一转眼离职有一个月了,这段时间算起来一共也就参加了两次面试,不是没有面试机会(当然也可能没有),是因为一直对自己略感迷茫的状态不满,早几个月前,有段时间甚至怀疑自己得了抑郁症,每天都在思考我从哪里来,我要到哪里去,我做的工作有什么意义。
前几天看到一篇大V写的文章,讲程序员成长问题,说只要有成长的意愿就会伴随着焦虑,不管处在哪个层级上。看到这句话有点像用一个定理解决了一道难题,倍感喜悦。回想自己这几年的工作经历,总的来说可以用”混乱“来总结(当然也有一些历史原因,但这并不能被当做借口),目标一直都不清晰。这两天在看《人生七年》,颇有感触,深深的感觉,深度思考对一个人成长的重要性,回想自己,就是迷迷糊糊+间歇性焦虑吧,虽然知道存在问题,但很少针对问题做深度的思考并用实际行动去真正的解决问题。每天和朋友、同时聊着无关痛痒的话,同事间聊吃什么是永恒的话题,朋友间就是买车、买房、娶媳妇,要不就是谁结婚、买房、娶媳妇了,曾有不短的一段时间,我拒绝与他们交流,因为这些话题令我感到窒息,虽然这些是更多你我一样平常人的追求,但我看不到颜色。
在经历了比较长一段时间的痛苦和挣扎、经历的同事、朋友、亲人的极力反对下,我裸辞了,我觉得需要好好的给自己一段时间思考自己和今后的人生,我很怕在自己死去的时候对自己的一生感到苍白,但我正做着这样的事情。
最近这一个月在体系化的复习框架、语言等等,从工作年限上看我是一个高级Java程序员,由于近几年Java程序员的面试难度越来越大,所以对接下来的面试已经做好了充分的打硬仗的准备。对于学习这件事,输出是一件特别重要的时间,由于身边并没有一个跟我一样裸辞的程序员,所以我打算将我在复习、学习过程中的一些思考记录在这里,也算是一种输出和交流吧,当然如果能帮到其他的朋友,那是最好的了。
准备准备,明天就开始吧。
作为一名技术人员应该如何思考?思考技术的本质,思考技术与业务的关系,技术与个人的关系,甚至思考技术与哲学的关系,能不能把技术融入到整个大时代的变迁当中,融入到人类历史文明的发展当中? 这是多么有意思的问题,虽然现在没有答案,但是想到这些问题就让人兴奋。
文章目录
随记
苏联为什么会解体
一次世界大战的起因是什么
技术
hashmap扩容导致死循环的问题
对于hashmap在多线程环境下扩容造成循环链表的问题虽然明白,但是一直感觉有点模糊,今天冲洗梳理了一些这个逻辑,一下清楚了。
hashmap 在hash冲突不严重的情况下底层数据结构采用哈希表+链表,当容器中的数据量达到负载capacity*负载因子时,就会触发扩容,默认容量增加为原来的两倍,扩容的核心原理是遍历哈希表的每个节点,对于每个节点,再遍历这个节点对应的链表,根据新的容量重新计算哈希值,并加入到新的哈希表中,核心代码如下
//循环遍历哈希表
for(int j = 0;j < table.lenght;j ++) {
//获取当位置链表的头节点
Entry e = table[j];
if(e != null) {
do{
//假设 T1线程因为不明原因阻塞在此,T2线程完成了扩容操作
//获取当前节点的下一个节点
Entry next = e.naxt;
//根据扩容后哈希表的容量计算索引
int idx = indexFor(e.hash, newCapacity);
//将节点e添加到新的哈希表中,顺序与原来相反
e.next = newTable[idx];
newTable[idx] = e;
//继续处理下一个节点
e = next;
}while(e != null)
}
}
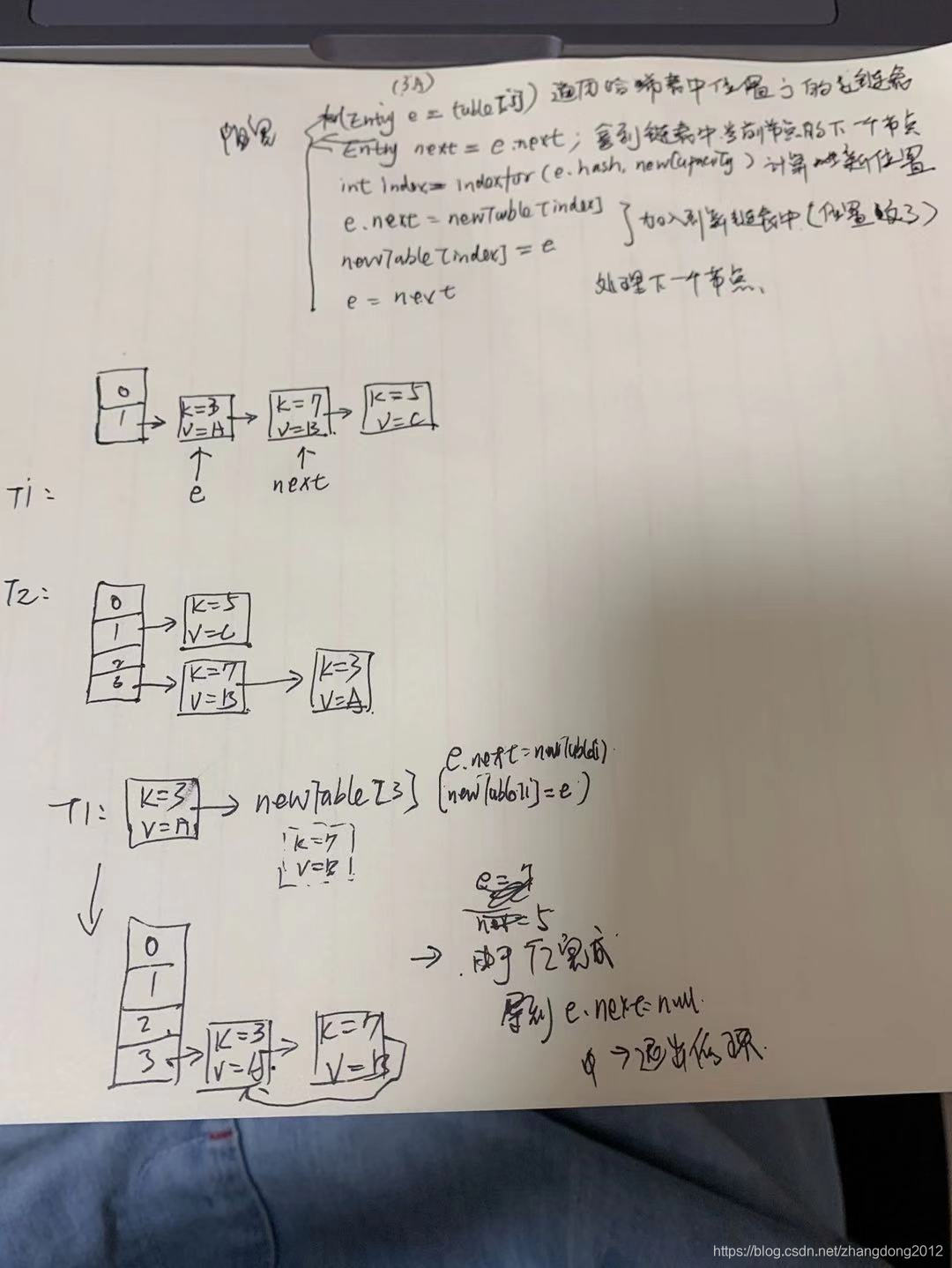
上面的图是出现循环链表的完整过程,我大概描述一下。
假设有两个线程T1和T2,T1线程在处理库容时,由于某种原因阻塞在了Entry next = e.next;这一步的前面,然后T2开始执行扩容逻辑,并完成了扩容操作
那么,按照上面图里画的,newTable[3] = [k=7,v=B].next = [k=3,v=A];,此时,T1线程中e=[k=3,v=A],并且T1被唤醒,由于T2线程已经处理完扩容逻辑,所以,此时[k=3,v=A].next 等于 null,然后接着执行
//根据扩容后哈希表的容量计算索引
int idx = indexFor(e.hash, newCapacity);
//将节点e添加到新的哈希表中,顺序与原来相反
e.next = newTable[idx];
newTable[idx] = e;
这几步执行完后,循环链表就产生了,由于T2线程的处理,使得k=7.next = k=3,newTable[3] = [k=7],又因为T1的捣乱,导致了newTable[3] = [k=3].next = [k=7],所以,[k=3].next = [k=7] (T1),[k=7].next = [k=3] (T2),紧接着,由于在T1中拿到的next=null,所以T1运行结束,当调用get时就死循环了。
对mybatis架构的理解
mybatis是目前最流程的dao层框架,主要用来解决传统jdbc的代码冗余问题,在传统的jdbc中,包含了数据库连接管理、sql装配、参数设置、sql执行、处理结果集、释放数据库连接等步骤,这些步骤都数据模板式的,mybatis的主要作用就是让程序员更加专注于sql,而不是在模板代码上浪费宝贵时间。
理解mybatis的架构,可以从三个角度入手,分别是
- 功能架构
- 逻辑架构
- 执行流程
从功能架构上看,mybatis可以分为四层,从上到下分别是调用层、处理层、支撑层和引导层。
调用层提供了客户端使用mybatis的方式,目前有两种,一种是根据statementId进行调用,一种是公共Mapper接口继续调用。
处理层包含了一个sql执行过程中需要的组件,例如BoundSql(MappedStatement/SqlSource),StatementHandler、ParameterHandler、Executor、ResultHandler,这些组件描述了一个sql的执行流程。
支持层主要包含一些基础功支持,例如数据库连接池、事务管理器、缓存等。
引导层主要描述对mybatis行为的配置,配置方式主要包含两种,一种是配置文件的方式,一种是java api的方式。
从逻辑上看,我觉得可以这样理解
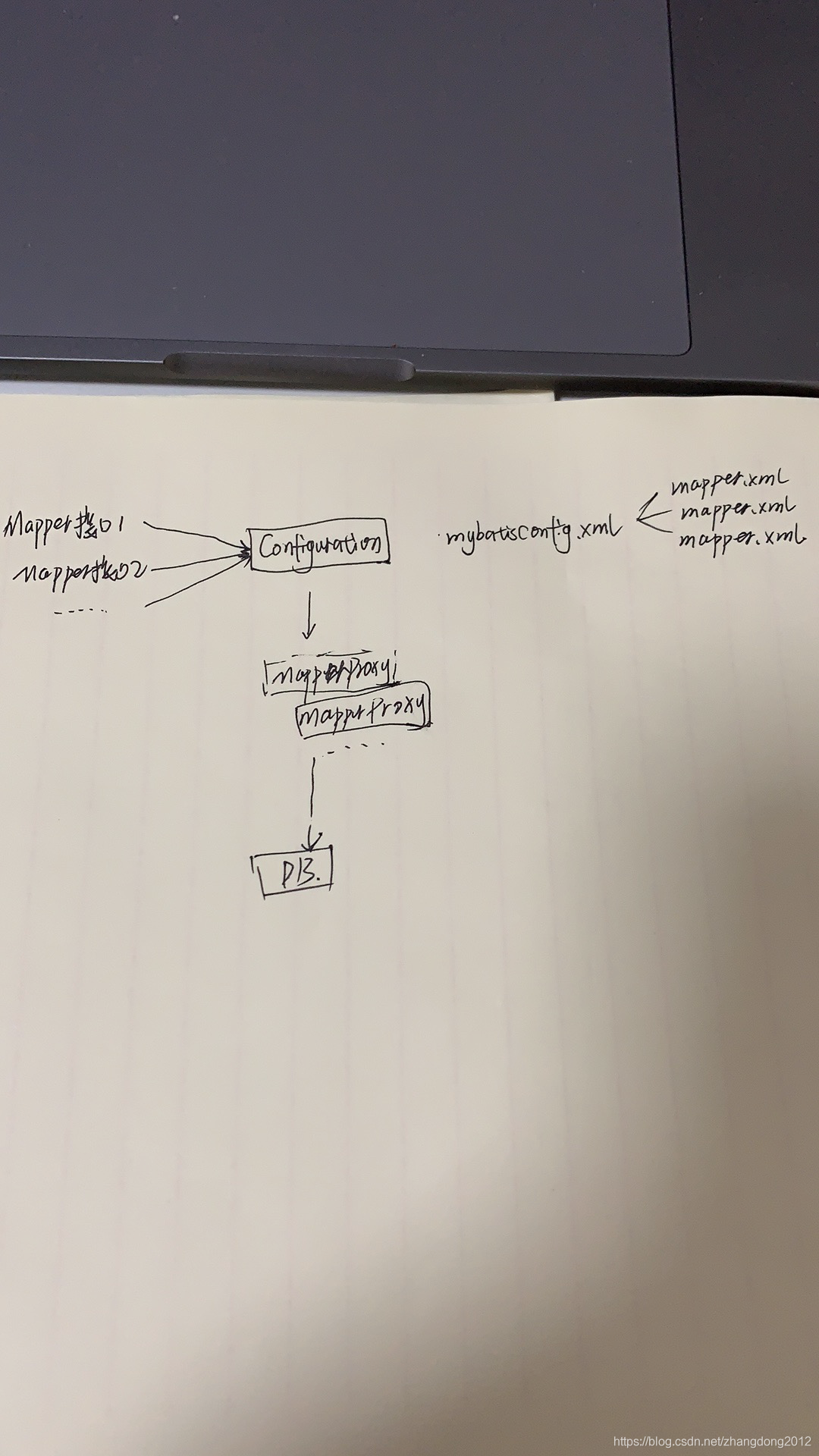
其中,MapperProxy包含了所有执行sql过程中需要的组价。
前面说的都是从宏观的角度来看mybatis,那么从微观角度看,就要深入到它的执行流程当中了。在分析执行流程前,首先要初始化mybatis的运行时环境,所以从微观层面可以分为以下几个部分
- 加载配置、初始化全局Configuration对象
- 构架SqlSessionFactory
- 创建SqlSession
- 通过SqlSession对象提交执行请求
- Executor控制执行的全流程
- StatementHandler通过SqlBound/TypeHandler的帮助构架Statement对象
- 执行sql
- 通过ResultHandler处理结果集
- 返回
然后对每一个步骤再具体分析,看看里面的细节,先来看初始化流程。
初始化流程可以理解为主要包含三个部分,分别是,初始化公共属性及组件、解析mapper.xml中是sql语句,初始化SqlSessionFactory。
初始化公共组件及属性指的是解析mybatis-config.xml核心配置文件(除去对mapper.xml的解析),主要抱哈数据源、事务管理器、类别名配置、类型处理器及mybatis核心参数,这些配置最终都会被解析并初始化到核心配置对象Configuration中。
接下来是mapper.xml的解析,之所以把这一步单独拿出来,是因为这里涉及到的sql语句与具体的执行流程联系紧密,在解析mapper.xml中,没一个sql都会被解析成一个MappedStatement对象,内部包含了各种配置以及一个SqlSource,这个SqlSource就对应了具体的sql语句。
最后,来分析一下在mybatis下一个sql的执行流程。在说mybatis功能架构的时候说过,调用方式有两种,一种是通过namespace+statementId调用,一种是通过Mapper接口调用,实际上通过mapper接口的方式调用最终会转换成namespace+statementId的调用方式,那么,就直接分析通过Mapper接口调用的方式吧。
首先,一切都是从创建SqlSession开始的,SqlSession可以理解为一个数据库连接,但他不只是数据库连接。首先,我们会通过getMapper方法获取一个DaoMapper接口的代理对象,这个代理对象包含了一切,那么这个代理对象时怎么得到的呢? 这个要从初始化说起,在出初始化阶段,mybatis会扫描所有mapper接口,并通过Configuration对象中的MapperRegistry进行注册,内部其实很简单,会初始化一个存放HashMap<Class<?>, MapperProxyFactory<?>>,就是把一个接口和一个MapperProxyFactory进行了绑定
private final Map<Class<?>, MapperProxyFactory<?>> knownMappers = new HashMap();
...
this.knownMappers.put(type, new MapperProxyFactory(type));
这样,再调用getMapper时,就通过,就会执行如下操作
DefaultSqllSession.getMapper()
->this.mapperRegistry.getMapper(type, sqlSession);
MapperRegistry.getMapper()
->MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory)this.knownMappers.get(type);
->mapperProxyFactory.newInstance(sqlSession);
MapperProxyFactory.newInstance()
->MapperProxy<T> mapperProxy = new MapperProxy(sqlSession, this.mapperInterface, this.methodCache);
->Proxy.newProxyInstance(this.mapperInterface.getClassLoader(), new Class[]{this.mapperInterface}, mapperProxy);
这样看来就很清楚了,一切都是Jdk的动态代理在捣鬼。 返回的代理对象的核心逻辑就封装在MapperProxy中。
那么,就看看MapperProxy是个什么东西吧
public class MapperProxy<T> implements InvocationHandler {
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
MapperMethod mapperMethod = this.cachedMapperMethod(method);
return mapperMethod.execute(this.sqlSession, args);
}
这是jdk动态代理的标准写法,就不细说了,紧着往下看MapperMethod
public class MapperMethod {
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
Object param;
switch(this.command.getType()) {
case INSERT:
param = this.method.convertArgsToSqlCommandParam(args);
result = this.rowCountResult(sqlSession.insert(this.command.getName(), param));
break;
case UPDATE:
param = this.method.convertArgsToSqlCommandParam(args);
result = this.rowCountResult(sqlSession.update(this.command.getName(), param));
break;
case DELETE:
param = this.method.convertArgsToSqlCommandParam(args);
result = this.rowCountResult(sqlSession.delete(this.command.getName(), param));
break;
case SELECT:
if (this.method.returnsVoid() && this.method.hasResultHandler()) {
this.executeWithResultHandler(sqlSession, args);
result = null;
} else if (this.method.returnsMany()) {
result = this.executeForMany(sqlSession, args);
} else if (this.method.returnsMap()) {
result = this.executeForMap(sqlSession, args);
} else if (this.method.returnsCursor()) {
result = this.executeForCursor(sqlSession, args);
} else {
param = this.method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(this.command.getName(), param);
if (this.method.returnsOptional() && (result == null || !this.method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
case FLUSH:
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + this.command.getName());
}
if (result == null && this.method.getReturnType().isPrimitive() && !this.method.returnsVoid()) {
throw new BindingException("Mapper method '" + this.command.getName() + " attempted to return null from a method with a primitive return type (" + this.method.getReturnType() + ").");
} else {
return result;
}
}
}
这里就是将对mapper接口的调用转化成statementId调用的现场,下面就进入到了mybatis的最原始api调用中,咱们以DefaultSqlSession.selectList为例来分析原始api的执行流程。
首先,根据statementId从Configuration中获取到MappedStatement
MappedStatement ms = this.configuration.getMappedStatement(statement);
然后就将执行权较给了Executor,进入到Executor.query中。
BoundSql boundSql = ms.getBoundSql(parameter);
CacheKey key = this.createCacheKey(ms, parameter, rowBounds, boundSql);
return this.query(ms, parameter, rowBounds, resultHandler, key, boundSql);
上面的分析中也有说过,MappedStatement中包含了一个代表Sql语句的SqlSource对象,SqlSource通过填充参数后,会返回一个BoundSql,BoundSql就是填充了参数的sql语句。紧接着根据sql语句及参数等获取一个一级缓存对一个的key,一级缓存默认开启,而且不能关闭。
然后,会先判断一级缓存中是否存在需要的数据,如果右,则直接返回缓存中的数据,如果没有,则从数据库中查询,这是我们最关注的地方,下面看看,mybatis是如何从数据库中查询数据的吧
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(this.wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
stmt = this.prepareStatement(handler, ms.getStatementLog());
var9 = handler.query(stmt, resultHandler);
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Connection connection = this.getConnection(statementLog);
Statement stmt = handler.prepare(connection, this.transaction.getTimeout());
handler.parameterize(stmt);
return stmt;
}
从上面的代码可以看出,首先创建了一个用于最终执行sql语句的StatementHandler,然后创建一个代表本地需要执行的sql语句的Statement对象,创建Statement对象时会通过ParameterHandler处理#{}类型的预处理参数,最后,通过StatementHandler的query方法执行sql
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
String sql = this.boundSql.getSql();
statement.execute(sql);
return this.resultSetHandler.handleResultSets(statement);
}
然后,由ResultHandler进行结果集的封装,最终返回结果,好了,mybatis的执行流程就分析完了,下面简单总结一下:
- 在初始化时通过Configuration.MapperRegistry注册Mapper接口和与其对应的MapperProxyFactory
- 调用SqlSession.getMapper时,实际底层会调用MapperProxyFactory.newInstance返回一个有MapperProxy增强的Mapper接口代理对象
- MapperProxy是一个实现了InvocationHandler的类,遵循了Jdk 动态代理规范,其内部封装了将对Mapper接口的调用转换成mybatis原生api的调用,即通过statementId调用
- 然后,首先通过statementId获取待执行sql对应的MappedStatement(初始化时创建的)
- 紧接着,从MappedStatement对象中导出BoundSql对象
- 根据sql即参数创建在一级缓存中会用到的cache key
- 如果一级缓存中存在结果,则直接返回,如果不存在则查询数据库
- 从数据库查询时,首先会创建一个StatementHandler,在StatementHandler内部包含了ParameterHandler和ResultHandler
- 创建Statement对象,利用ParameterHandler对参数进行赋值
- 调用Statement对象执行sql
- 利用ResultHandler封装结果集,最终返回
mybatis的插件机制
mybatis的插件机制实际上也是通过jdk动态代理实现的,在实现自定义插件时,我们会在plugin方法中通过Plugin.wrap方法对目标对象进行动态代理的包装。那么这个人plugin方法时在哪调用的呢,其实是在创建Executor的时候,所有的Interceptor会被封装到一个InterceptorChain中,然后再创建Executor时,循环遍历所有的Interceptor,并调用其plugin方法,进行层层包装。
如何理解spring mvc
spring mvc是一个基于mvc模式的web框架,比较轻量级,同时还能与spring无缝整合,目前已经是java领域最流程的mvc框架。
spring mvc的核心执行流程
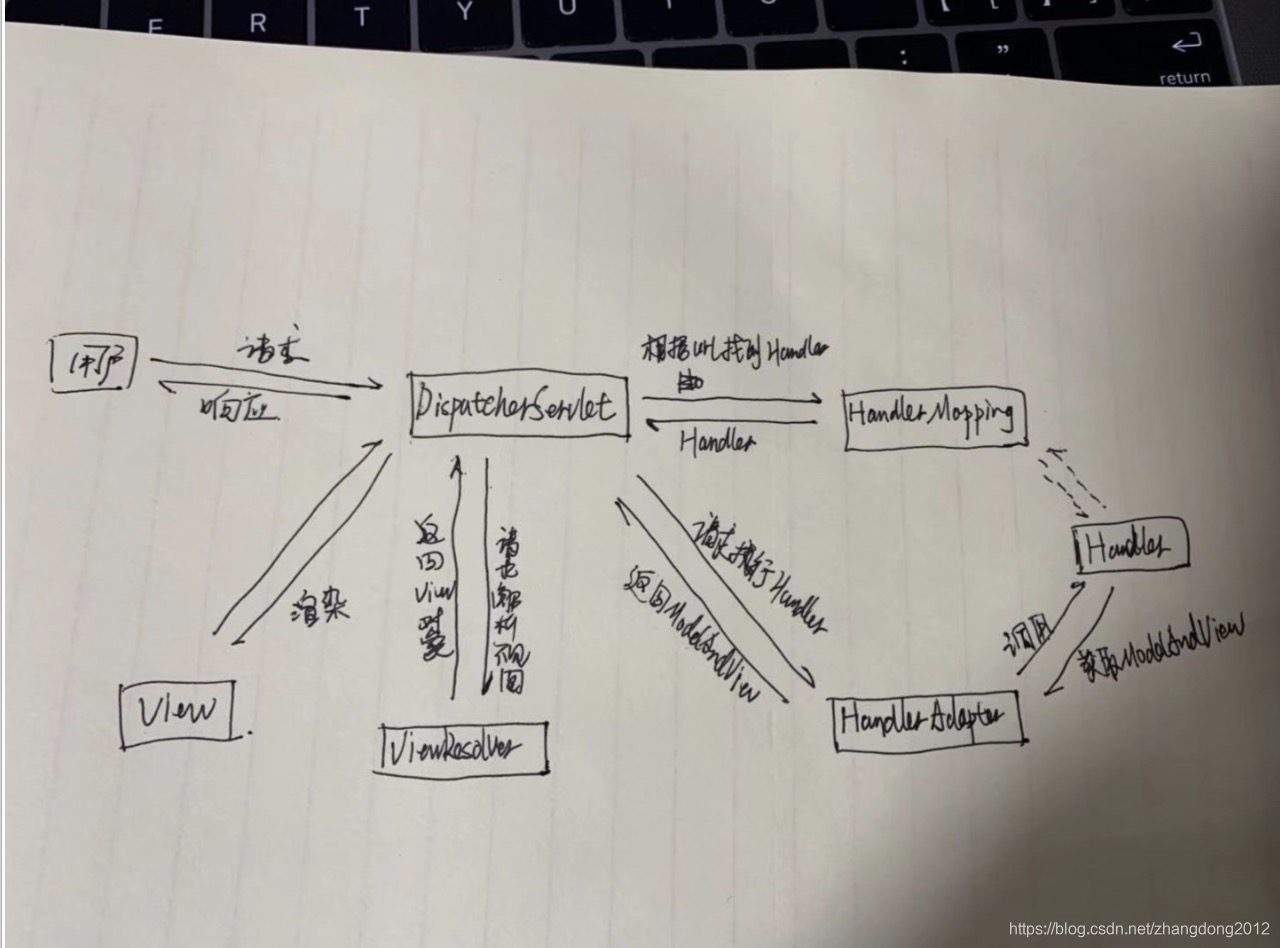
- 首先,请求会经过DispatcherServlet,因为在DispatcherServlet中定义了整个请求的处理流程
- 紧接着,DispatcherServlet就会根据当前请求对应的url从HandlerMapping中找到对应的Handler处理器,在HandlerMapping中定义了每个url对应的Handler
- DispatcherServlet拿到Handler以后,通过HandlerAdapter进行适配,并执行具体的Handler来处理请求,最终返回ModelAndView对象
- DispatcherServlet将ModelAndView交给ViewResolver进行解析并得到View对象
- 最终根据View对象来渲染待返回的数据
- 最终,将渲染后的结果返回给客户端
理解一个框架,我个人的习惯是从宏观和微观两个方面入手,首先弄清楚这个框架是做什么的,与其他框架相比有什么优势,解决了什么问题,然后弄清楚整个框架的整体结构。 然后再去了解他的初始化过程,最后,再深入的细节去了解他的处理流程。所以,对于spring mvc来说,我们也可以从这几个方面再来回顾一下。
MVC设计模式个人理解时目前绝大多数应用程序遵守的规范,它本质上是一种分层设计思想,可以对应到六大设计原则中的单一职责原则。那spring mvc作为一个web层框架,它基于mvc设计模式将web应用程序分成了三层,分别是Model层,View视图层和Controller控制器层,所以说,spring mvc是一个基于mvc实现模式的web层框架。
另外,spring mvc还有诸多优点,例如轻量级、与spring 无缝整合,同时也继承了spring 优秀的基因,高可扩展。从前辈(哈哈)那里听说早期比较流程struts即struts2,但我自己并没有在真实项目中接触过,因为开始参加工作那会,struts已经被spring mvc打入地狱了,但据说struts是一种很重的web框架,虽然他也基于mvc模式设计。另外spring mvc作为spring全家桶中的一个鸡翅,配合其他东西一起吃会更好吃。
下面我们就把spring mvc作为一个独立框架,来看一下它的初始化过程。
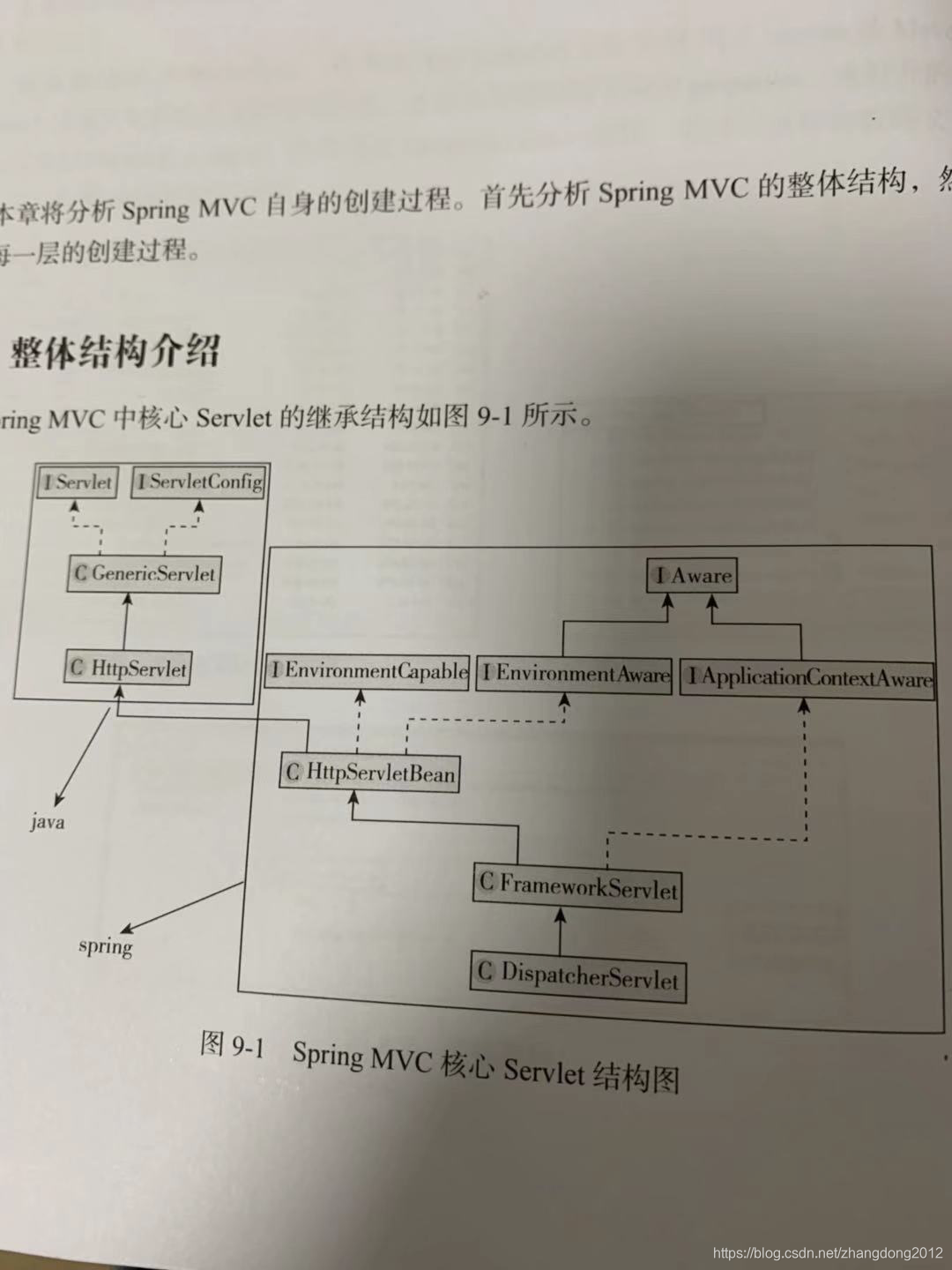
从上面的图里可以看到,HttpServletBean是连结Servlet容器的桥梁,所以spring mvc的整个初始化流程开始于HttpServletBean的init方法,这个init方法来源于Servlet规范。
HttpServletBean
public final void init() throws ServletException {
this.initServletBean();
}
FrameworkServlet
protected final void initServletBean() throws ServletException {
//初始化ApplicationContext上下文
this.webApplicationContext = this.initWebApplicationContext();
//子类钩子方法,
this.initFrameworkServlet();
}
protected WebApplicationContext initWebApplicationContext() {
//初始化ApplicationContext上下文
wac = this.createWebApplicationContext(rootContext);
//开始初始化spring mvc中的各种组件
this.onRefresh(wac);
}
protected WebApplicationContext createWebApplicationContext(@Nullable ApplicationContext parent) {
ConfigurableWebApplicationContext wac = (ConfigurableWebApplicationContext)BeanUtils.instantiateClass(contextClass);
}
protected void onRefresh(ApplicationContext context) {
this.initStrategies(context);
}
protected void initStrategies(ApplicationContext context) {
this.initMultipartResolver(context);
this.initLocaleResolver(context);
this.initThemeResolver(context);
this.initHandlerMappings(context);
this.initHandlerAdapters(context);
this.initHandlerExceptionResolvers(context);
this.initRequestToViewNameTranslator(context);
this.initViewResolvers(context);
this.initFlashMapManager(context);
}
从上面的代码中可以看到spring mvc的初始化流程非常清晰,总结起来分成两步,一是创建web spring上下文,二是初始化各个组件,这些组件包含了
- 处理文件上传的MultipartResulver
- 处理国际化的LocaleResolver
- 根据url获取Handler的HandlerMapping
- 调用Handler处理请求的HandlerAdapter
- 处理异常的HandlerExceptionResolver
- 处理视图的ViewResolver
说说对架构演进及分布式RPC框架的理解
在互联网发展初期或一些简单场景下,服务的功能比较单一,而且流量也比较小,这种情况下,就适合采用All-In-One的单体架构设计,可以对需求做出快速的响应他,同时部署效率更高。
但是随着互联网的发展及公司业务的发展,功能越来越多,逻辑越来越复杂,此时如果再采用单体架构,就会代理一系列的问题,例如会出现大量的重复代码、不利于多人协作、耦合度过大 牵一发动全身,部署效率大大降低等。这个时候,就要考虑对服务进行拆分。
拆分服务按照不同的场景可以从横向和纵向两个维度进行,一般情况下,如果业务的界限比较清晰,就可以纵向拆分,如果业务在功能上的交叉比较多,就横向拆分。纵向拆分时,一般一个子系统就是一个独立的,不需要与其他系统进行交互的子模块,相对比较简单,但横向拆分时,需要按照功能进行服务化改造,因为服务与服务之间存在相互依赖,不同的功能经过组合后才能构成业务能力。
横向拆分,一般利用rpc框架完成,通过rpc框架可以实现服务之间的跨进行调用,实现服务的独立部署、独立维护、独立扩展,很好的将各个模块进行了解耦合,此时,就引出了另外一种架构模式 SOA架构。
个人理解,SOA架构主要包含两个部分,一个是RPC远程调用,另外就是服务治理。当服务数量增多时,对服务的监控、动态配置、服务注册与发现、服务的安全性会称为比较棘手的问题,在开源rpc框架中,最流行的要属Dubbo了。dubbo提供了相对比较完善的分布式rpc框架应该具备的能力。
架构模式再往后发展,就来到了微服务架构,个人理解微服务架构产生的背景是DevOps、Docker以及敏捷开发的流行。与SOA架构相比,微服务架构中服务拆分的粒度更细,开发和部署效率更高,能够很好的配置DevOps/Docker部署和敏捷开发流程。
下面在说说对RPC框架的理解。
RPC框架是服务化改造的必备武器,是SOA架构模式的基础,流行的开源RPC框架有很多,例如facebook 的Apache Thrift,google的grpc等,这些框架都提供了最基础的rpc支持,但是,前面也提到了,服务化带来好处的同时,也带来了新的待解决的问题,例如,服务注册于发现,服务监控,负载均衡、集群容错等功能,对于这些功能,上面的rpc框架是不具备的,所以,dubbo就出现了,dubbo应该是开源rpc框架中功能比较完善的了,它包含了服务注册中心,监控中心,集群容错,负载均衡等核心功能,为SOA架构提供了基础。
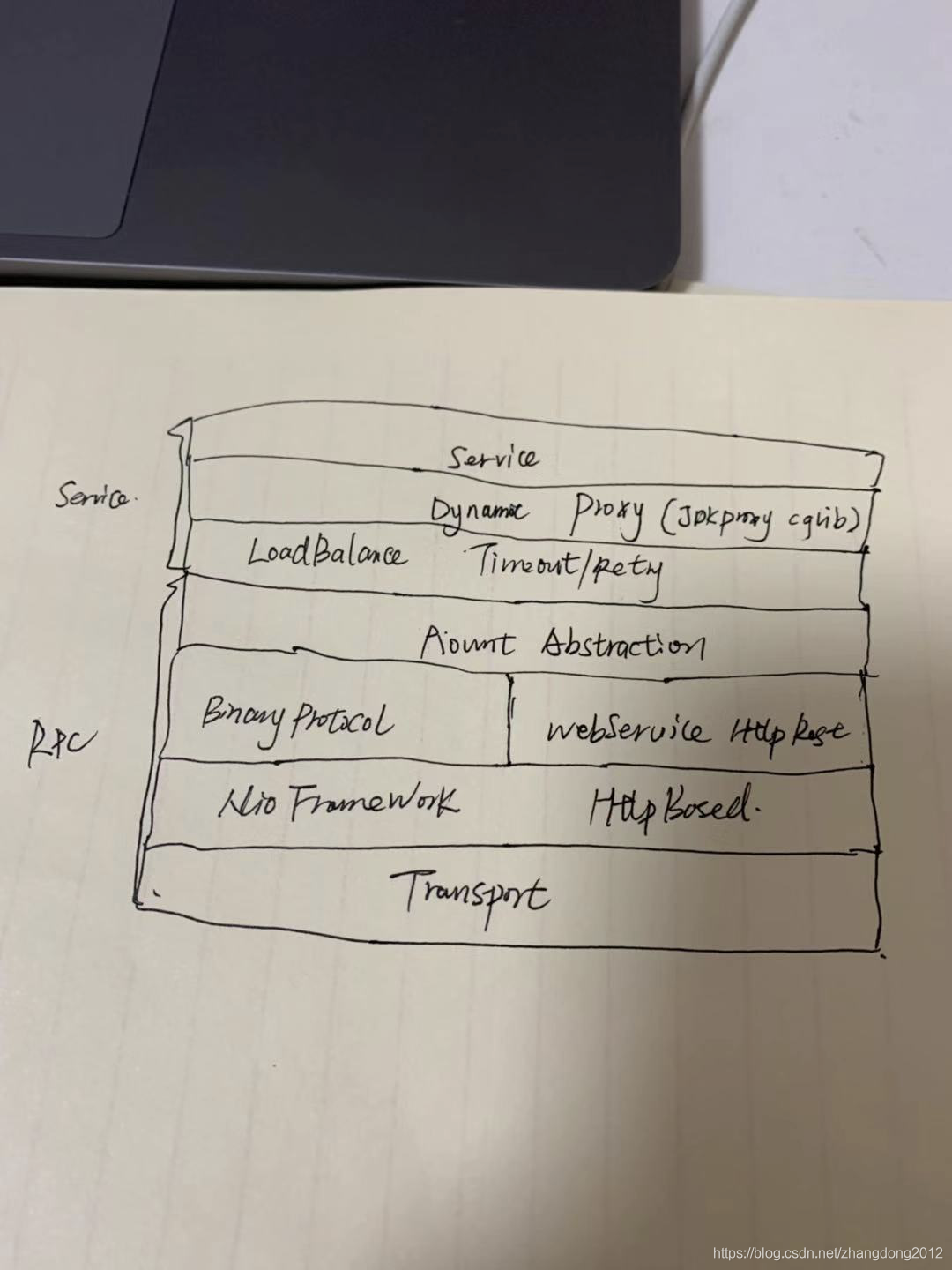
把dubbo认为是一种rpc框架是对的,但是如果认为rpc框架就是dubbo,那就大错特错了,dubbo不仅仅是rpc框架,dubbo实际上是一个分布式服务框架,下面我们来聊一聊一个分布式框架的架构组成。
从dubbo来看,一个分布式服务框架主要包含两个部分,一部分是服务层,一部分是RPC层,服务层复杂将java api调用转换成rpc调用,并附带负载均衡,集群容错,超时重试等高级功能,rpc层负责处理底层的通信细节,包括协议编码、序列化及网络传输等等。
半包&粘包问题
半包和粘包问题主要是由TCP协议的特性决定的,首先在TCP链接中,本身并没有数据包的概念,只有数据流,之所以存在数据包,完全是因为为了提高数据的传输效率,也就是我们常说的批量处理,另外一个原因就是,在此基础上,TCP层并没有定义包的含义,在接收和发送包时,并不清楚这个数据包所代表的具体意义。
半包和粘包的本质是发送方和接收方的步调不一致导致的,例如发送方要向接收方发送两个数据包D1和D2,如果D1和D2都比较小,被放到了一个TCP数据包中,这两个就数据包就粘连在了一起,这就是粘包,如果D1比较大二D2比较小,那么D1的一部分被翻到了一个TCP数据包中,剩余部分和D2被放到了另一个单独的数据包中,D1就出现了半包问题,因为在第一个包中并没有包含完整的D1数据。
那么如何解决半包和粘包问题呢,有下面几种办法
- 将每一个数据包固定大小,超出大小的不予发送、不足的特殊字符补齐
- 按特殊字符分隔,两个特殊字符之间就是一个完整的包
- 将数据分为头和体两部分,头中包含数据的长度
在netty中内置了几种常见的处理半包&粘包问题的Handler
- FixedLengthFrameDecoder 基于固定长度进行拆包
- DelimiterBasedFrameDecoder 基于消息边界进行拆包
- LengthFieldBasedFrameDecoder 基于消息头指定消息长度的方式进行拆包
- LineBasedFrameDecoder 基于行来进行拆包
目前,市面上很多流行的分布式框架底层都是基于netty进行通信的,所以,理解这些问题对于理解netty及其他框架都有很大帮助。
对java io的简单总结
1995年,sun发布了第一版java,从那以后,凭借着面向对象和跨平台特性,java开始流行起来,渐渐地,java生态越来越丰富,出现了无数优秀的基于java的类库,这又促使java更快的发展。
但对着技术与互联网的发展,java的一个核心功能模块开始被人诟病,这就是java io,最初,java只有阻塞式io,这在一般的读写文件场景及低流量的网络环境下确实可以很好的工作,但是高并发程序随着社会的发展需求越来越强烈,如何用java构建高性能网络应用成为了天方夜谭,那时,几乎所有的高性能服务端应用都被c或c++占据,直到2002年jdk1.4正式推出了NIO才打破了这张局面。
说到io首先要了解一下操作系统的io模型以及几种不同的io模式。虽然说操作系统也应用服务都是软件,但所处的位置不同,操作系统是由底层硬件直接承载,而应用软件则是运行在操作系统上,之所以这么做,是因为应用软件要借助操作系统提供的高级api简化自身的开发难度,试想,让你写一下直接运行在硬件上的软件,是不是难于上青天?
对于io操作来说,也要区分这两层。操作系统级别的操作被称为内核层,直接操作硬件,应用服务层被称为用户层,只与操作系统打交道,在进行io操作时,例如我们要从磁盘读取数据到内存,实际上是应用服务向操作系统发送了一个读指令,操作系统将数据读取到内核层缓冲区,然后再通知用户层从内核层读取数据。
在操作系统层面,提供了阻塞io、非阻塞io、多路复用io,信号驱动io和异步io这几种io模式。所以作为用户层应用的java,就受制于此。期初,java io是基于阻塞io实现的,阻塞io从用户层服务发起调用到完成数据读取之间的所有操作都是同步阻塞的,后来jdk1.4引入了非阻塞io,java nio的实现,期初基于非阻塞io,也就是select/poll模型,实现了单个线程能管理多个channel的目的,底层基于轮训实现,后来java 对nio实现进行了优化,引入了信号驱动模式io,也就是epoll,当内核层准备好数据,会以信号的方式通用户层线程读取数据,可见,epoll的效率会明显高于select/poll,紧接着在jdk1.7进入了异步io,也即是我们所说的aio以及异步文件io。
NIO目前多数情况被使用在网络编程中,用来开发高性能服务器。在bio模式下,通常的做法是一个链接对应一个线程,但是当连接数很大时,一方面会造成服务端线程数暴增,系统资源被占满,另一方面在此基础上又会使处理效率进一步恶化,随着互联网的发展,很多服务的用户量都比较大,bio已经不能胜任,但是bio也不是一无是处,相比于nio,bio的api及编程模型对开发人员更友好,在日常编写文件读写等io操作是,还是会大量的使用bio。
java bio模型中,把io按照流向分成了输入流和输出流,按照处理数据的类型分成了字节流和字符流,核心的API包括InputStream、OutputStream,Reader、Writer以及用户字节流和字符流转换的InputStreamReader和OutputStreamWrite,另外还有用于进行对象序列化的ObjectInputStream和ObjectInputStream等等。
java nio的编程模型与bio完全不一样,它将输入输出流进行了合并,抽象成channel的概念,channel技能读也能写,但读写的数据源是ByteBuffer,ByteBuffer是一个数据的载体,通常nio的编程范式是首先创建ByteBuffer,然后将输入写入,调用flip对读写指针进行复位,channel.write(buffer)将数据写出去,在channel的另一面,创建一个ByteBuffer,利用channel.read(buffer)将数据读入ByteBuffer中。
如何理解Reactor线程模型
简单说说Netty的原理
理解高并发的两把利器:零拷贝和epoll
参考文章:https://mp.weixin.qq.com/s/q_0IbLRgnxvzG-fnRBENmA
理解零拷贝首先要理解用户空间和内核空间以及用户缓冲区和内核缓冲区,在传统的io模型中,一次io操作,首先是由操作系统内核将数据从磁盘或网卡读取到内核缓冲区,然后再从内核缓冲区拷贝到用户缓冲区,每次拷贝都需要cpu参与,虽然说通过DMA技术可以减少避免cpu参与从磁盘或网卡拷贝数据到内核缓冲区这个步骤,但从内核缓冲区到用户缓冲区这一步是不可避免的,读取一个大文件时,往往需要很多次拷贝,这就严重影响了性能,随着硬件和软件技术的发展,后来引入了零拷贝技术,从概念上理解,零拷贝指的是减少或避免数据在内核空间到用户空间以及内核到内核的拷贝次数,常见的零拷贝方案也比较多,比如
- 用户态直接IO
- mmap+write
- sendfile
- sendfile + gather DMA(gather DMA需要硬件支持)
- splice(不需要硬件支持)
这些方案的最终目标都是减少或避免数据来来回回拷贝的次数,业界一些流程的框架以及java在io模块中也大量运用了这些技术来提高io性能,例如java nio,kafka,netty,nginx等等。
epoll我给人立即是一种io事件驱动模型,我们在谈论io的时候,经常会把io分为阻塞io,非阻塞io,多路复用io和异步io,而这里的epoll是多路复用io,参考nio中的select及SelectionKey更容易理解,io多路复用的思路简单理解就是用一个线程去监听多个线程的io状态,避免一个io对应一个线程,避免线程数量爆炸,那讲到epoll首先要了解他的前身,select/poll,这种
机制是基于轮询的,对应的java nio上,也就是说调用一次select,我会知道监听的众多io中有新的io时间发生了,但是我并不知道具体是哪个io通道,再换个角度,用算法的思路看,这个操作的时间复杂度时O(n),而epoll则完全解决了这个问题,它不仅会通知到用户线程有io事件发生了,同时还会告知具体是哪个channel,这样select的时间复杂度就变成了O(1)。
所以我个人任务,零拷贝和epoll机制是解决高并发的两把利器,他们从操作系统内核层面为用户层提供了高并发支持。
对zookeeper的理解
zookeeper是一个分布式服务,它主要用来做配置服务、命名服务、分布式同步以及组服务,zookeeper可以说是很多分布式框架的基础服务,例如我们比较熟悉的dubbo、hadoop等等。zookeeper本质是是一个存储服务,它提供了数据的读写功能。
那么,作为一个分布式存储服务,zookeeper提供了一致性读和一致性写的特性,一致性读指的是从客户端的视角看,所有节点的数据都是一样的,这依赖于一致性写,而理解一致性写,我觉得可以从以下几个角度看,分别是原子性、顺序一致性和最终一致性,怎么理解呢,原子性指的是一个写请求,要么在所有节点都成功要么都失败,顺序一致性指的是数据的变化顺序严格与写请求顺序一致,最终一致性指的是一个写请求会经过短暂的消息传递,到到集群中的所有节点,这期间会出现节点数据短暂的不一致,那么,前面说的读一致性依赖于写一致性是怎么回事的,其实是如果一个事务没有在所有节点写成功,也就是一个原子性操作没有完成,就不会对读请求可见,很多资料说zookeeper是CP系统,及保证了一致性和分区容错性,但是我觉得它是一个cap系统,只不过相对严格的a来说这里的a稍弱一些。
zookeeper的一致性算法采用paxos算法,一般,实现数据一致性的方式有两种,分别是共享内存和消息传递,而paxos算法是基于消息传递实现的,提到paxos算法就不得不提拜占庭将军问题,拜占庭将军问题放到IT系统中可以理解为,在一个不可靠信道上,想通过消息传递的方式实现一致性是不可能的,因为有可能出现消息丢失或消息被篡改的问题,所以说paxos算法的前提是不存在拜占庭将军问题。
下面描述一下poxos算法的逻辑过程。
在paxos算法中,有三种角色,分别是Proposer、Acceptor和Leaner,其中Proposer是提案的发起者,Acceptor是提案的决策者,Leaner是数据的同步者,那么这三个角色之间是什么关系呢?首先,需要明确的是,多个决策者打成一直的过程会被分为两个阶段,分别是prepare阶段和accept阶段,在prepare阶段,proposer会向所有的acceptor发送一个包含了唯一编号N的探测消息,acceptor接收到后,会拿着这个N和自己本地曾经accept过的最大编号进行比较,如果N>maxN,则认为可以接收,如果小于则说明这个提案已经过时了,就会返回proposer一个错误获取不返回,那么,只有当半数以上的acceptor给proposer反馈了,才说明这个提案是可以被执行的,这时候,就进入到了accept阶段,这个阶段首先proposer会把自己的编号N和具体的提案(可以理解成写请求)一起发送给acceptor,这个时候acceptor会再次确认这个编号N的正确性,如果正确,则给proposer返回ack,当超过半数的acceptor给proposer返回时,说明这个提案可以落地了,但是,此时会出现两种情况,一种是所有的acceptor都给proposer反馈了,一种是一部分有反馈而一部分没有,那么,针对这两种情况,proposer会做不同的处理,对于给与了反馈的acceptor,proposer会向其发送一个commit消息,acceptor收到后,会真正的执行这个提案。对于没有返回的acceptor,proposer会发送comimit+提案,意思就是不容反驳直接执行就可以了。
paxos算法虽然逻辑上看起来不是很复杂,但是在工程实现上是公认的比较复杂的算法,目前这种算法的实现比较常见的比如Fast Paxos和EPaxos等。另外有一个问题还需要注意,Paxos算法本身在工程实现上会碰到一个比较致命的问题,就是活锁问题,活锁问题产生的主要原因是在paxos算法中所有的节点都可以进行提案,在这种情况下,由于某种原因,导致某个节点的提案一直被否决,此时在paxos算法中,这个节点就会不断的增加自己的提案编号任何重复prepare和accept,这就导致了活锁问题,锁在工程实现上,比如在FastPaxos中,它就通过只允许一个节点进行提案来避免这种问题。
在zookeeper中的一致性算法叫做ZAB,也被叫做ZAB协议,zab协议据说是基于FastPaxos算法实现的。在zab协议中有三种角色,分别是Leader、Follower和Observer,Leader负责事务请求的处理,Follower负责处理读请求以及从Leader同步数据,同时有权利参与Leader选举,Observer负责从leader同步数据和读请求,但是不能参与leader选举,observer节点一般被用来提高集群的读请求,同时要不影响事务请求处理的性能。
我个人理解zookeeper主要是从两个方面入手,一个是leader选举,一个是事务请求的处理,下面从这两个方面简单说一说。
对于leader选举的理解,主要分成两个场景,一个是初始集群的leader选举,一个是leader崩溃时的leader选举。初始集群进行leader选举时,第一个台机器启动时,它会进入到looking状态,此时不能对外提供服务,当第二台启动后,他们会比较发送投票消息,以第一台为例,它会向2发送(myid,xxid)然后2收到消息后,首先会比较zxid,事务id大的胜出,如果事务id相同则比较myid,myid大的胜出,这样最终就算出了2位leader,然后切换自身的状态,2由looking变为leading,1由looking状态变为following状态,集群开始能够对外提供服务当再有新节点加入时,就会直接将状态设置为following。对于leader崩溃时的leader选举,唯一的区别在于,所有follower的状态会从following变换成looking,然后进行leader选举。
在崩溃恢复场景下的leader选举有两个问题需要注意一下,首先是在leader崩溃前已经被部分follower同步的数据不能丢,另外一个问题是leader在崩溃前接收到的但是没有被任务follower同步的数据不能出现在新leader领导的集群中。第一种情况比较好理解,follower在选举leader时由于会选择zxid比较到的节点,所以leader一定会从那些已经同步了老leader数据的节点中产生,第二种情况是说存储了还没有来得及同步的数据的leader又活过来了并且加入到新leader领导的集群中,那么此时,会比较epoch,由于每个leader对应的epoch都不同,所以前一个leader中的未同步的数据最终会被删除掉。
对于事务请求的处理,就比较好理解了,在zookeeper节点中,follower和observer都不能处理写请求,当这些节点接收到写请求后,会把请求转发到leader,让leader处理,leader在处理写请求时,会严格按照请求的顺序进行处理,以包装数据的一致性,leader再向follower同步的过程中,最新的数据是对外不可见的,只有当follower同步完成后才对外可见,这也保证了对外数据视图的一致。
对mysql的一些总结&思考
https://dev.mysql.com/doc/refman/8.0/en/apache.html mysql官方文档
mysql作为关系型数据库是我们日常开发中最经常用到的数据,由于它基于行和列的结构以及对事务的支持,能够很好的支撑复杂的业务场景。
与之相对应的nosql数据库目前也非常流行,例如redis、mongodb等等。相比于mysql,nosql数据库在性能和扩展性方面更占优优势。
由于nosql数据库基于key-value构建,所有操作只涉及到对key和value的操作,没有类似mysql的解析、分析等步骤,执行过程简单高效,另外nosql对value的结构没有明显的规定,用户可以根据业务需要扩展。
在了解mysql的时候可以从以下几个层面进行
- sql语句
- mysql的架构
- sql在mysql的执行过程
- 存储引擎
- 索引
- 事务
- 日志
- 慢查询
- 查询优化
- 分库分表
作为业务开发人员,如果对以上几个方面能够较为深入的理解和掌握,就能完全满足日常的开发需要了,那我们就从这几个方面稍微展开讨论一下吧。
sql语句是上个世纪70年代由IBM提出的一种数据查询规范并运用在了自家的数据库系统System R上,1986年被美国标准化组织定为关系型数据库的标准语言,后来也被国际标准化组织采纳,目前国际最通用的是SQL92标准,但各家RDB厂商对SQL92进行了不同程度的扩展,例如mysql、oracle、hive(遵循了sql标准但hive并不是rdb,而是大数据场景下的数据仓库工具)、postgresql等。
我们日常用到是sql按照不同的功能分类客户分为DML/DDL/DQL/DCL这四类。
- DDL(Data Definition Language)是数据定义语言(
create table/view/index) - DML(Data Manipulation Language)是数据操作语言(
insert/update/delete/call) - DCL(Data Control Language)数据控制语言,主要包含一些用于配置数据操作权限控制的语句,典型的比如mysql中的
grant - DQL(Data Query Language)是数据查询语言(
select)
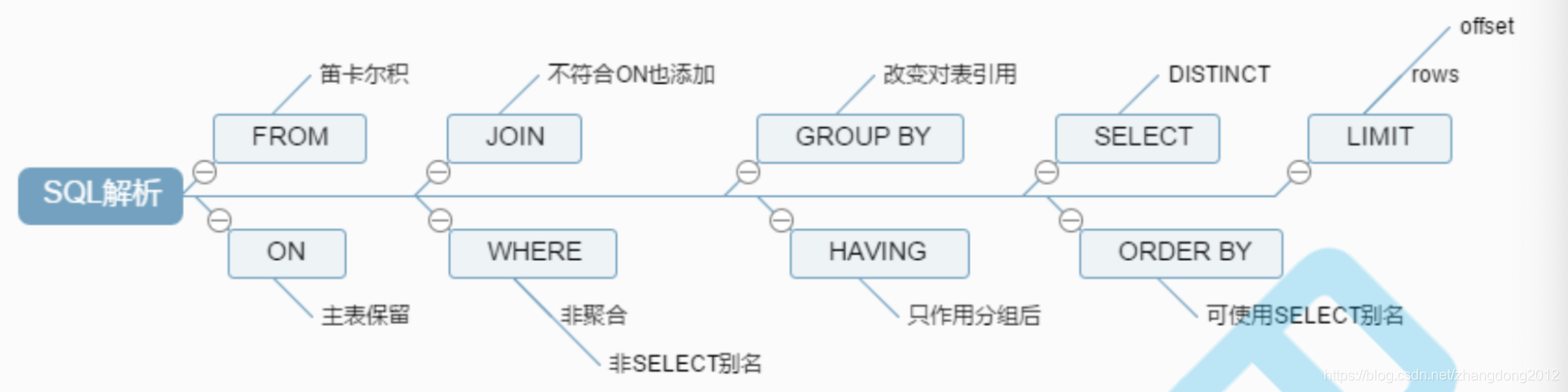
DQL 也就是select是我们最常用的,所以有必要了解一下select语句的执行顺序。在一个select语句中,通常会包含select/distinct/from/join on/where/group by/having/order by/limit,其实,再具体执行的时候,是有一定的顺序的,这个顺序如下:
from -> join on -> where -> group by -> having -> select -> distinct -> distinct -> limit
了解一款软件或框架最好的办法就是先从上帝视角看看它的骨架,然后从中区分出重要的部分深入了解,这样可以避免一头扎进细节的海洋里最后窒息而死。MySql的骨架就是它的架构,主要可以分为以下几个模块
- 链接管理器
- 查询缓存
- 解析器
- 优化器
- 存储引擎
链接管理器负责管理与客户端的tcp链接以及权限控制,客户端连接过来的时候首先接待它的就是链接管理器,tcp两个三次握手链接成功后连接管理器会查询权限控制相关数据,如果当前链接没有对应的权限则会断开连接,例如ip白名单,另外在进行数据操作的时候链接管理器也会事先判断当前链接以及对应的用户是否具有对应的操作权限,如果没有则会返回访问权限错误。
查询缓存的作用是对对数据进行缓存,减少底层的磁盘io,如果一次查询的数据存在于缓存中,那么就会直接返回数据,但是一般情况下不会开启查询缓存,因为一旦对某个表有修改操作,就会导致该表下的所有查询缓存失效,导致了MySql的查询缓存比较脆弱,命中率比较低。查询缓存一般对一些热点的字典类型数据比较有效。不过,在最新版本的MySql中,查询缓存以及被移除了,因为多数时候并不会用到。
解析器的主要作用就是解析SQL语句,使得MySql能读懂用户的指令。
优化器是在MySql读懂了用户要干什么之后做进一步优化,例如查询数据时使用哪个索引效率最高,join连接查询时如何规划查询顺序来优化查询性能等。
存储引擎是真正存储数据和执行sql语句的地方。MySql中的存储引擎是插拔式的,最常用的两种存储引擎是InnoDB和MyIsam,一个数据库中的不同的表可以指定不同的存储引擎。
以InnoDB和MyIsam为例来分析一下这两个存储引擎的异同:
- MyIsam不支持事务,不支持行级别锁,InnoDB支持事务
- MyIsam会在磁盘上保存一个表的总行树,InnoDB不会
- 在drop table时,MyIsam是重建表,InnoDB是一行一行删除
下面说说索引,啥是索引,我理解索引是一种用来加快数据检索速度的数据结构。既然是用来提高查询效率的数据结构,那么我们可以简单聊一聊有哪些数据结构可以用来加速检索速度以及为什么MySql为什么最终选择了B+Tree作为索引数据结构。
简单想一下,我们其实能想起很多,例如最初的Binary Search Tree、以及改进的AVL Tree、红黑Tree、B Tree、B+Tree、Hash Table等,在最初学习数据结构的时候,各种资料都告诉我们,他们可以加快查询速度,那么在实现MySql索引时,我们就需要考虑有哪些需求点以哪些数据结构能够最好的满足
- 数据量大
- 快速检索
- 范围查询
- 对排序友好
再用这四个需求点对比各种数据结构
- BST最大的弊端是无法避免其退化成链表,在有1000W个节点的链表上加锁数据,估计要等到天荒地老了
- AVL-Tree/红黑Tree虽然引入了自平衡机制,但是存在两个比较大的问题,第一,一次插入可能引起大量节点需要调整以包装平衡性,第二,在大数据量下,这两种Tree的高度是不可控的,因为在底层,没查询一个节点就对应着一次磁盘IO,而磁盘IO又是非常慢的操作,这就导致了数据量越大IO次数越多,查询时间完全不可控
- Hash Table虽然能够保证在O(1)的情况下完成检索,但是,由于底层基于hash code,所以对于范围查询以及排序都非常不友好
- B Tree与前集中数据结构相比,它是一个多叉树,理论上数据高度相对可控,但在大数据量下,树的高度仍然会失控,因为在B Tree的每个节点上都存储了具体的行数据,这就导致了一个节点存储的数据量减少,高度增加,IO次数变多,最终查询变慢。
- 而B+Tree与B Tree相比,只在叶子节点存储数据,这样,可以保证非叶子节点能够存储相对多的主键,保证高度可用,另外具有天然的顺序性,很适合排序和查询
综上所诉,MySql最终采用了B+Tree作为数据存存储结构和索引结构。其实,mysql在存储数据的时候也是采用B+Tree,一个表的数据会被组织成一个B+Tree结构,表主键作为节点值,如果建表时没有指定主键,mysql会自动生成一个唯一值来表示,这种存储了具体数据的B+Tree被称为主键索引或聚簇索引,我们单独建立的索引被称为非聚簇索引或二级索引,这些索引的节点值为具体的索引字段,在叶节点存储了对应的主键值,所以,当我们利用二级索引查询数据时,首先到这个二级索引对应的索引树中找到对应行数据的主键,然后再拿着这个主键到主键索引中查询具体的数据,这个过程被称为回表,覆盖索引能避免回表,这个后面再详细说。
这里,需要注意的一点是,在MyIsam存储引擎中,主键索引的叶子节点存储的并不是具体的数据,而是数据所在的物理磁盘地址,至于为什么会存在这个区别,还在思考中…
另外,需要了解的有三个与索引优化相关的知识点需要了解一下。第一个是索引覆盖,当我们创建了一个联合索引(a,b)时,由于在索引中就包含了a和b的值,在这种情况下,如果我们执行select a,b from … 的话,就可以让这个联合索引直接覆盖我们要查询的数据,避免发生回表,从而提高差效率。第二个是范围查询导致索引被截断,例如我们创建了一个(a,b,c)索引,在查询条件中如果指定了 a=x and b > y and c = z,那么会导致索引只会在a和b两个字段上应用,而c的索引比对失效,第三个是索引的最左匹配原则,在建立索引和进行数据查询时,要注意考虑以上几种情况,提高查询效率。
下面给出一些在实践中使用过的一些索引最佳实践
- 尽量使用等值匹配
- like模糊查询尽量保证左闭右开,利用左前缀匹配
- 不要在索引列上左计算操作,会导致索引失效,可以将计算逻辑移到应用中完成
- 尽量使用覆盖索引
- 尽量不要在所以列上使用不等值匹配(!= <>),会导致索引失效
- 字符串类型索引列在匹配时要加上单引号,否则索引失效
- 尽量别用or,会导致索引失效
- 不要判断null(is null / is not null),会导致索引失效(建表时,给默认值)
下面再简单说一说MySql中的锁,在MySql中直接支持的锁有全局锁,表锁和行锁,这些锁又可以分为共享模式和排他模式,同时,这些锁都可以归为悲观锁
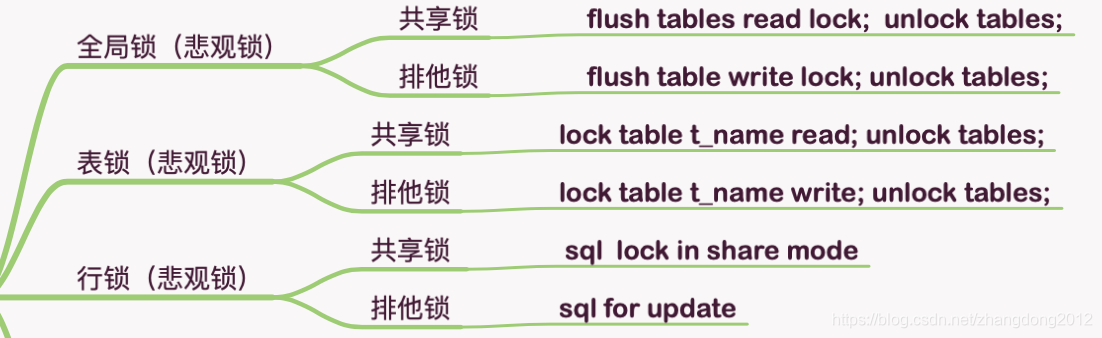
而还有一种锁时乐观锁,对于乐观锁,mysql并没有显示的支持,可以通过在表中定义版本号字段自己来实现,实现的思路就是在更新数据前,先对比目前数据库中数据的版本号是否与持有的版本号一致,如果一致则更新,如果不一致则不更新,其实这也是java 并发包中cas操作的核心逻辑。
下面说说mysql中的事务。事务可以说的学习mysql时,最重要的一个知识点之一,首先说说事务具有的特性
- 原子性
- 一致性
- 持久性
- 隔离性
对于这四个关于事务的特性就不一一解释了,详细大家都了解,其中,隔离性是事务中一个比较重要的知识点。我们都知道,如果没有事务隔离级别的控制,在并发环境下,会出现以下几种并发问题
- 脏读
- 不可重复读
- 幻读
其中,脏读是一个事务读到了令一个事务未提交的事务,不可重复读是指在一个事务中,多次读取同一条数据时,读到的数据不一致,而幻读指的是,一个事务读取一组数据时,读到的数据总条数不一致。不可重复读强调的是同一条数据的不一致,主要针对update操作,而幻读强调的是数据条数的不一致,针对的是insert和delete操作。
针对以上情况,mysql提供了四种事务隔离级别,这四种隔离级别分别是
- read uncommited
- read commited
- read repeatable
- serializable
read uncommited是读未提交,不能解决任何问题,没什么鸟用;read commited是读已提交,也就是会读到其他数据提交的数据,能够解决脏读问题;read repeatable是可重复读,也就是在一个事务中,读取同一条数据的结果总是一致的,能够解决不可重复读问题,但不能解决幻读;serializable是串行化模式,能够解决所有问题。
这几种事务隔离级别的隔离性依次增加,数据的一致性越来越高,但是性能也越来越差,在mysql中默认的事务隔离级别是read repeatable。需要明确的是,以上讨论都是基于InnoDB存储引擎的。
那么,mysql是如何实现事务隔离级别的呢?对于一个程序员来说,解决并发问题的一把利器就是锁,没错,锁缺失能解决并发安全问题,但是锁存在的一个最重要的缺陷就是性能太差,以java synchronized为例,在并发极高的情况下,他的性能是非常差的,mysql作为一个应用做广泛的开源数据库,可以说撑起了互联网的半边天,所以他不可能简简单单的用锁来解决这个问题,下面大咖登场了,这位大咖就是MVCC。
MVCC的全称是Multi Version Concurrent Control,即多版本并发控制。在展开讲MVCC前,需要先了解一下当前读和快照读,在多版本环境中,当前读表示每次读取数据都读取最新的版本,而快照读,表示在读取数据前,先为本都读创建一个当前时间的数据快照,无论以后数据是否被修改,本次读取的都是这个快照中的数据。
MVCC就是为每一个事务创建一个数据的快照,然后基于这个快照完成不同的隔离级别要求,对于上面讲到的mysql支持的四种隔离级别,在read Uncommited模式下,不涉及MVCC机制,每次读取数据都是读最新版本的数据,而对于serializable模式下,直接使用表锁实现,将所有事务串行化,所以,只有在read commited和repeatable read模式下才涉及到mvcc机制,但是在这两种模式下,mvcc的运行机制有一些区别,在read commited下,读取的是最近一次被提交的数据,也就是当前读,而在repeatable read模型下,读取的是当前事务开始是的快照数据,也就是快照读。
mysql的MVCC是基于undo log实现的,undo log本身就是用来做事务回滚的,所以并没有额外的开销。在mysql中有一个常见的日志,例如undo log、redo log、bin log、慢查询日志等等,其中,
- undo log用来实现事务回滚,同时为MVCC机制提供底层的支持
- redo log是物理层面的,主要用来完成写磁盘前的数据缓冲,提供写磁盘效率,redo log是InnoDB特有的
- bin log是逻辑日志,主要用来做主从复制,数据恢复和数据备份,bin log是server层特有的
- 慢查询日志是记录超过指定执行时间的sql,经常用在排查问题以及性能调优中
提供redo log和bin log,就不得不说一说两阶段提交这个问题。两阶段提交指的是在写bin log和redo log时,通过两次确认来保证两种日志中数据的一致性,实现mysql的崩溃恢复,那么这又是怎么回事呢?
在使用InnoDB存储引擎时,进行数据更新时,首先,会写redo log,此时redo log处于prepare节点,然后存储引擎反馈给server层,执行收到通知以后,会将本地修改写入binlog,写入成功后会告诉存储引擎提交这次事务。
下面我们在说说慢查询和查询优化。了解慢查询的目的是优化这个慢查询,所以,对于慢查询的一般处理思路是:
- 根据慢查询日志反馈,找出执行时间比较长的sql
- 通过explain查看执行计划,针对执行计划的返回找出优化点
- 通过show profile查看sql的执行性能
- 根据上面收集到的信息,优化sql或优化业务
先说说通过explain能得到什么信息
- select_type:查询类型,simple/primary/union/subquery等
- table:表名称
- type:索引使用情况,
all-全表扫描,
eq_ref在等值连接上使用了唯一索引或主键索引,
system:表中只有一条记录或没有记录
constant:where条件中使用主键索引或唯一索引,并且只会返回一条记录
ref:在等值条件中使用了主键索引或唯一索引
range:在范围查询中使用了主键索引或唯一索引
index:使用了普通索引 - key:使用到的索引名称
- rows:执行计划中估算的扫描数据的行数,不准确
- extra:
哲学(矫情)思考
- 谈任何问题,要经得起别人的质疑 - 张维为(前国家最高领导人翻译)