环境:
操作系统:CentOS 6.4 x64
数据库:HighGoDB
pgpool版本:3.3.4
db1-IP:192.168.100.198
db2-IP:192.168.100.199
VIP:192.168.100.222N次故障恢复主要是三个脚本的设置,需要根据自己的环境进行相应的编写
1、SSH互信(两节点设置)
(1)首先更改主机名
[root@localhost ~]# vi /etc/sysconfig/network
HOSTNAME=db1
(2)更改hosts文件
[root@db1 ~]# vi /etc/hosts
192.168.100.198 db1
192.168.100.199 db2
(3)重启机器生效
(4)互信配置
[highgo@db1 ~]$ ssh-keygen -t rsa
[highgo@db1 ~]$ ssh-copy-id -i .ssh/id_rsa.pub highgo@db1
[highgo@db1 ~]$ ssh-copy-id -i .ssh/id_rsa.pub highgo@db2
[highgo@db1 ~]$ ssh-copy-id -i .ssh/id_rsa.pub root@db1
[highgo@db1 ~]$ ssh-copy-id -i .ssh/id_rsa.pub root@db2
2、安装HGDB(两节点安装)
3、安装pgpool(在两节点均安装)
(1)安装pgpool
[highgo@db1 pgpool-II-3.3.4]$ ./configure
prefix=/home/highgo/pgpool
(2)安装pgpool的两个函数
pgpool-regclass函数:
[highgo@db1 pgpool-regclass]$ pwd /home/highgo/Desktop/pgpool-II-3.3.4/sql/pgpool-regclass
[highgo@db1 pgpool-regclass]$ make
[highgo@db1 pgpool-regclass]$ make install
pgpool-recovery函数:
[highgo@db1 pgpool-recovery]$ pwd /home/highgo/Desktop/pgpool-II-3.3.4/sql/pgpool-recovery
[highgo@db1 pgpool-recovery]$ make
[highgo@db1 pgpool-recovery]$ make install
注:为了方便执行pgpool的命令,在环境变量PATH中加入pgpool的bin目录,如:
PATH= $PATH:$HOME/bin:$HG_HOME/bin:/home/highgo/pgpool/bin生效或重启机器生效
source .bash_profile
4、流复制配置
注:配置前需要将备库的数据库服务停掉
(1)主库配置:
a、为了方便操作,只使用highgo用户
b、设置postgresql.conf
listen_addresses = ‘*’
checkpoint_segments = 16
archive_mode = on
archive_command = ‘/bin/date’
max_wal_senders = 3
wal_keep_segments = 16
wal_level = hot_standby
hot_standby = on
c、设置pg_hba.conf
host replication highgo 192.168.100.222/24 md5
d、重启生效
pg_ctl restart
(2)备库配置:
a、创建.pgpass文件
格式为:hostname:port:database:username:password
[highgo@db2 ~]$ vi .pgpass
*:5866:*:highgo:highgo123注:.pgpass文件的权限因为600,即需要执行chmod 600 .pgpass ;否则会在执行pg_basebackup时报错如下:
[highgo@db2 hgdb]$ pg_basebackup -D data -Fp -Xs -v -P -h 192.168.100.200 -p 5866 -U highgo
WARNING: password file "/home/highgo/.pgpass" has group or world access; permissions should be u=rw (0600) or less
Password:
b、流复制配置
【首先需要将原有data目录更改为其他名字,并新建一data目录】
[highgo@db2 hgdb]$ mv data data.old
【pg_basebackup】
[highgo@db2 hgdb]$ pg_basebackup -D data -Fp -Xs -v -P -h 192.168.100.198 -p 5866 -U highgo
transaction log start point: 0/2000060 on timeline 1
pg_basebackup: starting background WAL receiver
21329/21329 kB (100%), 1/1 tablespace
transaction log end point: 0/2000128
pg_basebackup: waiting for background process to finish streaming …
pg_basebackup: base backup completed
注:若执行pg_basebackup显示为下,可以关闭防火墙重新尝试
[highgo@db2 hgdb]$ pg_basebackup -D data -Fp -Xs -v -P -h 192.168.100.198 -p 5866 -U highgo
pg_basebackup: could not connect to server: could not connect to server: No route to host
Is the server running on host "192.168.100.198" and accepting
TCP/IP connections on port 5866?
【将data目录的权限改为700】
[highgo@db2 hgdb]$ chmod 700 data
注:需要将data目录权限修改为700,否则会在启动数据库时报错如下:
[highgo@db2 data]$ pg_ctl start
server starting
[highgo@db2 data]$ 致命错误: 组或其他用户都可以访问数据目录 "/home/highgo/hgdb/data"
详细信息: 权限应该为 u=rwx (0700).
【从库recovery.conf文件】
[highgo@db2 data]$ vi recovery.conf
standby_mode = on
primary_conninfo = 'host=192.168.100.200 port=5866 user=highgo'
trigger_file = '/home/highgo/hgdb/data/trigger.5866'【备库数据库服务,完成流复制配置】
[highgo@db2 data]$ pg_ctl start
server starting
[highgo@db2 data]$ 日志: 数据库系统中断;上一次的启动时间是在2016-11-28 19:34:15 PST
日志: 正在进入备用模式
日志: redo 在 0/2000020 开始
日志: 在0/20000E0上已到达一致性恢复状态
日志: 数据库系统准备接受只读请求的连接
日志: 流复制成功连接到主服务器
若出现报错如下:
[highgo@db2 hgdb]$ pg_ctl start
server starting
[highgo@db2 hgdb]$ 日志: 无法绑定 IPv4 套接字: 地址已在使用
提示: 是否有其它 postmaster 已经在端口 5866 上运行了? 如果没有, 请等待几秒钟后然后再重试.
日志: 无法绑定 IPv6 套接字: 地址已在使用
提示: 是否有其它 postmaster 已经在端口 5866 上运行了? 如果没有, 请等待几秒钟后然后再重试.
警告: 无法为 "*" 创建监听套接字
致命错误: 无法创建TCP/IP套接字是因为在配置流复制时,db2节点的数据库处于启动状态,所以在配置前最好关闭db2数据库,若忘记关闭出现该错误,查询进程号并kill即可
[highgo@db2 hgdb]$ lsof -i:5866
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
postgres 35114 highgo 3u IPv6 156584 0t0 TCP localhost:5866 (LISTEN)
postgres 35114 highgo 4u IPv4 156585 0t0 TCP localhost:5866 (LISTEN)
[highgo@db2 hgdb]$
[highgo@db2 hgdb]$ kill -9 35114
[highgo@db2 hgdb]$ lsof -i:5866
[highgo@db2 hgdb]$
5、在template1创建扩展(主库执行)
[highgo@db1 ~]$ psql template1
Password:
psql (3.0.2)
Type “help” for help.
template1=# create extension pgpool_regclass;
CREATE EXTENSION
template1=# create extension pgpool_recovery;
CREATE EXTENSION
6、配置pgpool(两节点配置)
a、pcp.conf配置
[highgo@db1 etc]$ pwd
/home/highgo/pgpool/etc
[highgo@db1 etc]$ cp pcp.conf.sample pcp.conf
[highgo@db1 etc]$ pg_md5 -u highgo -p
password:
fc8db03f0d7adbd8f1cd859d7cbf6094
[highgo@db1 etc]$ vi pcp.conf
highgo:fc8db03f0d7adbd8f1cd859d7cbf6094
b、配置ifconfig、arping执行权限
[root@db1 ~]# chmod u+s /sbin/ifconfig
[root@db1 ~]# chmod u+s /usr/sbin/
c、开启日志
[root@db1 ~]# vi /etc/rsyslog.conf
#pgpool
local0.* /var/log/pgpool.log
重启rsyslog服务
[root@db1 ~]# service rsyslog restart
Shutting down system logger: [ OK ]
Starting system logger: [ OK ]
d、配置pgpool.conf
主节点:
listen_addresses = ‘*’
backend_hostname0 = ‘db1’
backend_port0 = 5866
backend_weight0 = 1
backend_data_directory0 = ‘/home/highgo/hgdb/data’
backend_flag0 = ‘ALLOW_TO_FAILOVER’
backend_hostname1 = ‘db2’
backend_port1 = 5866
backend_weight1 = 1
backend_data_directory1 = ‘/home/highgo/hgdb/data’
backend_flag1 = ‘ALLOW_TO_FAILOVER’
enable_pool_hba = on
log_destination = ‘syslog’
log_connections = on
log_hostname = on
log_statement = on
pid_file_name = ‘/home/highgo/pgpool/pgpool.pid’
load_balance_mode = on
master_slave_mode = on
master_slave_sub_mode = ‘stream’
sr_check_period = 5
sr_check_user = ‘highgo’
sr_check_password = ‘highgo123’
delay_threshold = 10000000
health_check_period = 5
health_check_timeout = 20
health_check_user = ‘highgo’
health_check_password = ‘highgo123’
health_check_max_retries = 3
failover_command = ‘/home/highgo/pgpool/failover.sh %d %H /home/highgo/hgdb/data/trigger.5866’
recovery_user = ‘highgo’
recovery_password = ‘highgo123’
recovery_1st_stage_command = ‘basebackup.sh’
use_watchdog = on
wd_hostname = ‘db1’
delegate_IP = ‘192.168.100.222’
heartbeat_destination0 = ‘db2’
heartbeat_device0 = ‘eth0’
other_pgpool_hostname0 = ‘db2’
other_pgpool_port0 = 9999
other_wd_port0 = 9000
备节点:
大致同主节点配置,不同的地方:
wd_hostname = ‘db2’
heartbeat_destination0 = ‘db1’
other_pgpool_hostname0 = ‘db1’
e、在pgpool目录下创建failover.sh文件—主库服务stop后,会触发执行该脚本,在备库创建文件trigger.5866
注:查资料显示建议使用promote的方式,但是使用设置的时候,报错显示因为lib的问题失败,不知道该怎么改?
文件内容:
#! /bin/sh
# Failover command for streaming replication.
# This script assumes that DB node 0 is primary, and 1 is standby.
#
# If standby goes down, do nothing. If primary goes down, create a
# trigger file so that standby takes over primary node.
#
# Arguments: $1: failed node id. $2: new master hostname. $3: path to
# trigger file.
host1=db1
host2=db2
failed_node=$1
new_master=$2
trigger_file=$3
# Do nothing if standby goes down.
# Create the trigger file.
if [ $failed_node = 0 ] && [ $new_master = $host2 ]; then
/usr/bin/ssh -T $new_master /bin/touch $trigger_file
elif [ $failed_node = 1 ] && [ $new_master = $host1 ]; then
/usr/bin/ssh -T $new_master /bin/touch $trigger_file
else
exit 0;
fi
exit 0;f、在data目录配置原主库stop后,启动并恢复为备库的脚本
basebackup.sh脚本:
#! /bin/sh
# Recovery script for streaming replication.
# This script assumes that DB node 0 is primary, and 1 is standby.
#
HOST1=db1
HOST2=db2
datadir=$1
desthost=$2
destdir=$3
if [ $desthost = $HOST1 ];then
HOST_S=$HOST2
else
HOST_S=$HOST1
fi
psql -h $HOST_S -c "SELECT pg_start_backup('Streaming Replication', true)"
rsync -C -a --delete -e ssh --exclude postgresql.conf --exclude postmaster.pid \
--exclude postmaster.opts --exclude pg_log --exclude pg_xlog \
--exclude recovery.conf $datadir/ $desthost:$destdir/
ssh -T $desthost rm $destdir/recovery.done
ssh -T $desthost rm $destdir/trigger.5866
cat > $datadir/recovery.conf <<EOF
standby_mode = on
primary_conninfo = 'host=$HOST_S port=5866 user=highgo'
trigger_file = '/home/highgo/hgdb/data/trigger.5866'
EOF
scp $datadir/recovery.conf highgo@$desthost:$destdir
rm -rf $datadir/recovery.conf
psql -h $HOST_S -c "SELECT pg_stop_backup()" pool_remote_start脚本:
#! /bin/sh
#
# Start PostgreSQL on the recovery target node
#
user=root
if [ $# -ne 2 ]
then
echo "pgpool_remote_start remote_host remote_datadir"
exit 1
fi
DEST=$1
DESTDIR=$2
#PGCTL=/home/highgo/hgdb/bin/pg_ctl
#$PGCTL -w -D $DESTDIR start 2>/dev/null 1>/dev/null < /dev/null &
#/usr/bin/ssh -T $user@$DEST $PGCTL -w -D $DESTDIR start
/usr/bin/ssh -T $user@$DEST /sbin/service hgdb-se3.0.2 start注:两脚本作用结果
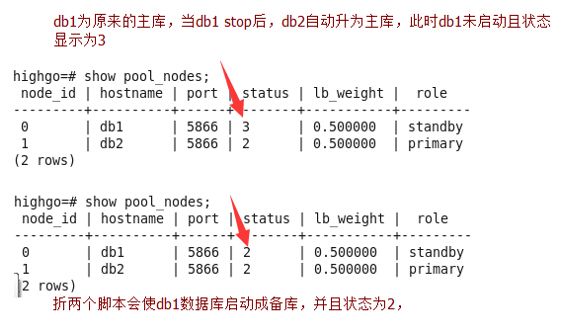
g、配置pool_hba.conf
host all all 192.168.100.199/24 md5
h、生成pool_passwd文件
[highgo@db1 etc]$ pg_md5 -m -p -u highgo pool_passwd
password:
[highgo@db1 etc]$ cat pool_passwd
highgo:md5614aeb636ab143b790547ce463ec1741
7、启动pgpool
若启动后psql -h vip -p 9999一直显示为“没有到主机的路由”,可以检查是否pgpool.conf中设置的设备名称eth?与机器实际的设备名称不相符
8、测试
a、登录
[highgo@db1 pgpool]$ psql -h 192.168.100.222 -p 9999
Password:
psql (3.0.2)
Type “help” for help.
b、查看两节点状态
highgo=# show pool_nodes;
node_id | hostname | port | status | lb_weight | role
———+———-+——+——–+———–+———
0 | db1 | 5866 | 2 | 0.500000 | primary
1 | db2 |5866 | 2 | 0.500000 | standby
(2 rows)
c、db1停止数据库服务,是否成功切换
[highgo@db1 pgpool]$ psql -h 192.168.100.222 -p 9999
Password:
psql (3.0.2)
Type “help” for help.
highgo=# show pool_nodes;
node_id | hostname | port | status | lb_weight | role
———+———-+——+——–+———–+———
0 | db1 | 5866 | 3 | 0.500000 | standby
1 | db2 | 5866 | 2 | 0.500000 | primary
(2 rows)
成功切换,此时db1数据库stop,状态显示为3
d、在线恢复db1
[highgo@db2 pgpool]$ pcp_recovery_node -d 5 db1 9898 highgo highgo123 0
DEBUG: send: tos=”R”, len=44
DEBUG: recv: tos=”r”, len=21, data=AuthenticationOK
DEBUG: send: tos=”D”, len=6
Mon Aug 8 19:03:07 PDT 2016
pg_start_backup
………………………….
0/1D000060
(1 行记录)
Mon Aug 8 19:03:10 PDT 2016
Mon Aug 8 19:03:10 PDT 2016
注意: pg_stop_backup 执行完成,所有需要的WAL段都已经归档完成。
pg_stop_backup
………………………….
0/1D000128
(1 行记录)
Starting HighGo Database Server:
waiting for server to start…. done
server started
HighGo Database Server started successfully
DEBUG: recv: tos=”c”, len=20, data=CommandComplete
DEBUG: send: tos=”X”, len=4
查看状态,db1恢复成功
[highgo@db2 pgpool]$ psql -h 192.168.100.222 -p 9999
Password:
psql (3.0.2)
Type “help” for help.
highgo=# show pool_nodes;
node_id | hostname | port | status | lb_weight | role
———+———-+——+——–+———–+———
0 | db1 | 5866 | 2 | 0.500000 | standby
1 | db2 | 5866 | 2 | 0.500000 | primary
(2 rows)
e、将db2数据库stop
[highgo@db2 pgpool]$ pg_ctl -m fast stop
日志: 接收到快速 (fast) 停止请求
日志: 中断任何激活事务
致命错误: 由于管理员命令中断联接
日志: 正在关闭autovacuum启动进程
日志: 正在关闭
waiting for server to shut down….Mon Aug 8 19:03:46 PDT 2016
日志: 数据库系统已关闭
.致命错误: 数据库系统停止中
致命错误: 数据库系统停止中
done
server stopped
查看状态,db1成功切换为主库,db2 stop,状态为3
[highgo@db2 pgpool]$ psql -h 192.168.100.222 -p 9999
Password:
psql (3.0.2)
Type “help” for help.
highgo=# show pool_nodes;
node_id | hostname | port | status | lb_weight | role
———+———-+——+——–+———–+———
0 | db1 | 5866 | 2 | 0.500000 | primary
1 | db2 | 5866 | 3 | 0.500000 | standby
(2 rows)
f、在线恢复db2
[highgo@db2 pgpool]$ pcp_recovery_node -d 5 db2 9898 highgo highgo123 1
DEBUG: send: tos=”R”, len=44
DEBUG: recv: tos=”r”, len=21, data=AuthenticationOK
DEBUG: send: tos=”D”, len=6
DEBUG: recv: tos=”c”, len=20, data=CommandComplete
DEBUG: send: tos=”X”, len=4
[highgo@db2 pgpool]$ psql
psql (3.0.2)
Type “help” for help.
highgo=# \q
查看状态
[highgo@db2 pgpool]$ psql -h 192.168.100.222 -p 9999
Password:
psql (3.0.2)
Type “help” for help.
highgo=# show pool_nodes;
node_id | hostname | port | status | lb_weight | role
———+———-+——+——–+———–+———
0 | db1 | 5866 | 2 | 0.500000 | primary
1 | db2 | 5866 | 2 | 0.500000 | standby
(2 rows)
g、将db1数据库stop
[highgo@db1 pgpool]$ pg_ctl -m fast stop
waiting for server to shut down……………………………….. done
server stopped
查看状态,显示db2没有成功切换为主库
[highgo@db1 pgpool]$ psql -h 192.168.100.222 -p 9999
Password:
psql (3.0.2)
Type “help” for help.
highgo=# show pool_nodes;
node_id | hostname | port | status | lb_weight | role
———+———-+——+——–+———–+———
0 | db1 | 5866 | 3 | 0.500000 | standby
1 | db2 | 5866 | 2 | 0.500000 | standby
(2 rows)
但是查看db2时显示db2已成功成为主库,可创建对象
[highgo@db2 data]$ psql
psql (3.0.2)
Type “help” for help.
highgo=# create user u4;
CREATE ROLE
此时在两节点均重启pgpool,并在启动时加-D,删除原状态
[highgo@db2 data]$ pgpool stop
stop request sent to pgpool. waiting for termination…………….done.
[highgo@db2 data]$
[highgo@db2 data]$ pgpool -D
查看状态,显示db2为主库
[highgo@db2 data]$ psql -h 192.168.100.222 -p 9999
Password:
psql (3.0.2)
Type “help” for help.
highgo=# show pool_nodes;
node_id | hostname | port | status | lb_weight | role
———+———-+——+——–+———–+———
0 | db1 | 5866 | 3 | 0.500000 | standby
1 | db2 | 5866 | 2 | 0.500000 | primary
(2 rows)