核心术语Glossary
核心术语
Application *****
a driver program
executors on the cluster.
Application jar
Driver program *****
main
sc
Cluster manager
Deploy mode
YARN: RM NM(container)
cluster: Driver是跑在container
client:Driver就运行在你提交机器的本地
client是不是一定要是集群内的?gateway
Worker node
Executor *****
process
runs tasks
keeps data in memory or disk storage across them
Each application has its own executors.
A:executor1 2 3
B:executor1 2 3
Task *****
A unit of work that will be sent to one executor
RDD: partitions == task
Job *****
action ==> job
Stage
eg:
spark-shell 应用程序
一个application:1到n个job
一个job : 1到n个stage构成
一个stage: 1到n个task task与partition一一对应
Application
User program built on Spark. Consists of a driver program and executors on the cluster.
1.User program built on Spark
2.a driver program
3. executors on the cluster.
Application jar
A jar containing the user’s Spark application. In some cases users will want to create an “uber jar” containing their application along with its dependencies. The user’s jar should never include Hadoop or Spark libraries, however, these will be added at runtime.
Driver program
The process running the main() function of the application and creating the SparkContext
1. running the main() function of the application
2. creating the SparkContext
Cluster manager
An external service for acquiring resources on the cluster (e.g. standalone manager, Mesos, YARN)
所以你的代码里 上传到集群的时候 不要写 死 appname 和 master
到时候通过 spark-submit 来指定就 可以选择 外部的cluster
Deploy mode
Distinguishes where the driver process runs. In “cluster” mode, the framework launches the driver inside of the cluster. In “client” mode, the submitter launches the driver outside of the cluster.
一切以yarn为主
YARN: RM NM(container)
cluster: Driver是跑在container (跑在NM 里的container的 )
client:Driver就运行在你提交机器的本地
client是不是一定要是集群内的?gateway
Worker node
Any node that can run application code in the cluster
yarn模式下 就是 nm
run application code
Executor
a process launched for an application on a worker node, that runs tasks and keeps data in memory or disk storage across them. Each application has its own executors.
一个进程 jps 就能看到
对应yarn上 就跑在 nm的container里的
1. runs tasks
2. keeps data in memory or disk storage across them
3. Each application has its own executors.
A:executor1 2 3
B:executor1 2 3
这6个东西 是跑在container里的
Task
A unit of work that will be sent to one executor
1.task 是发送到 executor里的
2.RDD: partitions == tasks
RDD是由多个partition所构成的,
一个partition就对应一个task
Job
A parallel computation consisting of multiple tasks that gets spawned in response to a Spark action (e.g. save, collect); you’ll see this term used in the driver’s logs.
1.一个action算子对应一个job
Stage
Each job gets divided into smaller sets of tasks called stages that depend on each other (similar to the map and reduce stages in MapReduce); you’ll see this term used in the driver’s logs.
1.一组task的集合 叫一个stage
2.遇到一个shuffle算子 就会被拆成两个stage
那遇到两个shuffle算子 会被拆成几个stage呢? 3个哈
(跟一个桌子切掉一个桌角 还有几个角一样的哈 你别把桌子对角切就行 )
总结案例
eg:
spark-shell 应用程序
一个application:1到n个job
一个job : 1到n个stage构成
一个stage: 1到n个task task与partition一一对应
Components ***
Spark applications run as independent sets of processes on a cluster
independent sets of processes:就是executor
Spark applications run as independent sets of processes on a cluster, coordinated by the SparkContext object in your main program (called the driver program).
Specifically, to run on a cluster, the SparkContext can connect to several types of cluster managers (either Spark’s own standalone cluster manager, Mesos or YARN), which allocate resources across applications. Once connected, Spark acquires executors on nodes in the cluster, which are processes that run computations and store data for your application. Next**, it sends your application code (defined by JAR or Python files passed to SparkContext) to the executors**. Finally, SparkContext sends tasks to the executors to run.
1. which allocate resources across applications. which ===》 cluster managers
2. Once connected, Spark acquires executors on nodes in the cluster
一旦连接上 spark 就yarn集群的 nm 的contatiner 里启动executor
3.which are processes that run computations and store data for your application :
which ===》executor
4.it sends your application code (defined by JAR or Python files passed to SparkContext) to the executors
it ==》 sc
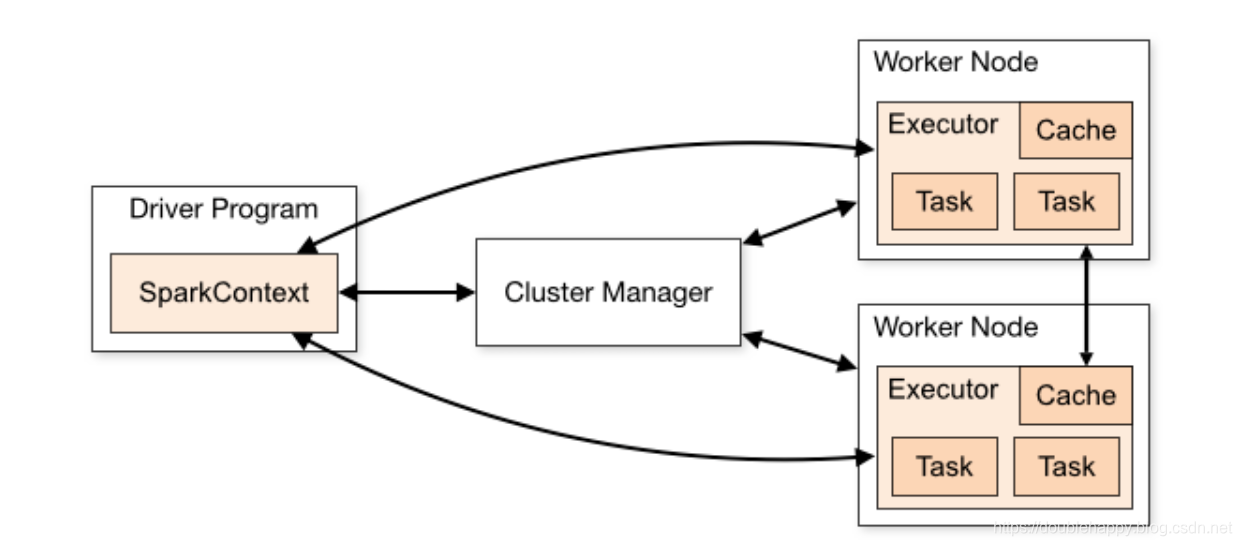
1.driver : main方法里有个 sc
There are several useful things to note about this architecture:
1.Each application gets its own executor processes, which stay up for the duration of the whole application and run tasks in multiple threads. This has the benefit of isolating applications from each other, on both the scheduling side (each driver schedules its own tasks) and executor side (tasks from different applications run in different JVMs). However, it also means that data cannot be shared across different Spark applications (instances of SparkContext) without writing it to an external storage system.
2.Spark is agnostic to the underlying cluster manager. As long as it can acquire executor processes, and these communicate with each other, it is relatively easy to run it even on a cluster manager that also supports other applications (e.g. Mesos/YARN).
1. which stay up for the duration of the whole application and run tasks in multiple threads
which ==》executor processes
1.stay up for the duration of the whole application
2.run tasks in multiple threads
2.This has the benefit of isolating applications from each other
Each application gets its own executor processes 就是每个application有自己独立的 executor processes
带来的好处就是 applications之间是隔离的
3.cannot be shared across different Spark applications
without writing it to an external storage system ===》Alluxio这个框架 现在可以实现 多个application之间共享
4. agnostic 不关注
As long as it can acquire executor processes, and these communicate with each other
指的是 driver 和 executor之间的通信
3.The driver program must listen for and accept incoming connections from its executors throughout its lifetime (e.g., see spark.driver.port in the network config section). As such, the driver program must be network addressable from the worker nodes.
4.Because the driver schedules tasks on the cluster, it should be run close to the worker nodes, preferably on the same local area network. If you’d like to send requests to the cluster remotely, it’s better to open an RPC to the driver and have it submit operations from nearby than to run a driver far away from the worker nodes.
1.The driver program must listen for and accept incoming connections from its executors throughout its lifetime
driver一定要知道你的executor在哪台机器上的
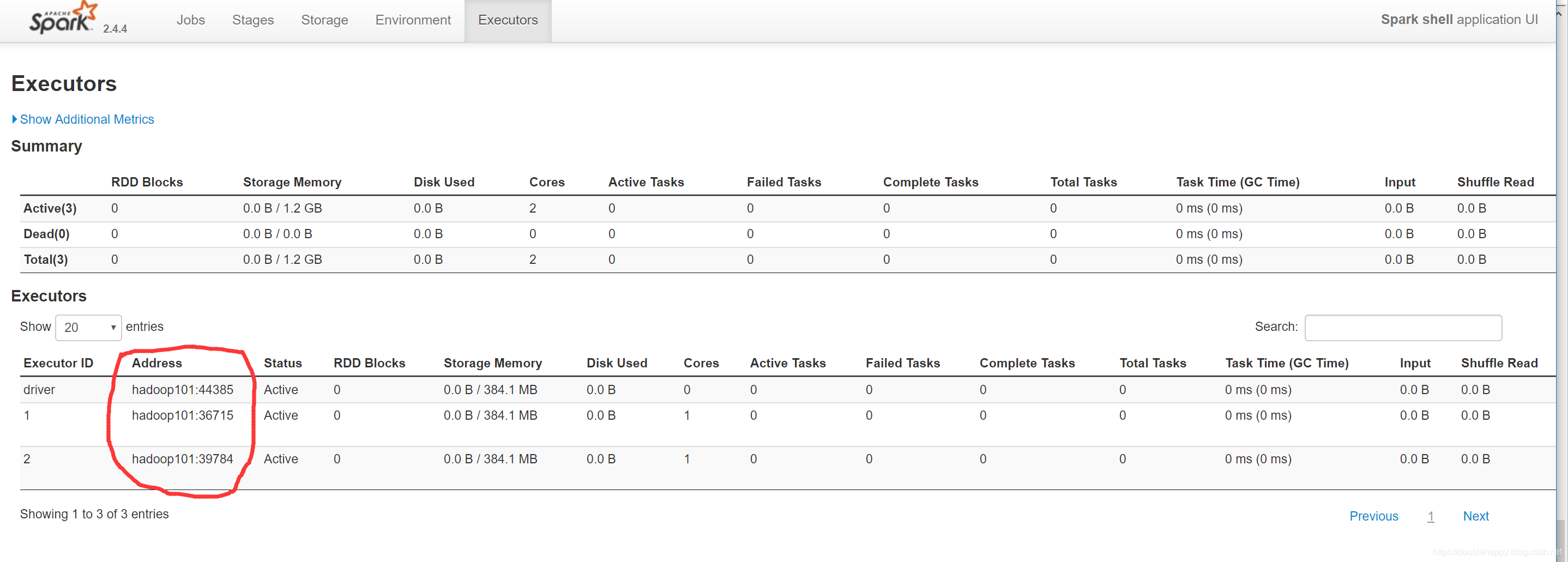
这块可以看到 executor 在那台机器的哪个端口上
2.As such, the driver program must be network addressable from the worker nodes.
所以yarn的client模式下
必须保证这台本地的机器能与yarn通了 ,client是不是一定要是集群内的?不一定的哈 能连上yarn就可以
最开始的文章 gateway什么意思呢?你亲我一下我就告诉你 (这是对未来女朋友说的)
3.driver进程最好离executor进程 近一点