1. Spark 运行架构
1.1 1 运行架构
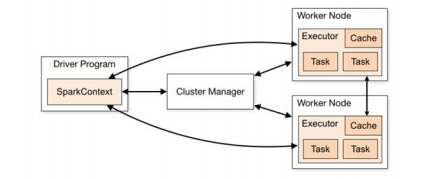
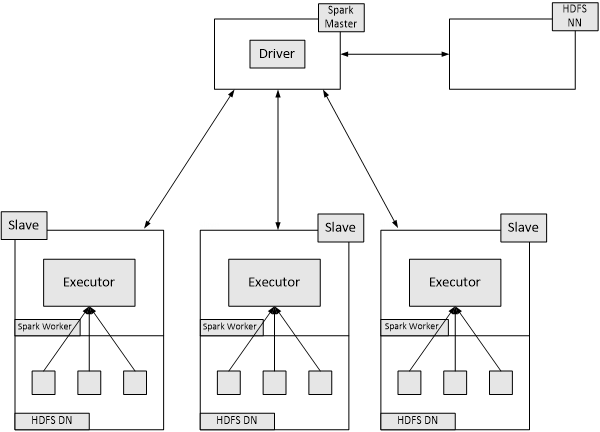
Spark 框架的核心是一个计算引擎,整体来说,它采用了标准 master-slave 的结构。
如下图所示,它展示了一个 Spark 执行时的基本结构。图形中的 Driver 表示 master,负责管理整个集群中的作业任务调度。图形中的 Executor 则是 slave,负责实际执行任务。
1.2 核心组件
由上图可以看出,对于 Spark 框架有两个核心组件:
1.2.1 Driver
Spark 驱动器节点,用于执行 Spark 任务中的 main 方法,负责实际代码的执行工作。
Driver 在 Spark 作业执行时主要负责:
➢ 将用户程序转化为作业(job)
➢ 在 Executor 之间调度任务(task)
➢ 跟踪 Executor 的执行情况
➢ 通过 UI 展示查询运行情况
实际上,我们无法准确地描述 Driver 的定义,因为在整个的编程过程中没有看到任何有关Driver 的字眼。所以简单理解,所谓的 Driver 就是驱使整个应用运行起来的程序,也称之为Driver 类。
1.2.2 Executor
Spark Executor 是集群中工作节点(Worker)中的一个 JVM 进程,负责在 Spark 作业中运行具体任务(Task),任务彼此之间相互独立。Spark 应用启动时,Executor 节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有 Executor 节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他 Executor 节点上继续运行。
Executor 有两个核心功能:
➢ 负责运行组成 Spark 应用的任务,并将结果返回给驱动器进程
➢ 它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存式存储。RDD 是直接缓存在 Executor 进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
1.2.3 Master & Worker
Spark 集群的独立部署环境中,不需要依赖其他的资源调度框架,自身就实现了资源调度的功能,所以环境中还有其他两个核心组件:Master 和 Worker,这里的 Master 是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责,类似于 Yarn 环境中的 RM, 而Worker 呢,也是进程,一个 Worker 运行在集群中的一台服务器上,由 Master 分配资源对数据进行并行的处理和计算,类似于 Yarn 环境中 NM。
1.2.4 ApplicationMaster
Hadoop 用户向 YARN 集群提交应用程序时,提交程序中应该包含 ApplicationMaster,用于向资源调度器申请执行任务的资源容器 Container,运行用户自己的程序任务 job,监控整个任务的执行,跟踪整个任务的状态,处理任务失败等异常情况。
说的简单点就是,ResourceManager(资源)和 Driver(计算)之间的解耦合靠的就是ApplicationMaster。

1.3 核心概念
1.3.1 Executor 与 Core
Spark Executor 是集群中运行在工作节点(Worker)中的一个 JVM 进程,是整个集群中的专门用于计算的节点。在提交应用中,可以提供参数指定计算节点的个数,以及对应的资源。这里的资源一般指的是工作节点 Executor 的内存大小和使用的虚拟 CPU 核(Core)数量。
应用程序相关启动参数如下:

1.3.2 并行度(Parallelism)
在分布式计算框架中一般都是多个任务同时执行,由于任务分布在不同的计算节点进行计算,所以能够真正地实现多任务并行执行,记住,这里是并行,而不是并发。这里我们将整个集群并行执行任务的数量称之为并行度。那么一个作业到底并行度是多少呢?这个取决于框架的默认配置。应用程序也可以在运行过程中动态修改。
1.3.3 有向无环图(DAG)
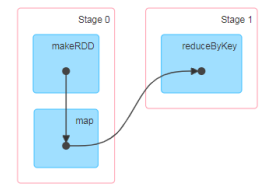
大数据计算引擎框架我们根据使用方式的不同一般会分为四类,其中第一类就是Hadoop 所承载的 MapReduce,它将计算分为两个阶段,分别为 Map 阶段 和 Reduce 阶段。对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个 Job 的串联,以完成一个完整的算法,例如迭代计算。 由于这样的弊端,催生了支持 DAG 框架的产生。因此,支持 DAG 的框架被划分为第二代计算引擎。如 Tez 以及更上层的Oozie。这里我们不去细究各种 DAG 实现之间的区别,不过对于当时的 Tez 和 Oozie 来说,大多还是批处理的任务。接下来就是以 Spark 为代表的第三代的计算引擎。第三代计算引擎的特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及实时计算。
这里所谓的有向无环图,并不是真正意义的图形,而是由 Spark 程序直接映射成的数据流的高级抽象模型。简单理解就是将整个程序计算的执行过程用图形表示出来,这样更直观,更便于理解,可以用于表示程序的拓扑结构。
DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。
1.4 提交流程
所谓的提交流程,其实就是我们开发人员根据需求写的应用程序通过 Spark 客户端提交给 Spark 运行环境执行计算的流程。在不同的部署环境中,这个提交过程基本相同,但是又有细微的区别,我们这里不进行详细的比较,但是因为国内工作中,将 Spark 引用部署到Yarn 环境中会更多一些,所以本课程中的提交流程是基于 Yarn 环境的。
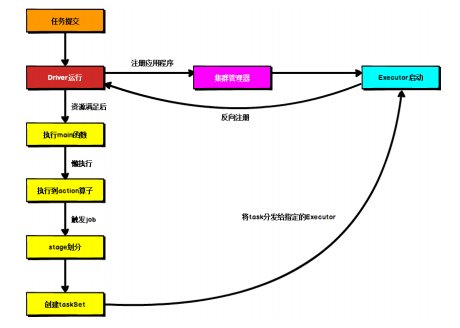
Spark 应用程序提交到 Yarn 环境中执行的时候,一般会有两种部署执行的方式:Client和 Cluster。两种模式主要区别在于:Driver 程序的运行节点位置。
1.4.1 Yarn Client 模式
Client 模式将用于监控和调度的 Driver 模块在客户端执行,而不是在 Yarn 中,所以一般用于测试。
➢ Driver 在任务提交的本地机器上运行
➢ Driver 启动后会和 ResourceManager 通讯申请启动 ApplicationMaster
➢ ResourceManager 分配 container,在合适的NodeManager 上启动 ApplicationMaster,负责向 ResourceManager 申请 Executor 内存
➢ ResourceManager 接到 ApplicationMaster 的资源申请后会分配 container,然后ApplicationMaster 在资源分配指定的 NodeManager 上启动 Executor 进程
➢ Executor 进程启动后会向 Driver 反向注册,Executor 全部注册完成后 Driver 开始执行main 函数
➢ 之后执行到 Action 算子时,触发一个 Job,并根据宽依赖开始划分 stage,每个 stage 生成对应的 TaskSet,之后将 task 分发到各个 Executor 上执行。
1.4.2 Yarn Cluster 模式
Cluster 模式将用于监控和调度的 Driver 模块启动在 Yarn 集群资源中执行。一般应用于
实际生产环境。
➢ 在 YARN Cluster 模式下,任务提交后会和 ResourceManager 通讯申请启动
ApplicationMaster,
➢ 随后 ResourceManager 分配 container,在合适的 NodeManager 上启动ApplicationMaster,此时的 ApplicationMaster 就是 Driver。
➢ Driver 启动后向 ResourceManager 申请 Executor 内存,ResourceManager 接到
ApplicationMaster 的资源申请后会分配 container,然后在合适的 NodeManager 上启动
Executor 进程
➢ Executor 进程启动后会向 Driver 反向注册,Executor 全部注册完成后 Driver 开始执行
main 函数,
➢ 之后执行到 Action 算子时,触发一个 Job,并根据宽依赖开始划分 stage,每个 stage 生
成对应的 TaskSet,之后将 task 分发到各个 Executor 上执行。
2. Spark 核心编程
Spark 计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于处理不同的应用场景。三大数据结构分别是:
➢ RDD : 弹性分布式数据集
➢ 累加器:分布式共享只写变量
➢ 广播变量:分布式共享只读变量
接下来我们一起看看这三大数据结构是如何在数据处理中使用的。
2.1 RDD
2.1.1 什么是 RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
➢ 弹性
◾ 存储的弹性:内存与磁盘的自动切换;
◾ 容错的弹性:数据丢失可以自动恢复;
◾ 计算的弹性:计算出错重试机制;
◾ 分片的弹性:可根据需要重新分片。
➢ 分布式:数据存储在大数据集群不同节点上
➢ 数据集:RDD 封装了计算逻辑,并不保存数据
➢ 数据抽象:RDD 是一个抽象类,需要子类具体实现
➢ 不可变:RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在新的 RDD 里面封装计算逻辑。
➢ 可分区、并行计算
2.1.2 核心属性

➢ 分区列表
RDD 数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性。

➢ 分区计算函数
Spark 在计算时,是使用分区函数对每一个分区进行计算

➢ RDD 之间的依赖关系
RDD 是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个 RDD 建
立依赖关系

➢ 分区器(可选)
当数据为 KV 类型数据时,可以通过设定分区器自定义数据的分区
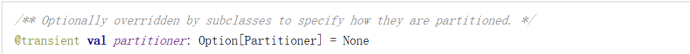
➢ 首选位置(可选)
计算数据时,可以根据计算节点的状态选择不同的节点位置进行计算

2.1.3 执行原理
从计算的角度来讲,数据处理过程中需要计算资源(内存 & CPU)和计算模型(逻辑)。
执行时,需要将计算资源和计算模型进行协调和整合。
Spark 框架在执行时,先申请资源,然后将应用程序的数据处理逻辑分解成一个一个的计算任务。然后将任务发到已经分配资源的计算节点上, 按照指定的计算模型进行数据计算。最后得到计算结果。
RDD 是 Spark 框架中用于数据处理的核心模型,接下来我们看看,在 Yarn 环境中,RDD
的工作原理:
- 启动 Yarn 集群环境
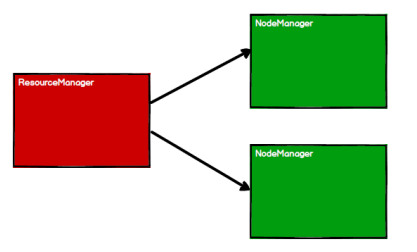
- Spark 通过申请资源创建调度节点和计算节点
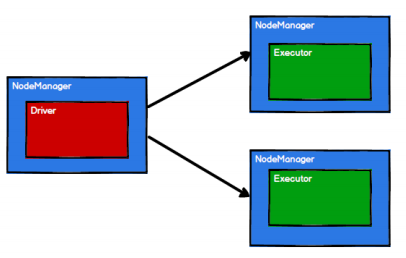
- Spark 框架根据需求将计算逻辑根据分区划分成不同的任务
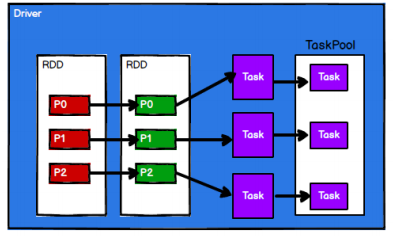
- 调度节点将任务根据计算节点状态发送到对应的计算节点进行计算
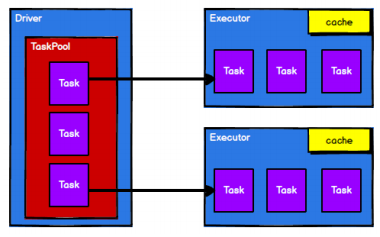
从以上流程可以看出 RDD 在整个流程中主要用于将逻辑进行封装,并生成 Task 发送给Executor 节点执行计算,接下来我们就一起看看 Spark 框架中 RDD 是具体是如何进行数据处理的。
2.1.4 基础编程
2.1.4.1 RDD 创建
在 Spark 中创建 RDD 的创建方式可以分为四种:
- 从集合(内存)中创建 RDD
从集合中创建 RDD,Spark 主要提供了两个方法:parallelize 和 makeRDD
val sparkConf =
new SparkConf().setMaster("local[*]").setAppName("spark")
val sparkContext = new SparkContext(sparkConf)
val rdd1 = sparkContext.parallelize(
List(1,2,3,4)
)
val rdd2 = sparkContext.makeRDD(
List(1,2,3,4)
)
rdd1.collect().foreach(println)
rdd2.collect().foreach(println)
sparkContext.stop()
从底层代码实现来讲,makeRDD 方法其实就是 parallelize 方法
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices)
}
- 从本地文件系统中加载数据创建RDD
scala> val lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt")
lines: org.apache.spark.rdd.RDD[String] = file:///usr/local/spark/mycode/rdd/word.txt MapPartitionsRDD[12] at textFile at <console>:27
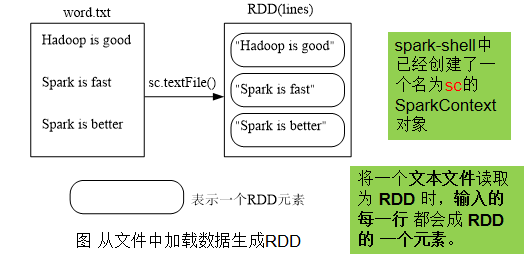
- 从分布式文件系统HDFS中加载数据
scala> val lines = sc.textFile("hdfs://localhost:9000/user/hadoop/word.txt")
scala> val lines = sc.textFile("/user/hadoop/word.txt")
scala> val lines = sc.textFile("word.txt")
- 直接创建 RDD(new)
使用 new 的方式直接构造 RDD,一般由 Spark 框架自身使用。
2.1.4.2 RDD转换操作
-
对于RDD而言,每一次转换操作都会产生不同的RDD,供给下一个“转换”使用
-
转换得到的RDD是惰性求值的,也就是说,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会发生真正的计算,开始从血缘关系源头开始,进行物理的转换操作

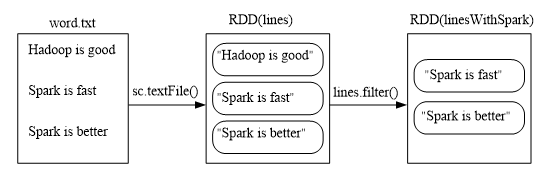
-
filter(func)
scala> val lines =sc.textFile(file:///usr/local/spark/mycode/rdd/word.txt)
scala> val linesWithSpark=lines.filter(line => line.contains("Spark"))
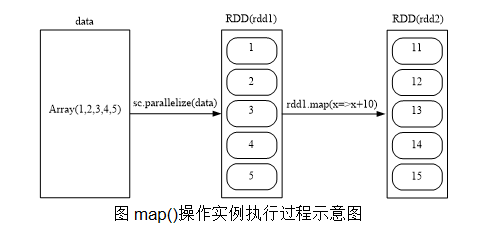
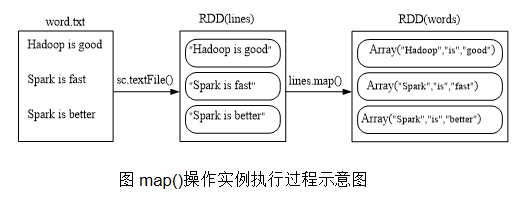
- map(func)
map(func)操作将每个元素传递到函数func中,并将结果返回为一个新的数据集
scala> data=Array(1,2,3,4,5)
scala> val rdd1= sc.parallelize(data)
scala> val rdd2=rdd1.map(x=>x+10)
scala> val lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt")
scala> val words=lines.map(line => line.split(" "))
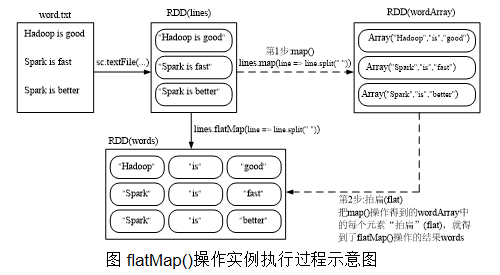
- flatMap(func)
scala> val lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt")
scala> val words=lines.flatMap(line => line.split(" "))
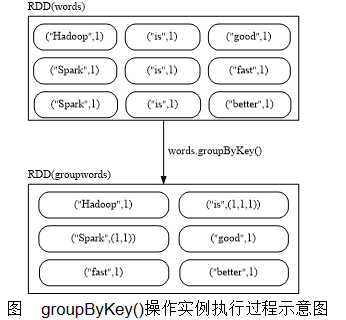
- groupByKey()
groupByKey()应用于(K,V)键值对的数据集时,返回一个新的(K, Iterable)形式的数据集
- reduceByKey(func)
rdd.reduceByKey((a,b)=>a+b)
2.1.4.3 行动操作
行动操作是真正触发计算的地方。Spark程序执行到行动操作时,才会执行真正的计算,从文件中加载数据,完成一次又一次转换操作,最终,完成行动操作得到结果。
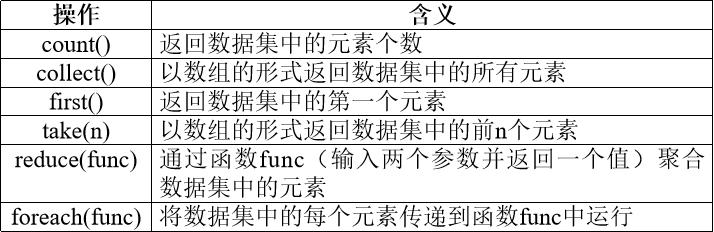
scala> val rdd=sc.parallelize(Array(1,2,3,4,5))
rdd: org.apache.spark.rdd.RDD[Int]=ParallelCollectionRDD[1] at parallelize at <console>:24
scala> rdd.count()
res0: Long = 5
scala> rdd.first()
res1: Int = 1
scala> rdd.take(3)
res2: Array[Int] = Array(1,2,3)
scala> rdd.reduce((a,b)=>a+b)
res3: Int = 15
scala> rdd.collect()
res4: Array[Int] = Array(1,2,3,4,5)
scala> rdd.foreach(elem=>println(elem))
1
2
3
4
5
2.1.5 惰性机制
所谓的“惰性机制”是指,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会触发“从头到尾”的真正的计算这里给出一段简单的语句来解释Spark的惰性机制
scala> val lines = sc.textFile("data.txt")
scala> val lineLengths = lines.map(s => s.length)
scala> val totalLength = lineLengths.reduce((a, b) => a + b)
惰性求值意味着当我们对RDD调用转化操作(例如调用map()时),操作不会立即执行。相反,Spark会在内部记录下所要求执行的操作的相关信息。我们不应该把RDD看作存放着特定数据的数据集,而最好把每个RDD当作我们通过转化操作构建出来的、记录如何计算数据的指令列表。把数据读取到RDD的操作也同样是惰性的。因此,当我们调用sc.textFile()时,数据并没有读取进来,而是在必要时才会读取。到最后遇到reduce操作。
第一,采用惰性计算可以忽略那些“你写了,但是没用到”的计算逻辑,有加速的作用。
第二,不需要每一个中间结果都保存在内存或磁盘中,节省了空间。
2.1.6 持久化
在Spark中,RDD采用惰性求值的机制,每次遇到行动操作,都会从头开始执行计算。每次调用行动操作,都会触发一次从头开始的计算。这对于迭代计算而言,代价是很大的,迭代计算经常需要多次重复使用同一组数据.
- 可以通过持久化(缓存)机制避免这种重复计算的开销
- 可以使用persist()方法对一个RDD标记为持久化之所以说“标记为持久化”,是因为出现persist()语句的地方,并不会马上计算生成RDD并把它持久化,而是要等到遇到第一个行动操作触发真正计算以后,才会把计算结果进行持久化
- 持久化后的RDD将会被保留在计算节点的内存中被后面的行动操作重复使用
- cache()方法
persist()的圆括号中包含的是持久化级别参数:

针对上面的实例,增加持久化语句以后的执行过程如下:
scala> val list = List("Hadoop","Spark","Hive")
list: List[String] = List(Hadoop, Spark, Hive)
scala> val rdd = sc.parallelize(list)
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[22] at parallelize at <console>:29
scala> rdd.cache() //会调用persist(MEMORY_ONLY),但是,语句执行到这里,并不会缓存rdd,因为这时rdd还没有被计算生成
scala> println(rdd.count()) //第一次行动操作,触发一次真正从头到尾的计算,这时上面的rdd.cache()才会被执行,把这个rdd放到缓存中
3
scala> println(rdd.collect().mkString(",")) //第二次行动操作,不需要触发从头到尾的计算,只需要重复使用上面缓存中的rdd
Hadoop,Spark,Hive
2.1.7 RDD 并行度与分区
RDD是弹性分布式数据集,通常RDD很大,会被分成很多个分区,分别保存在不同的节点上
1. 分区的作用
(1)增加并行度

(2)减少通信开销
未分区时对UserData和Events两个表进行连接操作
UserData(UserId,UserInfo)
Events(UserID,LinkInfo)
UserData 和Events 表进行连接操作,获得
(UserID,UserInfo,LinkInfo)
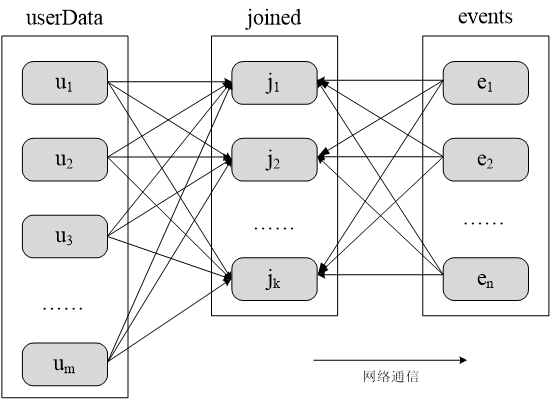
采用分区以后对UserData和Events两个表进行连接操作
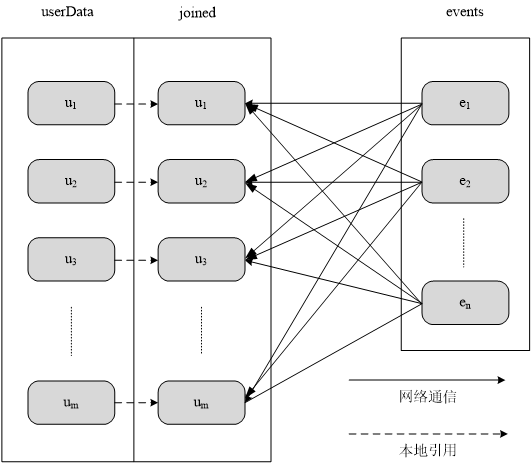
2.RDD分区原则
RDD分区的一个原则是使得分区的个数尽量等于集群中的CPU核心(core)数目
对于不同的Spark部署模式而言(本地模式、Standalone模式、YARN模式、Mesos模式),都可以通过设置spark.default.parallelism这个参数的值,来配置默认的分区数目,一般而言:
*本地模式:默认为本地机器的CPU数目,若设置了local[N],则默认为N
*Apache Mesos:默认的分区数为8
*Standalone或YARN:在“集群中所有CPU核心数目总和”和“2”二者中取较大值作为默认值
3.设置分区的个数
(1)创建RDD时手动指定分区个数
在调用textFile()和parallelize()方法的时候手动指定分区个数即可,语法格式如下:
sc.textFile(path, partitionNum)
其中,path参数用于指定要加载的文件的地址,partitionNum参数用于指定分区个数。
scala> val array = Array(1,2,3,4,5)
scala> val rdd = sc.parallelize(array,2) //设置两个分区
(2)使用reparititon方法重新设置分区个数
通过转换操作得到新 RDD 时,直接调用 repartition 方法即可。例如:
scala> val data = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt",2)
data: org.apache.spark.rdd.RDD[String] = file:///usr/local/spark/mycode/rdd/word.txt MapPartitionsRDD[12] at textFile at <console>:24
scala> data.partitions.size //显示data这个RDD的分区数量
res2: Int=2
scala> val rdd = data.repartition(1) //对data这个RDD进行重新分区
rdd: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[11] at repartition at :26
scala> rdd.partitions.size
res4: Int = 1
4.自定义分区方法
Spark提供了自带的HashPartitioner(哈希分区)与RangePartitioner(区域分区),能够满足大多数应用场景的需求。与此同时,Spark也支持自定义分区方式,即通过提供一个自定义的Partitioner对象来控制RDD的分区方式,从而利用领域知识进一步减少通信开销
要实现自定义分区,需要定义一个类,这个自定义类需要继承org.apache.spark.Partitioner类,并实现下面三个方法:
- numPartitions: Int 返回创建出来的分区数
- getPartition(key: Any): Int 返回给定键的分区编号(0到numPartitions-1)
- equals() Java判断相等性的标准方法
实例:根据key值的最后一位数字,写到不同的文件
例如:
10写入到part-00000
11写入到part-00001
.
.
.
19写入到part-00009
import org.apache.spark.{
Partitioner, SparkContext, SparkConf}
//自定义分区类,需要继承org.apache.spark.Partitioner类
class MyPartitioner(numParts:Int) extends Partitioner{
//覆盖分区数
override def numPartitions: Int = numParts
//覆盖分区号获取函数
override def getPartition(key: Any): Int = {
key.toString.toInt%10
}
}
object TestPartitioner {
def main(args: Array[String]) {
val conf=new SparkConf()
val sc=new SparkContext(conf)
//模拟5个分区的数据
val data=sc.parallelize(1 to 10,5)
//根据尾号转变为10个分区,分别写到10个文件
data.map((_,1)).partitionBy(new MyPartitioner(10)).map(_._1).saveAsTextFile("file:///usr/local/spark/mycode/rdd/partitioner")
}
}
2.2 一个综合实例
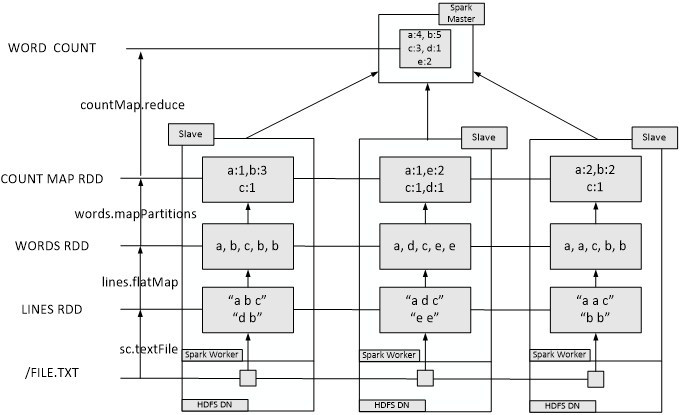
假设有一个本地文件word.txt,里面包含了很多行文本,每行文本由多个单词构成,单词之间用空格分隔。可以使用如下语句进行词频统计(即统计每个单词出现的次数):
scala> val lines = sc. //代码一行放不下,可以在圆点后回车,在下行继续输入
| textFile("file:///usr/local/spark/mycode/wordcount/word.txt")
scala> val wordCount = lines.flatMap(line => line.split(" ")).
| map(word => (word, 1)).reduceByKey((a, b) => a + b)
scala> wordCount.collect()
scala> wordCount.foreach(println)
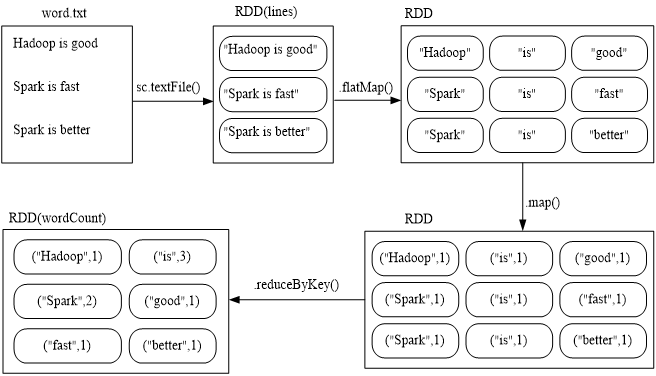
在实际应用中,单词文件可能非常大,会被保存到分布式文件系统HDFS中,Spark和Hadoop会统一部署在一个集群上.
2.3 键值对RDD
2.3.1 键值对RDD的创建
(1)第一种创建方式:从文件中加载
可以采用多种方式创建Pair RDD,其中一种主要方式是使用map()函数来实现
scala> val lines = sc.textFile("file:///usr/local/spark/mycode/pairrdd/word.txt")
lines: org.apache.spark.rdd.RDD[String] = file:///usr/local/spark/mycode/pairrdd/word.txt MapPartitionsRDD[1] at textFile at <console>:27
scala> val pairRDD = lines.flatMap(line => line.split(" ")).map(word => (word,1))
pairRDD: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[3] at map at <console>:29
scala> pairRDD.foreach(println)
(i,1)
(love,1)
(hadoop,1)
……
scala> val list = List("Hadoop","Spark","Hive","Spark")
list: List[String] = List(Hadoop, Spark, Hive, Spark)
scala> val rdd = sc.parallelize(list)
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[11] at parallelize at <console>:29
scala> val pairRDD = rdd.map(word => (word,1))
pairRDD: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[12] at map at <console>:31
scala> pairRDD.foreach(println)
(Hadoop,1)
(Spark,1)
(Hive,1)
(Spark,1)
(2)第二种创建方式:通过并行集合(数组)创建RDD
2.3.2 常用的键值对RDD转换操作
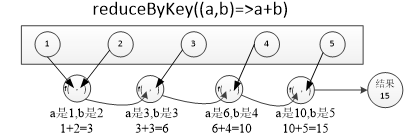
- reduceByKey(func)
reduceByKey(func)的功能是,使用func函数合并具有相同键的值
(Hadoop,1)
(Spark,1)
(Hive,1)
(Spark,1)
scala> pairRDD.reduceByKey((a,b)=>a+b).foreach(println)
(Spark,2)
(Hive,1)
(Hadoop,1)
- groupByKey()
groupByKey()的功能是,对具有相同键的值进行分组.
比如,对四个键值对(“spark”,1)、(“spark”,2)、(“hadoop”,3)和(“hadoop”,5),采用groupByKey()后得到的结果是:(“spark”,(1,2))和(“hadoop”,(3,5))
(Hadoop,1)
(Spark,1)
(Hive,1)
(Spark,1)
scala> pairRDD.groupByKey()
res15: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[15] at groupByKey at <console>:34
- reduceByKey和groupByKey的区别
- reduceByKey用于对每个key对应的多个value进行merge操作,最重要的是它能够在本地先进行merge操作,并且merge操作可以通过函数自定义
- groupByKey也是对每个key进行操作,但只生成一个sequence,groupByKey本身不能自定义函数,需要先用groupByKey生成RDD,然后才能对此RDD通过map进行自定义函数操作
scala> val words = Array("one", "two", "two", "three", "three", "three")
scala> val wordPairsRDD = sc.parallelize(words).map(word => (word, 1))
scala> val wordCountsWithReduce = wordPairsRDD.reduceByKey(_ + _)
scala> val wordCountsWithGroup = wordPairsRDD.groupByKey().map(t => (t._1, t._2.sum))
//上面得到的wordCountsWithReduce和wordCountsWithGroup是完全一样的,但是,它们的内部运算过程是不同的
- keys
keys只会把Pair RDD中的key返回形成一个新的RDD
(Hadoop,1)
(Spark,1)
(Hive,1)
(Spark,1)
scala> pairRDD.keys
res17: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[17] at keys at <console>:34
scala> pairRDD.keys.foreach(println)
Hadoop
Spark
Hive
Spark
- values
values只会把Pair RDD中的value返回形成一个新的RDD。
(Hadoop,1)
(Spark,1)
(Hive,1)
(Spark,1)
scala> pairRDD.values
res0: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[2] at values at <console>:34
scala> pairRDD.values.foreach(println)
1
1
1
1
- sortByKey()
sortByKey()的功能是返回一个根据键排序的RDD
(Hadoop,1)
(Spark,1)
(Hive,1)
(Spark,1)
scala> pairRDD.sortByKey()
res0: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[2] at sortByKey at <console>:34
scala> pairRDD.sortByKey().foreach(println)
(Hadoop,1)
(Hive,1)
(Spark,1)
(Spark,1)
- sortByKey()和sortBy()
scala> val d1 = sc.parallelize(Array((“c",8),(“b“,25),(“c“,17),(“a“,42),(“b“,4),(“d“,9),(“e“,17),(“c“,2),(“f“,29),(“g“,21),(“b“,9)))
scala> d1.reduceByKey(_+_).sortByKey(false).collect
res2: Array[(String, Int)] = Array((g,21),(f,29),(e,17),(d,9),(c,27),(b,38),(a,42))
scala> val d2 = sc.parallelize(Array((“c",8),(“b“,25),(“c“,17),(“a“,42),(“b“,4),(“d“,9),(“e“,17),(“c“,2),(“f“,29),(“g“,21),(“b“,9)))
scala> d2.reduceByKey(_+_).sortBy(_._2,false).collect
res4: Array[(String, Int)] = Array((a,42),(b,38),(f,29),(c,27),(g,21),(e,17),(d,9))
- mapValues(func)
对键值对RDD中的每个value都应用一个函数,但是,key不会发生变化
(Hadoop,1)
(Spark,1)
(Hive,1)
(Spark,1)
scala> pairRDD.mapValues(x => x+1)
res2: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[4] at mapValues at <console>:34
scala> pairRDD.mapValues(x => x+1).foreach(println)
(Hadoop,2)
(Spark,2)
(Hive,2)
(Spark,2)
- join
join就表示内连接。对于内连接,对于给定的两个输入数据集(K,V1)和(K,V2),只有在两个数据集中都存在的key才会被输出,最终得到一个(K,(V1,V2))类型的数据集。
scala> val pairRDD1 = sc.parallelize(Array(("spark",1),("spark",2),("hadoop",3),("hadoop",5)))
pairRDD1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[24] at parallelize at <console>:27
scala> val pairRDD2 = sc.parallelize(Array(("spark","fast")))
pairRDD2: org.apache.spark.rdd.RDD[(String, String)] = ParallelCollectionRDD[25] at parallelize at <console>:27
scala> pairRDD1.join(pairRDD2)
res9: org.apache.spark.rdd.RDD[(String, (Int, String))] = MapPartitionsRDD[28] at join at <console>:32
scala> pairRDD1.join(pairRDD2).foreach(println)
(spark,(1,fast))
(spark,(2,fast))
combineByKey
https://www.cnblogs.com/jagel-95/p/10103387.html
2.3.3 阶段练习实例
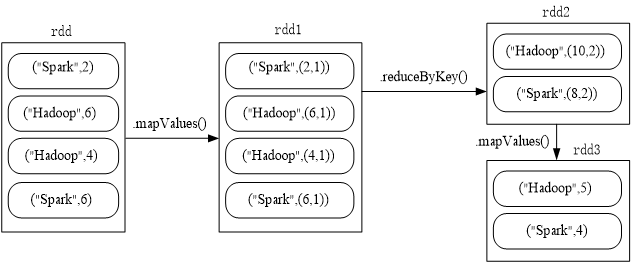
题目:给定一组键值对(“spark”,2),(“hadoop”,6),(“hadoop”,4),(“spark”,6),键值对的key表示图书名称,value表示某天图书销量,请计算每个键对应的平均值,也就是计算每种图书的每天平均销量。
scala> val rdd = sc.parallelize(Array(("spark",2),("hadoop",6),("hadoop",4),("spark",6)))
rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[38] at parallelize at <console>:27
scala> rdd.mapValues(x => (x,1)).reduceByKey((x,y) => (x._1+y._1,x._2 + y._2)).mapValues(x => (x._1 / x._2)).collect()
res22: Array[(String, Int)] = Array((spark,4), (hadoop,5))
2.4 综合案例
2.4.1 案例1:求TOP值

import org.apache.spark.{
SparkConf, SparkContext}
object TopN {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("TopN").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("ERROR")
val lines = sc.textFile("hdfs://localhost:9000/user/hadoop/spark/mycode/rdd/examples",2)
var num = 0;
val result = lines.filter(line => (line.trim().length > 0) && (line.split(",").length == 4))
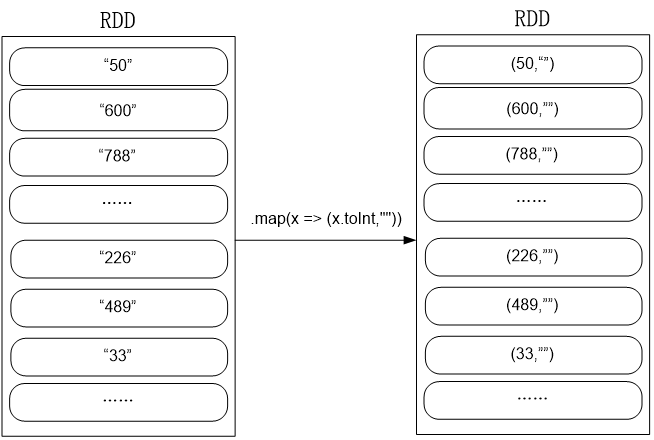
.map(_.split(",")(2))
.map(x => (x.toInt,""))
.sortByKey(false)
.map(x => x._1).take(5)
.foreach(x => {
num = num + 1
println(num + "\t" + x)
})
}
}
val lines = sc.textFile("hdfs://localhost:9000/user/hadoop/spark/chapter5”,2)

val result = lines.filter(line => (line.trim().length > 0) && (line.split(",").length == 4))
.map(_.split(",")(2))
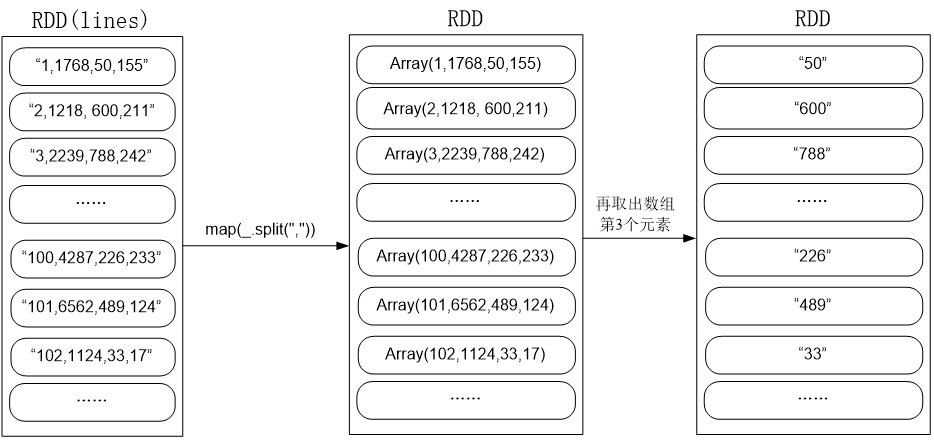
.map(x => (x.toInt,""))
.sortByKey(false)
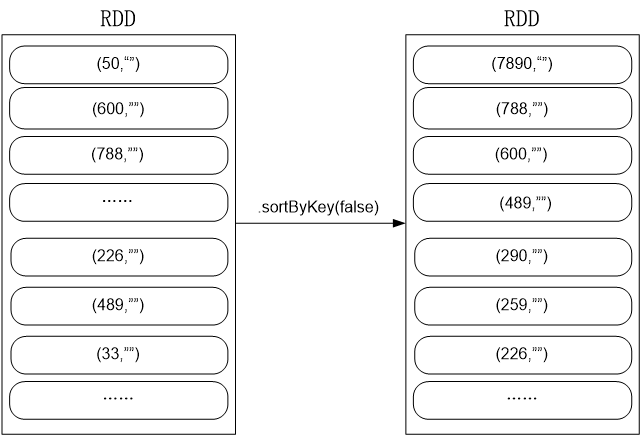
.map(x => x._1). take(5)

.foreach(x => {
num = num + 1
println(num + "\t" + x)
})

2.4.2 案例2:求最大最小值
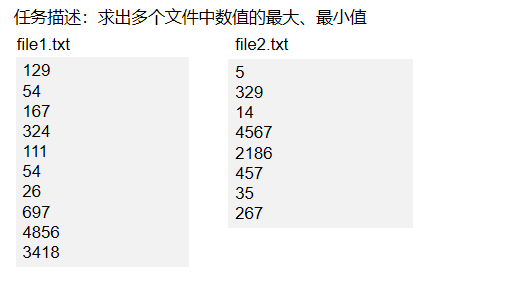
import org.apache.spark.{
SparkConf, SparkContext}
object MaxAndMin {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName(“MaxAndMin“).setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("ERROR")
val lines = sc.textFile("hdfs://localhost:9000/user/hadoop/spark/chapter5", 2)
val result = lines.filter(_.trim().length>0).map(line => ("key",line.trim.toInt)).groupByKey().map(x => {
var min = Integer.MAX_VALUE
var max = Integer.MIN_VALUE
for(num <- x._2){
if(num>max){
max = num
}
if(num<min){
min = num
}
}
(max,min)
}).collect.foreach(x => {
println("max\t"+x._1)
println("min\t"+x._2)
})
}
}
val lines = sc.textFile("hdfs://localhost:9000/user/hadoop/spark/chapter5", 2)
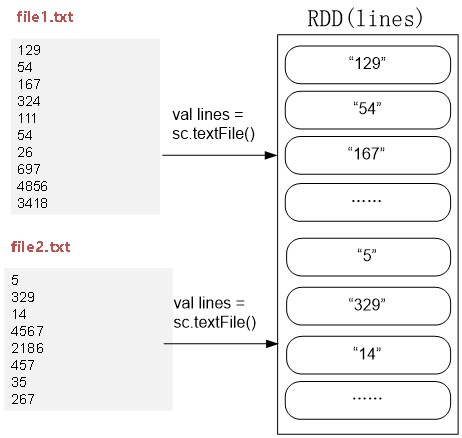
val result = lines.filter(_.trim().length>0).map(line => ("key",line.trim.toInt))
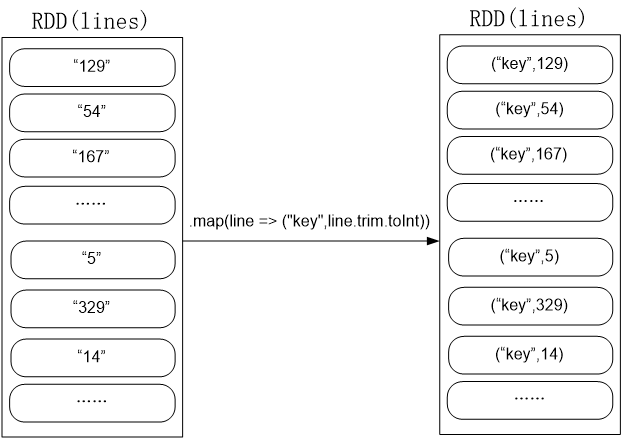
.groupByKey()

val result = lines.filter(_.trim().length>0).map(line => ("key",line.trim.toInt)).groupByKey().map(x => {
var min = Integer.MAX_VALUE
var max = Integer.MIN_VALUE
for(num <- x._2){
if(num>max){
max = num
}
if(num<min){
min = num
}
}
(max,min)
}).collect.foreach(x => {
println("max\t"+x._1)
println("min\t"+x._2)
})
}
}
2.4.3 案例3:文件排序
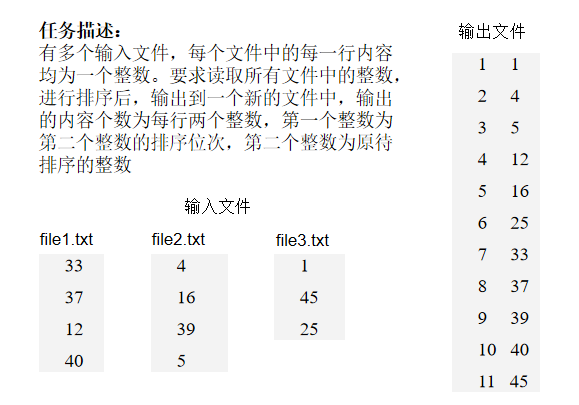
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.apache.spark.HashPartitioner
object FileSort {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("FileSort")
val sc = new SparkContext(conf)
val dataFile = "file:///usr/local/spark/mycode/rdd/data"
val lines = sc.textFile(dataFile,3)
var index = 0
val result = lines.filter(_.trim().length>0).map(n=>(n.trim.toInt,"")).partitionBy(new HashPartitioner(1)).sortByKey().map(t => {
index += 1
(index,t._1)
})
result.saveAsTextFile("file:///usrl/local/spark/mycode/rdd/examples/result")
}
}
2.4.4 案例4:二次排序

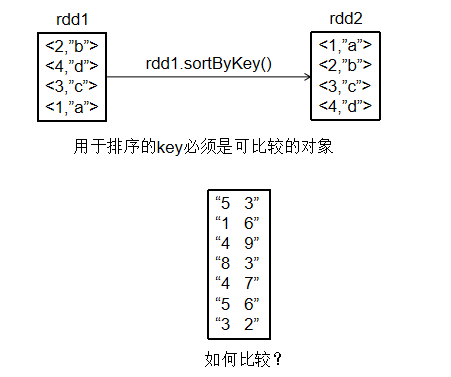

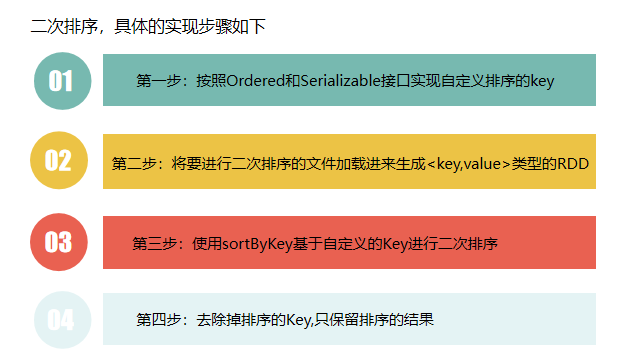
package cn.edu.xmu.spark
class SecondarySortKey(val first:Int,val second:Int) extends Ordered [SecondarySortKey] with Serializable {
def compare(other:SecondarySortKey):Int = {
if (this.first - other.first !=0) {
this.first - other.first
} else {
this.second - other.second
}
}
}
package cn.edu.xmu.spark
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object SecondarySortApp {
def main(args:Array[String]){
val conf = new SparkConf().setAppName("SecondarySortApp").setMaster("local")
val sc = new SparkContext(conf)
val lines = sc.textFile("file:///usr/local/spark/mycode/rdd/examples/file1.txt", 1)
val pairWithSortKey = lines.map(line=>(new SecondarySortKey(line.split(" ")(0).toInt, line.split(" ")(1).toInt),line))
val sorted = pairWithSortKey.sortByKey(false)
val sortedResult = sorted.map(sortedLine =>sortedLine._2)
sortedResult.collect().foreach (println)
}
}
val lines = sc.textFile(“file:///usr/local/spark/mycode/rdd/file1.txt", 1)
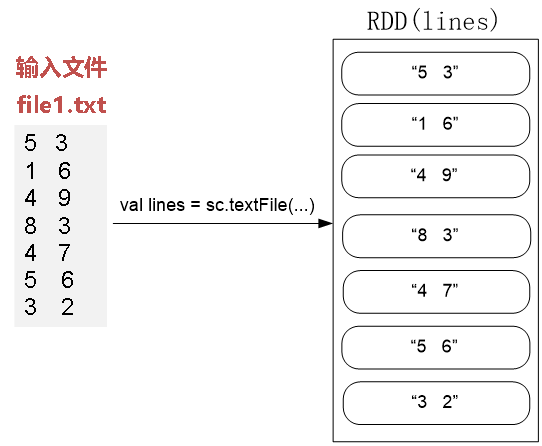
val pairWithSortKey =
lines.map(line=>(new SecondarySortKey(line.split(" ")(0).toInt, line.split(" ")(1).toInt),line))
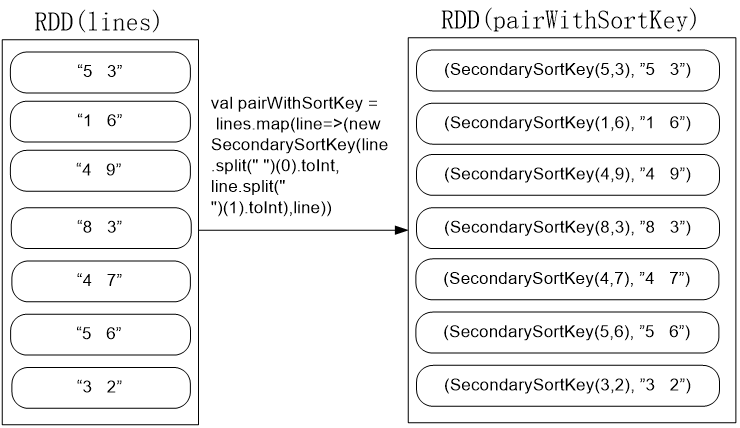
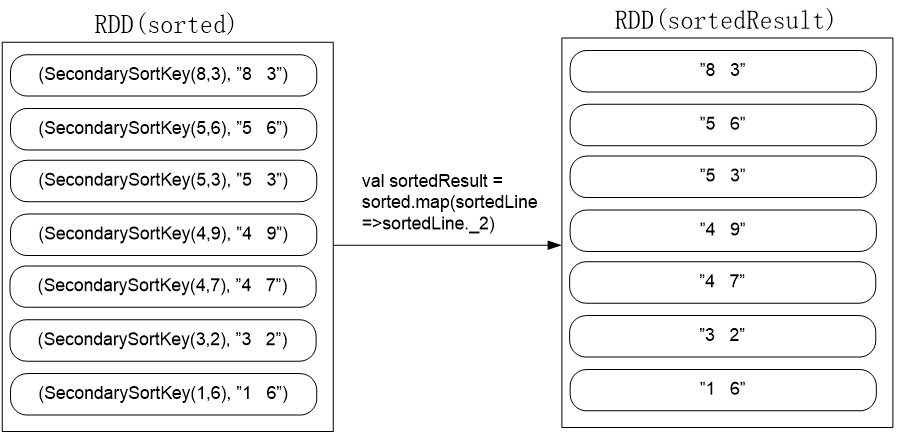
val sorted = pairWithSortKey.sortByKey(false)
该代码会按照SecondarySortKey对象的降序排序,执行后的效果如下:

val sortedResult = sorted.map(sortedLine =>sortedLine._2)
2.4.5 案例5:连接操作
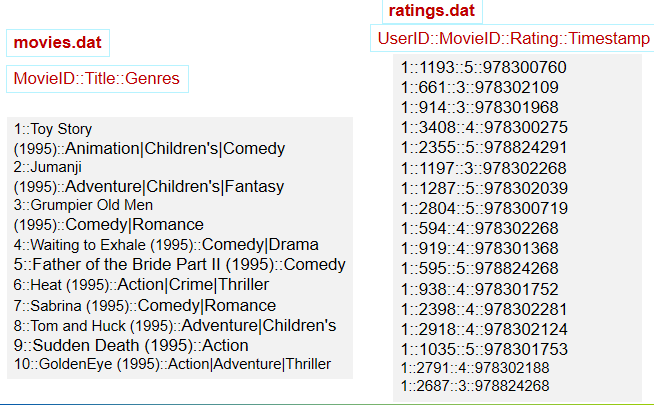
任务描述:在推荐领域有一个著名的开放测试集,下载链接是:http://grouplens.org/datasets/movielens/,该测试集包含三个文件,分别是ratings.dat、sers.dat、movies.dat,具体介绍可阅读:README.txt。请编程实现:通过连接ratings.dat和movies.dat两个文件得到平均得分超过4.0的电影列表,采用的数据集是:ml-1m
import org.apache.spark._
import SparkContext._
object SparkJoin {
def main(args: Array[String]) {
if (args.length != 3 ){
println("usage is WordCount <rating> <movie> <output>")
return
}
val conf = new SparkConf().setAppName("SparkJoin").setMaster("local")
val sc = new SparkContext(conf)
// Read rating from HDFS file
val textFile = sc.textFile(args(0))
//extract (movieid, rating)
val rating = textFile.map(line => {
val fileds = line.split("::")
(fileds(1).toInt, fileds(2).toDouble)
})
//get (movieid,ave_rating)
val movieScores = rating
.groupByKey()
.map(data => {
val avg = data._2.sum / data._2.size
(data._1, avg)
})
// Read movie from HDFS file
val movies = sc.textFile(args(1))
val movieskey = movies.map(line => {
val fileds = line.split("::")
(fileds(0).toInt, fileds(1)) //(MovieID,MovieName)
}).keyBy(tup => tup._1)
// by join, we get <movie, averageRating, movieName>
val result = movieScores
.keyBy(tup => tup._1)
.join(movieskey)
.filter(f => f._2._1._2 > 4.0)
.map(f => (f._1, f._2._1._2, f._2._2._2))
result.saveAsTextFile(args(2))
}
}
// Read rating from HDFS file
val textFile = sc.textFile(args(0))

//extract (movieid, rating)
val rating = textFile.map(line => {
val fileds = line.split("::")
(fileds(1).toInt, fileds(2).toDouble)
})
//get (movieid,ave_rating)
val movieScores = rating
.groupByKey()
.map(data => {
val avg = data._2.sum / data._2.size
(data._1, avg)
})
//extract (movieid, rating)
val rating = textFile.map(line => {
val fileds = line.split("::")
(fileds(1).toInt, fileds(2).toDouble)
})
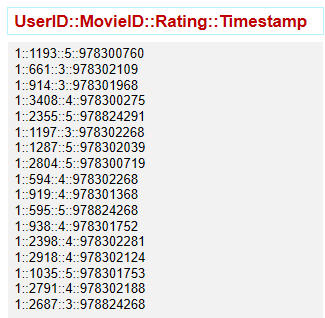
rating.groupByKey()
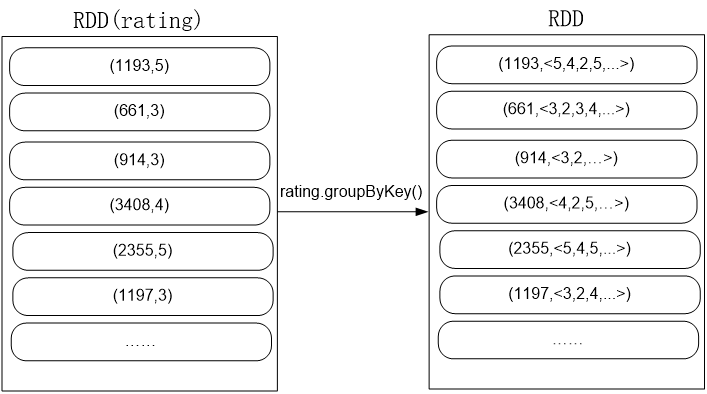
.map(data => {
val avg = data._2.sum / data._2.size
(data._1, avg)
})
// Read movie from HDFS file
val movies = sc.textFile(args(1))
val movieskey = movies.map(line => {
val fileds = line.split("::")
(fileds(0).toInt, fileds(1)) //(MovieID,MovieName)
}).keyBy(tup => tup._1)
// by join, we get <movie, averageRating, movieName>
val result = movieScores
.keyBy(tup => tup._1)
.join(movieskey)
.filter(f => f._2._1._2 > 4.0)
.map(f => (f._1, f._2._1._2, f._2._2._2))
result.saveAsTextFile(args(2))
}
}
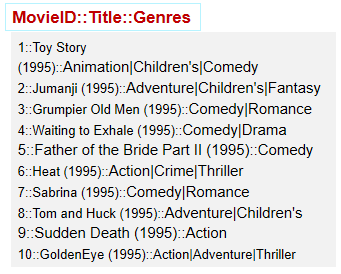
// Read movie from HDFS file
val movies = sc.textFile(args(1))
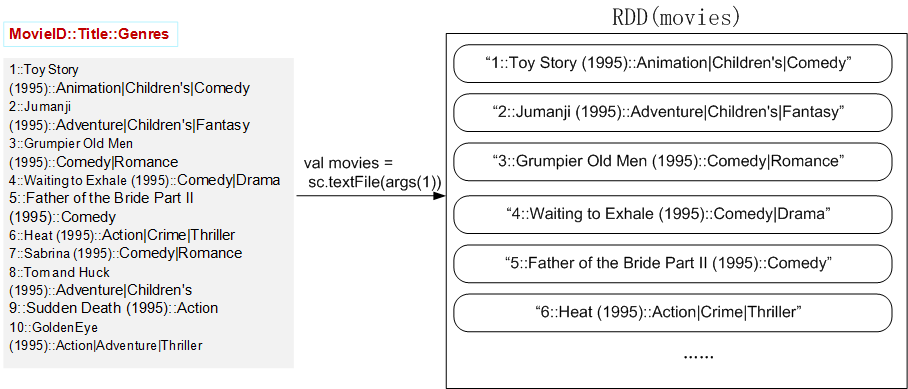
movies.map(line => {
val fileds = line.split("::")
(fileds(0).toInt, fileds(1)) //(MovieID,MovieName)
})
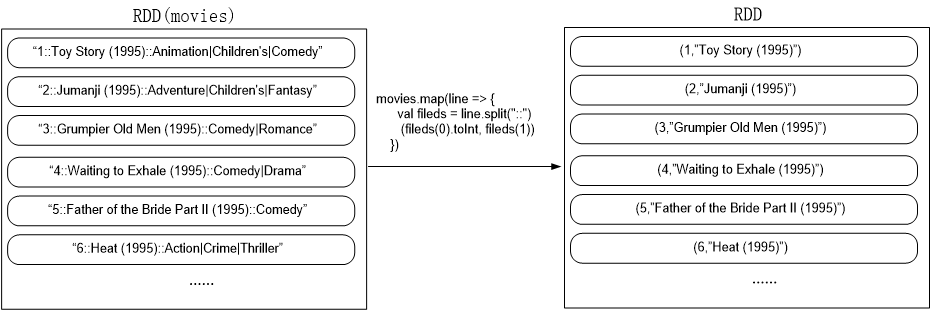
.keyBy(tup => tup._1)
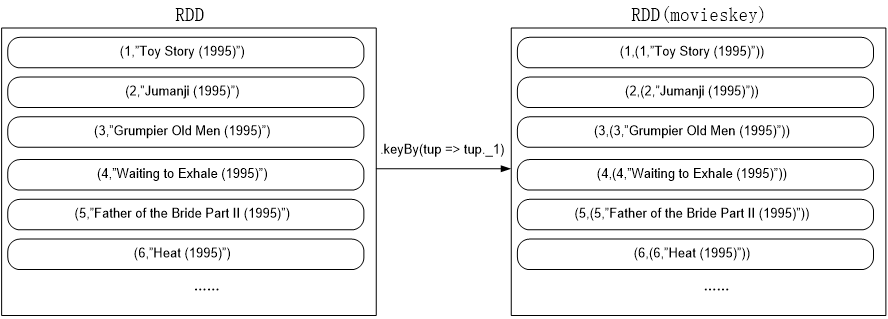
movieScores.keyBy(tup => tup._1)
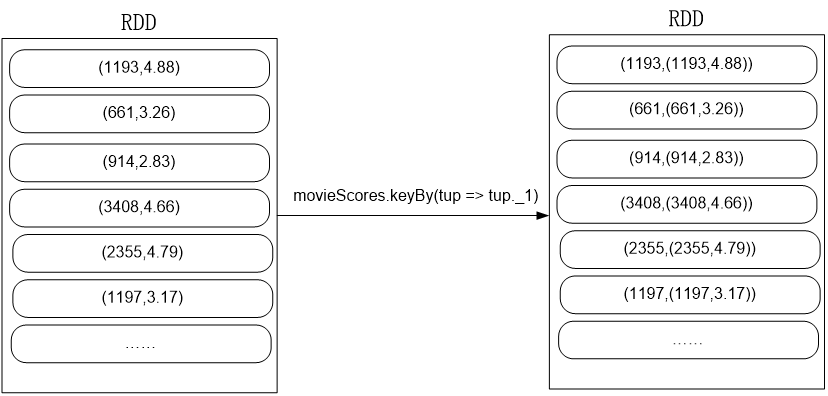
.join(movieskey)
执行join时,参与连接的两个RDD分别如下:
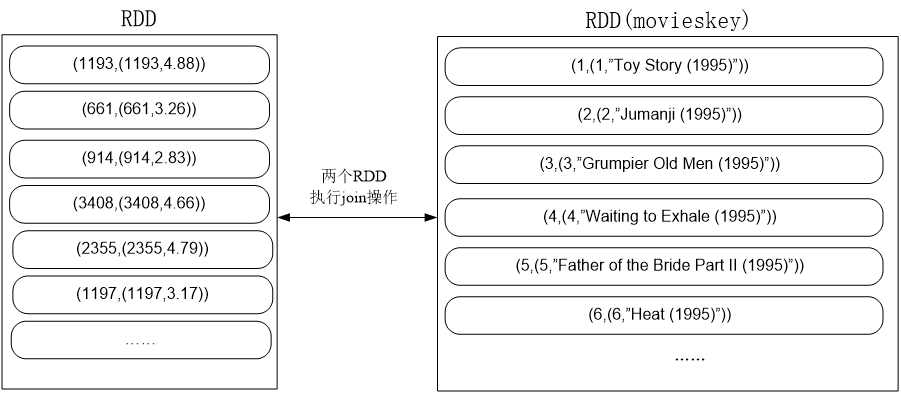
.join(movieskey) . filter(f => f._2._1._2 > 4.0) . map(f => (f._1, f._2._1._2, f._2._2._2))
执行join时,key相同的来自两个RDD的元素可以进行连接:
