版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
第一题:简单题
1、什么是全局变量?
2、什么是局部变量?
3、函数内部如何修改全局变量(如何声明全局变量 )?
4、写出已经学过的所有python关键字,分别写出用途?
第二题:数据转换
现在有以下数据, li1 = ["{‘a’:11,‘b’:2}","[11,22,33,44]"]
需要转换为以下格式: li1 = [{‘a’:11,‘b’:2},[11,22,33,44]]
请封装一个函数,按上述要求实现数据的格式转换
第三题:数据转换



# 第一题
# 1.直接定义在py文件(模块)中的遍历叫做寿 全局变量,全局变量在该文件中任意地方都可以访问
# 2.定义在函数中的变量,叫做局部变量,局部变量只有在该函数内部才能访问
# 3.在函数中定义(或修改)全局变量,需要使用global进行声明
# 4.已经学过的python关键字
"""
学过的:22个
False:bool数据类型
True:bool数据类型
None:表示数据为空
and:逻辑运算符:与
or:逻辑运算符:或
not:逻辑运算符:非
is:身份算符
in:成员运算符
del:删除数据
pass:表示通过(一般用来占位的)
if elif else:条件判断
while:条件循环
for:遍历循环
break:用来终止循环的
contiune:中止当前本轮循环,开启下一轮循环
def:定义函数
return:函数返回值
global:定义全局变量
nonlocal:嵌套函数中修改外部作用域的值
lambda:定义匿名函数
# 还没学的:13个
as,assert,calss,except,finally,
from,import,raise,try,with,
yield,async,await
"""
# 第二题
# 现有以下数据
li = ["{'a':11,'b':2}", "[11,22,33,44]"]
# 分析:这是一个列表,列表里面有两个字符串,"{'a':11,'b':2}"这个字符串是一个字典,"[11,22,33,44]"这个字符串是一个列表
# 有eval函数,它可以识别python中的表达式,
# 需要转换成以下格式:
# li=[{'a':11,'b':2},[11,22,33,44]]
# 请封装一个函数,按上述要求实现数据的格式转换
def work2(data):
# 创建一个新列表
new_list = []
# 遍历列表中的数据
for i in data:
res=eval(i)
# 将数据转换后放入新的列表
new_list.append(res)
# 返回转换后的数据
return new_list
print(work2(li))
运行结果:
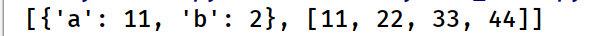
# 第三题
# 现有一组用例数据如下:
cases = [
['case_id', 'case_title', 'url', 'data', 'excepted'],
[1, '用例1', 'www.baidu.com', '001', 'ok'],
[4, '用例4', 'www.baidu.com', '002', 'ok'],
[2, '用例2', 'www.baidu.com', '002', 'ok'],
[3, '用例3', 'www.baidu.com', '002', 'ok'],
[5, '用例5', 'www.baidu.com', '002', 'ok'],
]
# 需要转换成以下格式
res1 = [
{'case_id': 1, 'case_title': '用例1', 'url': 'www.baidu.com', 'data': '001', 'excepted': 'ok'},
{'case_id': 4, 'case_title': '用例4', 'url': 'www.baidu.com', 'data': '002', 'excepted': 'ok'},
{'case_id': 2, 'case_title': '用例2', 'url': 'www.baidu.com', 'data': '002', 'excepted': 'ok'},
{'case_id': 3, 'case_title': '用例3', 'url': 'www.baidu.com', 'data': '002', 'excepted': 'ok'},
{'case_id': 5, 'case_title': '用例5', 'url': 'www.baidu.com', 'data': '002', 'excepted': 'ok'}
]
# 分析:这是一个嵌套列表,['case_id','case_title','url','data','excepted']第一列当作键, [1,'用例1','www.baidu.com','001','ok']当作值,把它成字典格式,
# 用第一列和其它聚合打包,就可以得到下面的格式
# 封装一个函数,完成上述数据转换的功能,并将并case_id大于3的用例数据过滤出来,得到如下结果
res2 = [
{'case_id': 4, 'case_title': '用例4', 'url': 'www.baudi.com', 'data': '002', 'excepted': 'ok'},
{'case_id': 5, 'case_title': '用例5', 'url': 'www.baudi.com', 'data': '002', 'excepted': 'ok'}
]
# 方式一:不使用filter
def work3_1(cases):
# 创建一个新的列表
new_cases = []
# 获取新数据的key(通过下标获得title)
title = cases[0]
# 遍历所有的数据(通过切片进行遍历)
for data in cases[1:]:
# 将遍历的数据和key进行聚合打包,并转换为字典
c = dict(zip(title, data))
print(c)
if c['case_id'] > 3:
# 将转换后的数据,放到新列表中
new_cases.append(c)
# 返回转换之后的结果
return new_cases
res3 = work3_1(cases)
print(" ")
print(res3)
运行结果:

# 方式二:使用filter
def work3_2(cases):
# 创建一个新的列表
new_cases = []
# 获取新数据的key(通过下标获得title)
title = cases[0]
# 遍历所有的数据(通过切片进行遍历)
for data in cases[1:]:
# 将遍历的数据和key进行聚合打包,并转换为字典
c = dict(zip(title, data))
print(c)
if c['case_id'] > 3:
# 将转换后的数据,放到新列表中
new_cases.append(c)
# 使用filter过滤结果
def func(x):
return x['case_id'] > 3
result = filter(func, new_case)
# result=filter(lambda x:x['case_id'>3,new_cases])
# 返回转换之后的结果
return new_cases
res4 = work3_2(cases)
print(" ")
print(res4)