目录
1.1 StreamExecutionEnvironment 运行环境
1.3 流处理过程和Sink输出---flatMap,keyBy,sum,print
本文将以flink-1.5.6, org.apache.flink.streaming.examples.wordcount.WordCount 作为案例程序进行分析。
wordcount的代码逻辑如下:
- 1.创建StreamExecutionEnvironment
- 2.创建DataStreamSource(Source)
- Source表示flink的数据输入流
- 3.增加对Source的操作
- 每一个操作都会产生一个新的DataStream,然后增加对新的DataStream的操作,形成流的处理逻辑
- 4.最后一个DataStream增加Sink
- Sink代表流处理逻辑的最终输出
- 5.执行env.execute()启动flink job
一.wordcount代码逻辑分析
1.1 StreamExecutionEnvironment 运行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();flink的上下文,负责flink的默认配置,当前运行环境,例如取cpu核数为默认并行度,flink的启动方法execute等。同时,运行环境负责保存我们对流处理的操作,Source->Operator->Sink整个阶段和每个阶段的返回值类型,上下游关系等。
1.2 DataStreamSource 流数据源
text = env.fromElements(WordCountData.WORDS);DataStreamSource 是flink流计算的开始,和其他流基本相同。其源码主要实现了一下几个功能:
- 1.使用TypeExtractor获得DataStreamSource的输出数据类型 这里是String
- 2.创建SourceFunction,使用SourceFunction创建并初始化SourceOperator
- 3.根据SourceOperator创建并初始化SourceTransformation,
- 4.使用SourceTransformation创建并初始化DataStreamSource
| 名词 | 解释 |
| TypeExtractor | 是flink实现的序列化机制中的一个class,和TypeHint一起,专门用于获得泛型类接收的数据类型,然后根据基本类型,数组类型,常用类型,POJO类,Tuple类等,使用不同的序列化和反序列机制处理,需要配置类型判断一起处理,因为用户自定义的类很多情况下flink无法自动识别 |
| Function | 流数据的基本处理单元,数据处理逻辑封装在function中,例如:SourceFunction封装Source中用来获取数据的代码,FlatMapFunction封装了处理数据FlatMap逻辑的代码 |
| Operator | 流操作,将一个Function封装为不同类型的Operator,例如:单输出Operator OneInputStreamOperator ,双输出Operator TwoInputStreamOperator等,是function的不同输出类型的处理逻辑封装。 |
| Transformation | 转换,将Operator封装为Transformation,用于形容一组类型的输入,经过Transformation以后,出来一组不同类型的输出。是Operator的更高级封装,也可以分为单输出,双输出,Source,sink等多种Transformation |
| DataStream | DataStream代表一个数据流,里面封装transformation,表示流的处理逻辑。还有若干基于该流往下游的方法。例如map,flatmap。 |
| SourceFunction | Function的一种封装,负责Source处理逻辑的Function,例如FromElementsFunction,看了一下,SourceFunction的实现,flink源码中就有22种 |
| SourceOperator | Operator的一种封装,封装SourceFunction的Operator,可以封装不同的SourceFunction |
| SourceTransformation | Transformation的一种实现,负责封装不同类别的SourceOperator |
| DataStreamSource | 数据流的一种实现,表示数据流计算的起点,里面封装了SourceTransformation |
1.3 流处理过程和Sink输出---flatMap,keyBy,sum,print
从Source到Sink中间的处理阶段,这个阶段的方法分两种:
- 1.处理数据的方法
- 2.不处理数据的方法
当然,上面是博主自己的理解,不是官方说的。为什么这么分,因为例如flatMap,中间是有数据处理逻辑的,将一行数据扁平化为多行,但是像keyBy,equalTo,partition,rebanlance等方法,其实是没有对数据进行修改的,起的是一个按字段匹配,分发的作用,这写方法,不会被计入Operator。
flatMap的逻辑
代码这里就不贴了,一路点进去是很清晰的。大体逻辑如下:
- 1.根据FlatMapFunction的泛型获得返回值类型outType,这里是 Java Tuple2<String, Integer>
- 2.将Function转化为Operator,和上面的outType一起传入transform方法
transform方法是公共方法,主要做下面的几件事情:
- 1.transform根据当前流的transformation和Operator对象获得flatmap的Transformation对象
- 2.根据flatmap的transformation对象,创建返回的DataStream
- 3.将flatmap的transformation对象,添加到StreamExecutionEnvironment的数组transformations中。
上述过程中,首先,将当前流this.transformation和Operator用于构造flatmap的Transformation对象,每一个transformation对象都会记录一个input,即当前流this.transformation,表示当前转换的上游转换,这样的情况下,只需要获得所有的Thransformation对象,就可以根据input知道他们之间的上下游关系了,2,3将transformation封装在DataStream中,并且添加到StreamExecutionEnvironment中,这样,每个DataStream都封装了自己的处理逻辑(transformation<-Operator<-function,装饰者模式),StreamExecutionEnvironment就保存了所有的transformation,并可以根据transformation的input,得到上下游关系。
keyBy的逻辑
keyBy的逻辑如下:
- 1.获得当前流的输出数据类型,这里的当前流是FlatMap的结果流,返回数据类型为Java Tuple2<String, Integer>
- 2.根据keyBy的参数(字段位置),得到字段位置对应的数据类型,例如 0:String,1:Integer,还有一些检查项。
- 3.和上面的transform方法类似,创建默认的KeySelector,这里是ComparableKeySelector,即处理keyBy的function,
- 4.根据KeySelector创建StreamPartitioner,StreamPartitioner对应Operator,但是不继承Operator,因为对数据没有任何的操作,只是分区,
- 5.根据上游input和StreamPartitioner创建keyBy对应的Transformation,这里是PartitionTransformation
- 6.根据Transformation创建KeyedStream
不同于transform方法,这里创建keyedStream后得到结果返回,不会将对应的transformation加入到StreamExecutionEnvironment,这是为什么呢?这里留一个疑问。
Sum的逻辑
看了一下代码,sum的逻辑和flatmap基本相同,根据function->operator->transformation->DataStream,并且将transformation添加到StreamExecutionEnvironment中。不过这里transformation的input是keyBy的PartitionTransformation。
看一下StreamExecutionEnvironment有哪些transformation,是否有遗漏,
Print的逻辑
处理逻辑和flatmap,sum,基本相同,因为使用的是flink内置的sink, 也是function->operator->transformation->DataStreamSink,然后将transformation添加到StreamExecutionEnvironment中
整理一下:
WordCount中,编写的流计算逻辑为Source->FlatMap->KeyBy->Sum->Sink,每个操作都会产生DataStream,都有Transformation,
StreamExecutionEnvironment中保存了3个Transformation,分别是
- FlatMap Transformation id=2, input=DataStreamSource Transformation id=1 (Source Transformation没有input)
- Sum Transformation id=4,input = KeyBy Transformation id=3 ( KeyBy Transformation 的上游为FlatMap Transformation id=2)
- Sink Transformation id=5,input = Sum Transformation id=4,(Sum Transformation id=4 的上游同上)
从Source到Sink中间的处理阶段,这个阶段的方法分两种:
- 1.处理数据的方法
- 2.不处理数据的方法
结合上面的话,关于不会将keyby对应的transformation加入到StreamExecutionEnvironment中的原因:,在这里有了一定的猜测:
1.不处理数据的分发方法,类似keyBy,Source,下游一定是Operator,所以只需要添加Operator的Transformation,将上游添加到Transformation的input中即可。
2.添加最后一个Sink,可以得到Source->Sink的一条链路,
3.如果有一个dag,Source->Operator->Sink中。Operator有多条路径,则无法通过最后一个Sink逆推出所有的路径,因此,需要记录所有的Operator。
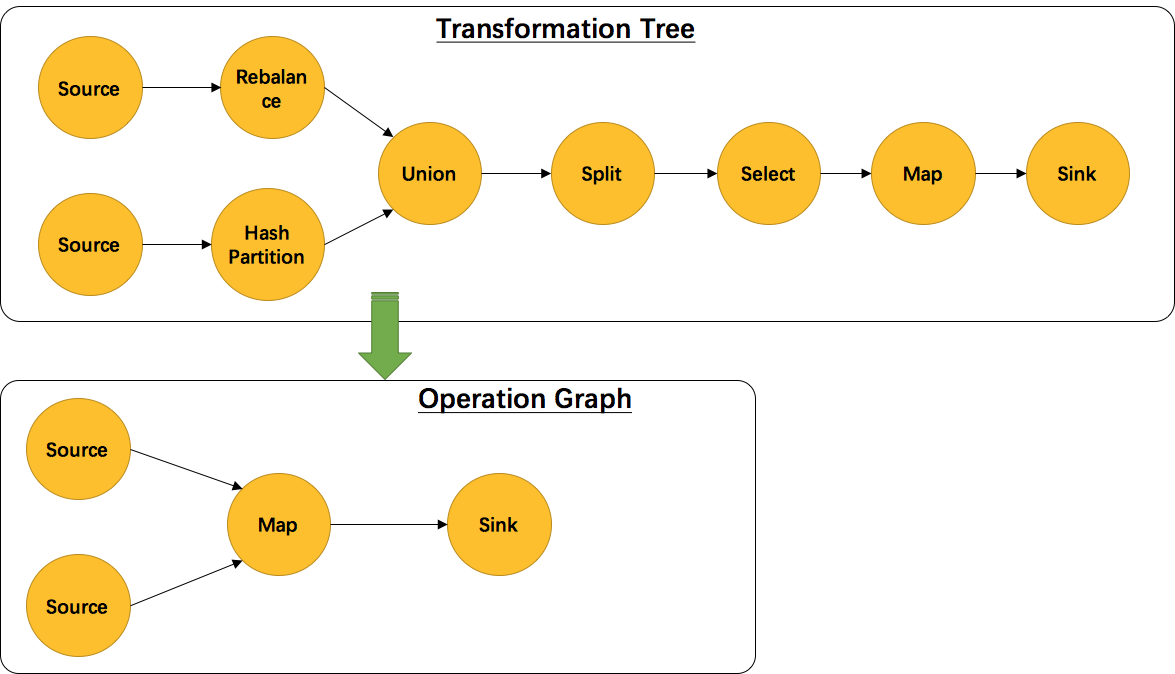
另外,并不是每一个 Transformation 都会转换成runtime层中的物理操作。有一些只是逻辑概念,比如union、split/select、partition等。如下图所示的转换树,在运行时会优化成下方的操作图。
小结
我们编写的flink程序,代码的封装层次为 function->operator->transformation->DataStream(Source,Sink,Stream三种)
每个transformation都会记录上一个流的transformation作为input
Operator和Sink的transformation会被记录到StreamExecutionEnvironment中,保证dag的完整性,也不需要添加所有的transformation,有一定优化作用。
1.4 env.execute启动job
env.execute启动job的过程参考我的上一篇博客Flink-1.5.6 源码分析-----main方法转换为dag的流程,这里不在赘述。
二. flink 四层图结构
先贴一张网上流传很多的图
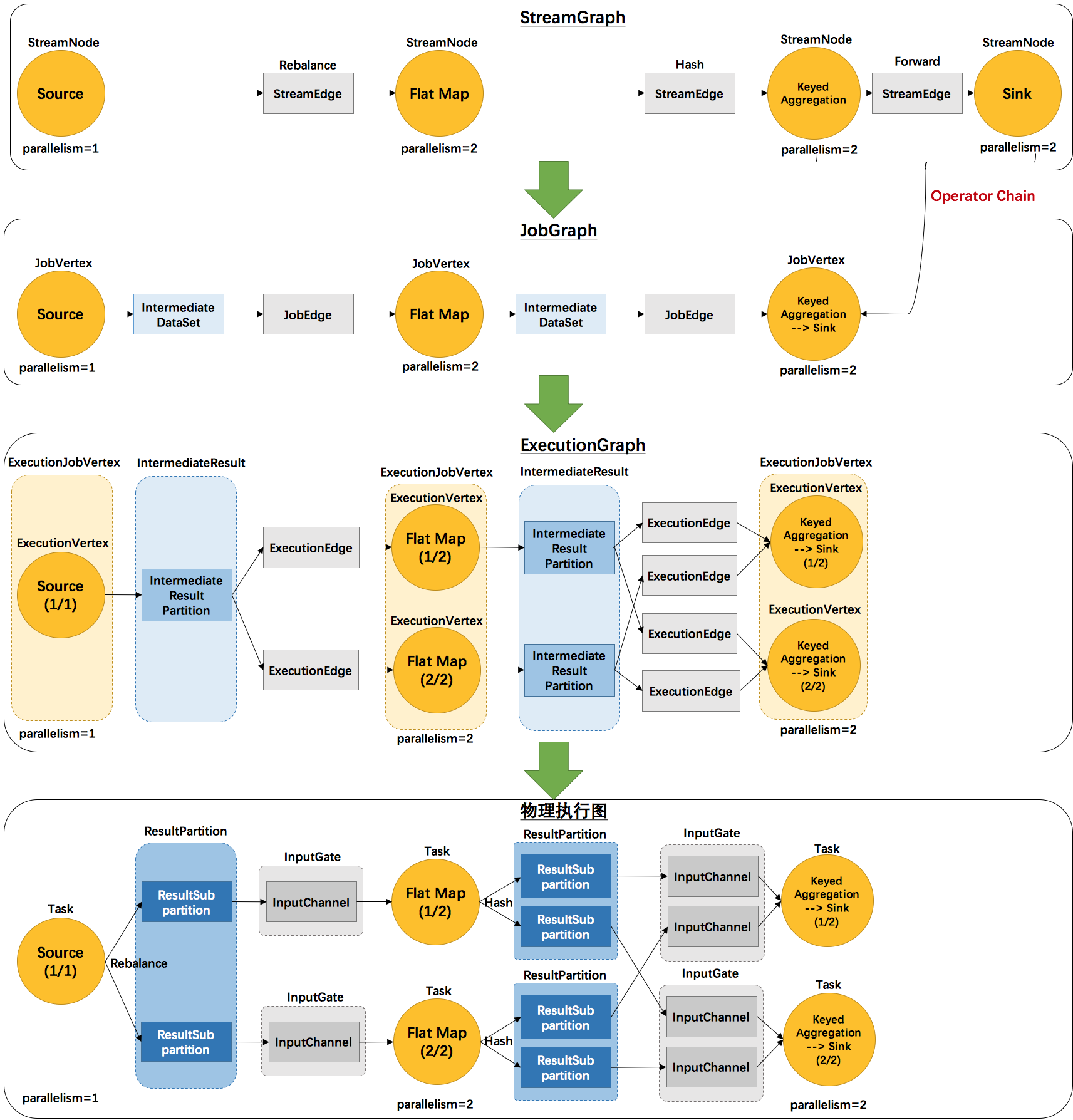
转换过程说明:
- 1.转换过程 StreamExecutionEnvironment存放的transformation->StreamGraph->JobGraph->ExecutionGraph->物理执行图
- 2.StreamExecutionEnvironment存放的transformation->StreamGraph->JobGraph在客户端完成,然后提交JobGraph到JobManager
- 3.JobManager的主节点JobMaster,将JobGraph转化为ExecutionGraph,然后发送到不同的taskManager,得到实际的物理执行图
2.1 WordCount的StreamGraph
StreamGraph的源码在StreamGraphGenerator.generateInternal中,然后进入transform->transformOneInputTransform当中,是Transformation转化为StreamGraph的过程。不过,我们先看看StreamGraph的组成。
public class StreamGraph extends StreamingPlan {
//记录 jobName,StreamExecutionEnvironment,ExecutionConfig,CheckpointConfig等配置
// 记录StreamNode节点,使用id作为key
private Map<Integer, StreamNode> streamNodes;
//记录Source
private Set<Integer> sources;
//记录Sink
private Set<Integer> sinks;
//记录Select 节点,该节点是虚拟的,需要处理,但是不放入Streamgraph中。后面会被优化掉
private Map<Integer, Tuple2<Integer, List<String>>> virtualSelectNodes;
//记录 side output 节点,该节点是虚拟的,需要处理,但是不放入Streamgraph中。后面会被优化掉
private Map<Integer, Tuple2<Integer, OutputTag>> virtualSideOutputNodes;
//记录 partition 节点,该节点是虚拟的,需要处理,但是不放入Streamgraph中。后面会被优化掉
//wordcount 这里为 6 = (2, HASH)
private Map<Integer, Tuple2<Integer, StreamPartitioner<?>>> virtualPartitionNodes;
}StreamGraph中,比较重要的是streamNodes(transformation对应的节点),source(数据源),sinks(输出),然后几个虚拟的节点,sideout,select,partition分发等,都会作为虚拟节点生成,最后被优化掉。
StreamGraph没有记录边,只记录了节点,所以,估计边应该是存在节点中的。查看StreamNodes的组成
public class StreamNode implements Serializable {
//id
private final int id;
//并行度
private Integer parallelism = null;
//处理逻辑Operator,保存在Node中
private transient StreamOperator<?> operator;
//入度边
private List<StreamEdge> inEdges = new ArrayList<StreamEdge>();
//出度边
private List<StreamEdge> outEdges = new ArrayList<StreamEdge>();
}StreamNodes比较重要的属性有statePartitioner,outputSelectors,inEdges(入边),outEdges(出边),
查看StreamEdge的属性
public class StreamEdge implements Serializable {
private static final long serialVersionUID = 1L;
// 边 id
private final String edgeId;
//来源端
private final StreamNode sourceVertex;
//目标端
private final StreamNode targetVertex;
/**
* The type number of the input for co-tasks.
*/
private final int typeNumber;
/**
* SelectTransformation当中用户注入的名字集合
*/
private final List<String> selectedNames;
/**
* SideOutputTransformation当中用户指定的OutputTag
*/
private final OutputTag outputTag;
/**
* The {@link StreamPartitioner} on this {@link StreamEdge}.
* 默认ForwardPartitioner,可由PartitionTransformation指定
*/
private StreamPartitioner<?> outputPartitioner;
}StreamEdge比较重要的属性有: sourceVertex(起点),targetVertex(终点),selectedNames(SelectTransformation当中用户注入的名字集合),outputTag(SideOutputTransformation当中用户指定的OutputTag), outputPartitioner(默认ForwardPartitioner,可由PartitionTransformation指定)
关于分流器 StreamPartitioner
| StreamPartitioner class | toString | 功能 | 场景 |
StreamPartitioner |
分区器,将流的数据从一个Channel输出到其他的一个或多个Channel, | 流数据从上游到下游, | |
Channel |
int类型,标识下游的序号,例如,下游并行度为4 则每个子任务对应的Channel为 0,1,2,3 |
||
RescalePartitioner |
RESCALE |
以round-robin的形式将元素分区到下游subtask的子集中 |
|
RebalancePartitioner |
REBALANCE |
重平衡分区器,用于实现类似于round-robin这样的轮转模式的分区器。通过累加、取模的形式来实现对输出channel的切换。 |
上下游并行度不相同时 |
GlobalPartitioner |
GLOBAL |
全局分区器,无论有多少Channel,直接输出到0 | |
KeyGroupStreamPartitioner |
HASH |
按key分组,大体等于key的hash对并行度取余 channel = keyGroupId * parallelism / maxParallelism 其中 keyGroupId 是根据key计算,按下面的公式 MathUtils.murmurHash(key.hashCode()) % maxParallelism |
调用keyBy() |
ShufflePartitioner |
SHUFFLE |
混洗分区器,该分区器会在所有output channel中选择一个随机的进行输出 |
调用shuffle |
ForwardPartitioner |
FORWARD |
该分区器将记录转发给在本地运行的下游的,一对一或多对一 | 默认Forward,没有指定partiiton时,例如map->reduce |
CustomPartitionerWrapper |
CUSTOM |
用于支持自定义实现, | 自定义 |
BroadcastPartitioner |
BROADCAST |
广播分区器,用于将该记录广播给下游的所有的subtask |
broadcast时 |
关于流分区器可以参考源码和Apache Flink流分区器剖析
flink提供了一个StreamGraph可视化显示工具,在这里
我们可以把我们的程序的执行计划打印出来System.out.println(env.getExecutionPlan()); 复制到这个网站上,点击生成,如图所示: 
可以看到,我们源程序被转化成了4个operator。
另外,在operator之间的连线上也显示出了flink添加的一些逻辑流程。