Python实验二:爬取大学排名和中科院院士信息
初稿:较为粗糙,不过思路清晰,通俗易懂,问题不大
第一项内容:爬取大学排名
爬取最好大学网网页中549所国内大学的排名数据,并将排名、学校名称、省市、总分、社会声誉等内容打印出来。
任务一实验步骤:
(1)使用Google Chrome或其他浏览器打开下面的网址,然后在页面上右击,在弹出的菜单中选择“查看网页源代码”。
http://www.zuihaodaxue.cn/zuihaodaxuepaiming20链接19.html
(2)分析网页源代码的,确定每个学校的姓名和连接所在的HTML标签,为解析网页做准备。
(3)编写代码,爬取信息。
"""
# @Time : 2020/4/16
# @Author : JMChen
"""
import requests
from bs4 import BeautifulSoup
rank_list = []
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html'
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36'
headers = {"User-Agent": user_agent}
respond = requests.get(url, headers=headers)
respond.encoding = 'utf-8'
soup = BeautifulSoup(respond.text, "lxml")
tr_list = soup.find_all('tr', class_='alt')
print("排名\t\t学校名称\t\t\t 省份\t\t\t 总分\t\t社会声誉")
for node in tr_list:
rank = node.find('td').text
university_name = node.find_all('td')[1].string
province = node.find_all('td')[2].string
score = node.find_all('td')[3].string
scale = node.find('td', class_="hidden-xs need-hidden indicator7").text
print("{0:<10}{1:<20}{2:<15}{3:<10}{4:<20}".format(rank, university_name, province, score, scale))
结果如下


格式化输出可以改进,用居中^会好看点。
第二项内容:爬取中国工程院院士信息
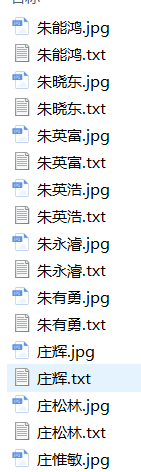
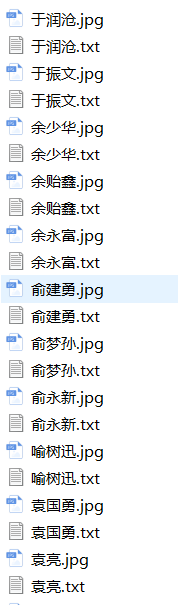
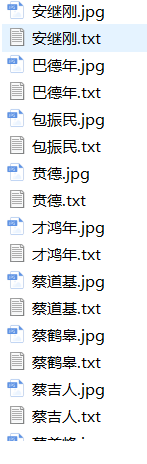
爬取中国工程院网页上,把每位院士的简介保存为本地文件,把每位院士的照片保存为本地图片,文本文件和图片文件都以院士的姓名为主文件。
任务二实验步骤:
(1)使用Google Chrome或其他浏览器打开下面的网址,然后在页面上右击,在弹出的菜单中选择“查看网页源代码”。
http://www.cae.cn/cae/html/main/col48/column_48_1.html
(2)分析网页源代码的,确定每个院士的姓名和链接所在的HTML标签,为编写正则表达式做准备。
(3)使用浏览器打开任意一位院士的链接,然后查看并分析网页源代码,确定简介信息和照片所以的HTML标签,为编写正则表达式做准备。
(4)编写代码,爬取信息并创建本地文件。
个人觉的像这种友好的网站,不用user-agent也可以访问,甚至不需sleep也ok
"""
# @Time : 2020/4/16
# @Author : JMChen
"""
import requests
import re
from urllib.request import urlopen
url = 'http://www.cae.cn/cae/html/main/col48/column_48_1.html'
respond = requests.get(url)
respond.encoding = 'utf-8'
every_num = re.findall('<a href="/cae/html/main/colys/(\d+).html" target="_blank">', respond.text)
count = 1
for man in every_num[:1000]:
man_url = 'http://www.cae.cn/cae/html/main/colys/{}.html'.format(man)
man_respond = requests.get(man_url)
man_respond.encoding = 'utf-8'
text1 = re.findall('<div class="intro">(.*?)</div>', man_respond.text, re.S)
text2 = re.sub(r'<p>| | |</p>', '', text1[0]).strip()
#print(text2)
file_name = re.findall('<div class="right_md_name">(.*?)</div>', man_respond.text)[0]
with open(file_name+'.txt', mode='a+', encoding="utf-8") as f:
f.write('{}. '.format(count) + text2 + '\n')
count += 1
photo = r'<img src="/cae/admin/upload/img/(.+)" style='
result = re.findall(photo, man_respond.text, re.I)
if result:
picurl = r'http://www.cae.cn/cae/admin/upload/img/{0}'.format(result[0].replace(' ', r'%20'))
img_name = re.findall('<div class="right_md_name">(.*?)</div>', man_respond.text)[0]
with open(img_name + '.jpg', 'wb') as fpic:
fpic.write(urlopen(picurl).read())
with open('MassageTestCount.txt', mode='a+', encoding="utf-8") as f:
f.write('{}. '.format(count) + text2 + '\n')
count += 1
修改一下文件名,测试了一下,发现确实九百多人.。。。

