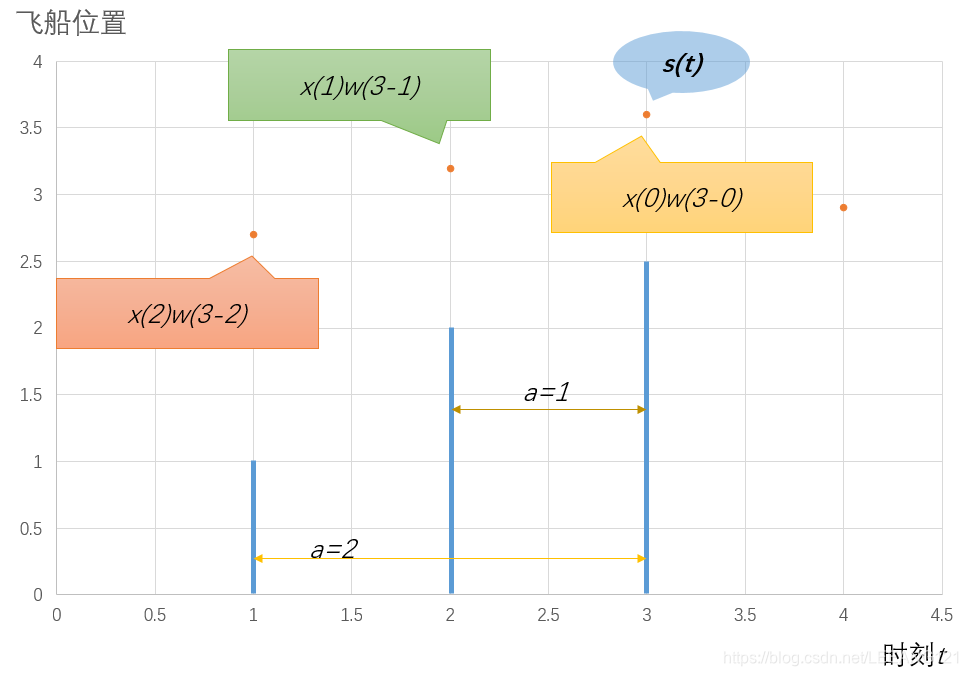
假设我们正在用激光传感器追踪一艘宇宙飞船的位置。我们的激光传感器给出一个单独的输出x(t),表示宇宙飞船在时刻t的位置。x和t都是实值,这意味着我们可以再任意时刻从传感器读出飞船的位置。
现在假设我们的传感器收到一定程度的噪声干扰。为了得到飞船位置的低噪声估计,我们对得到的测量结果进行平均。显然,时间上越接近的测量结果越相关,所以我们采用一种加权平均的方法,对于最近的测量结果赋予更高的时间间隔。我们可以采用一个加权函数
来实现,其中
表示测量结果距当前时刻的时间间隔。如果我们对任意时刻都采用这种加权平均的操作,就得到了一个新的对于飞船位置的平滑估计函数
:
简单的解释一下:
:
时刻宇宙飞船的位置(我们要求的目标)
: 我们令
,则
表示
时刻飞船的位置(该位置包含了噪音,因此不是精确的位置)
:表示
时刻飞船在该位置的可能性,也可以成为比重
最终我们将宇宙飞船从
时刻到
时刻的过程中,每一个时刻测量到的位置再乘以测量时刻该位置所占比重相乘并将结果相加,最终得到一个结果,我们认为是飞船
时刻一个较为准确的位置。
我们把这种运算成为卷积,卷积运算通常用星号表示:
在本例中,激光传感器在每个瞬时反馈测量结果明显是不切实际的。通常我们处理计算机的数据时,时间会被离散化,传感器会定期的传输数据。在本例中,假设传感器每秒反馈一次信息是比较理想的。这样,时刻
只能取整数值。如果假设
和
都定义在时刻
上,就可以定义离散形式的卷积:
我们用到的卷积形式
在机器学习的应用中,输入通常是多维数组的数据,而核通常是由学习算法优化得到的多维数组的参数。我们把这些多维数组叫做张量。由于输入与核的每一个元素都必须明确的分开存储,我们通常假设在存储了数值的有限点集以外,这些函数的值都为零。这就意味着在实际的操作过程中,我们可以通过对有限个数组元素的求和来实现无限求和。
我们经常一次在多个维度上进行卷积运算,例如,如果把一张二维的图像
作为输入,那么为了数学模型可以计算,我们的核
也必须是一个二维数组:
简单解释一下:
:在二维数组中,我们想要得到在坐标
处的值(参照
)
:在二维数组中,在坐标
处的测量值,参照
:与目标位置(
)相距(
)处位置的坐标代表的值所占比重,参照

卷积计算的工作模式
何为卷积?
卷积就是在原始的输入中进行特征的提取。提取过程分区域,一块一块的提取。并且根据卷积层的递增,提取的特征也由最基本的点、线、面变成了可以分别事物的具化的特征,例如汽车的轮胎、猫的耳朵等。
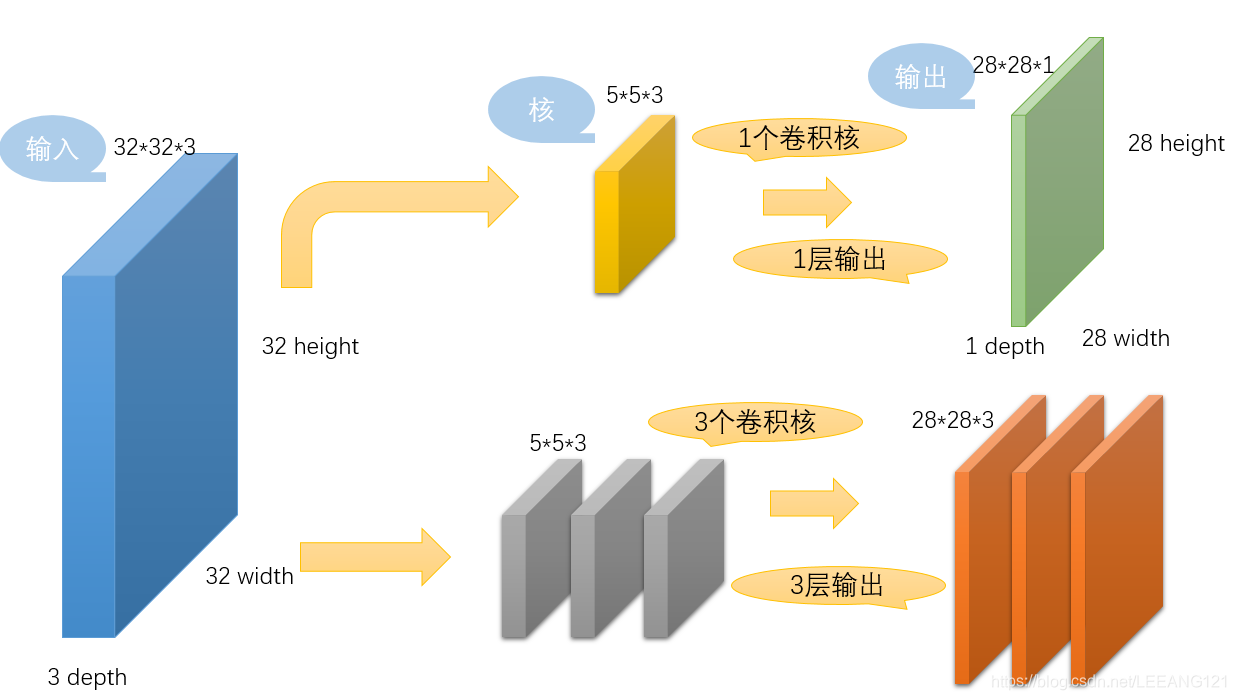
上图中最左边的方块是输入,尺寸是3232的3通道图像。中间黄色方块是一个卷积核,尺寸是55,该尺寸是一个设定值,深度和输入一样都为3(这里深度必须和输入深度相同,否则数学上无法计算)。最终输出是一个特征图,尺寸为2828。
中间灰色方块是3个卷积核,尺寸与上面黄色方块相同,但是数量是3,因此输出是3个特征图,尺寸为2828。
tips:
卷积操作不仅可以对原始输入层执行,对于经过卷积操作的层,也可以再次使用。但是核的输入一定要与上一层的深度相同。

简单解释
第一次卷积可以提取出低层次的特征。
第二次卷积可以提取出中层次的特征。
第三次卷积可以提取出高层次的特征。
特征是不断进行提取和压缩的,最终能得到比较高层次特征,简言之就是对原式特征一步又一步的浓缩,最终得到的特征更可靠。利用最后一层特征可以做各种任务:比如分类、回归等。
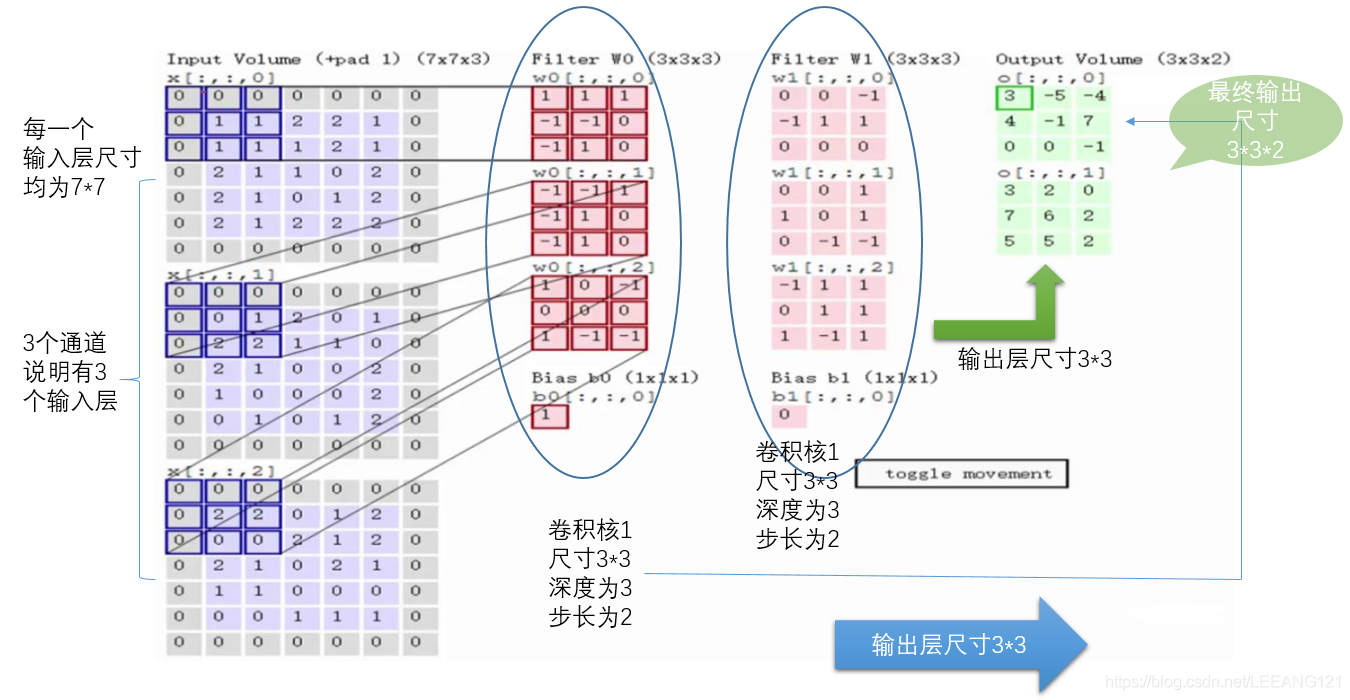
具体计算步骤
输入是固定的,filter(核)是指定的,因此计算就是如何得到绿色矩阵。第一步,在输入矩阵上有一个和filter相同尺寸的滑窗,然后输入矩阵的元素在滑窗里的部分与filter矩阵对应位置相乘,具体过程见下图:
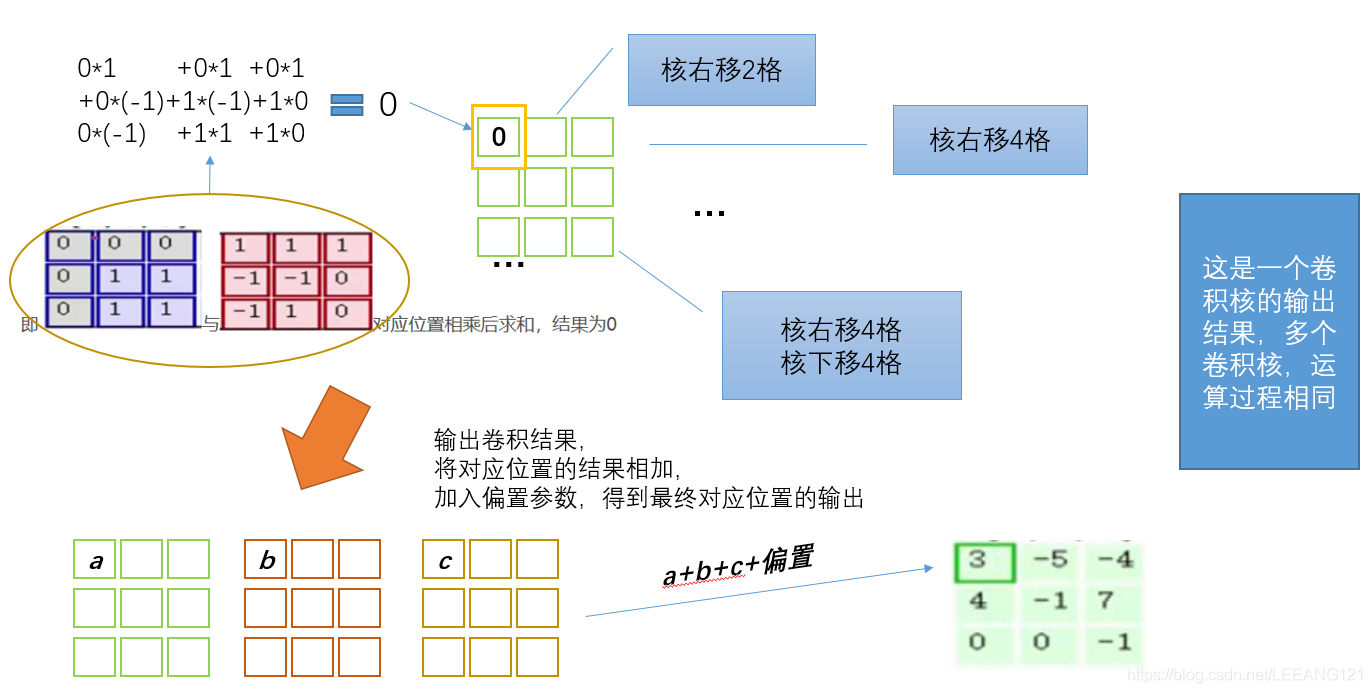
那么针对不同的卷积输入和卷积核,每次输出的尺寸是多少?我们可以参考如下公式
输出的尺寸=(输入的尺寸-核的尺寸+2*填充尺寸)÷步长+1
具体大家可以自己研究。
从上面的卷积过程,我们还可以发现一个重要特征,在同一层的卷积计算,我们使用的是相同的卷积核。这是卷积的一重要特点,参数共享。参数共享可以极大的减少参数数量。
池化
卷积是为了提出特征值,那么搞完了卷积,我们就该整理这些特征值了。首先就是从这些特征值里面筛选更有特征的特征值。。。就是我们将要说的池化操作。没错,池化就是想要把卷积输出的数组尺寸近一步缩小。常用的池化有平均值池化、最大值池化。我们以最大值池化为例做一个简要说明,看完大家自然就明白平均值池化的意思了。

从上图可以看出,池化的结构和卷积一样,都是在输入的数组内以一个指定的大小扫描全图,但是池化不用计算,只做筛选。最大池化就是筛选出区域内最大值,平均池化就是计算区域的平均值。