导数
导数(Derivative)的几何意义可能很多人都比较熟悉:当函数定义域和取值都在实数域中的时候,导数可以表示函数曲线上的切线斜率。除了切线的斜率,导数还可以表示该点的变化率。可以表示为
将上面的公式表示为图像如图
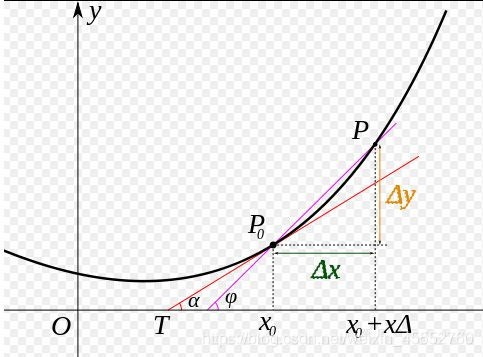
简单点说,导数代表了在自变量变化趋于无穷小的时候,函数的变化与自变量变化的比值就是导数,其几何意义是该点的切线,物理意义有该时刻的瞬时变化率。
例如:在物理学中有平均速度和瞬时速度之说。
平均速度为
其中
表示平均速度,
表示路程,
表示时间。这个公式可以改写为
其中
表示两点之间的距离,而
表示走过这段距离需要花费的时间。当
趋向于0(
)时,也就是时间变得很短时,平均速度也就变成了在
时刻的瞬时速度,表示成如下形式:
实际上,上式表示的是路程
关于时间
的函数在
处的导数。一般的,这样定义导数:如果平均变化率的极限存在,即有
则称此极限为函数
在点
处的导数。记作
或
或
或
。
通俗地说,导数就是曲线在某一点切线的斜率。
拓展与思考
微分、导数、积分,这三者之间,有什么联系?
参考:https://www.zhihu.com/question/264955988
2.3.2 偏导数
既然谈到偏导数(Partial derivative),那就至少涉及到两个自变量。以两个自变量为例, ,从导数到偏导数,也就是从曲线来到了曲面。曲线上的一点,其切线只有一条。但是曲面上的一点,切线有无数条。**而偏导数就是指多元函数沿着坐标轴的变化率。 **
注意:直观地说,偏导数也就是函数在某一点上沿坐标轴正方向的的变化率。
设函数
在点
的领域内有定义,当
时,
可以看作关于
的一元函数
,若该一元函数在
处可导,即有
函数的极限
存在。那么称
为函数
在点
处关于自变量
的偏导数,记作
或
或
或
。
偏导数在求解时可以将另外一个变量看做常数,利用普通的求导方式求解,比如 关于 的偏导数就为 ,这个时候 相当于 的系数。
如下图的动态演示,某点 处的偏导数的几何意义为曲面 与面 或面 交线在 或 处切线的斜率。
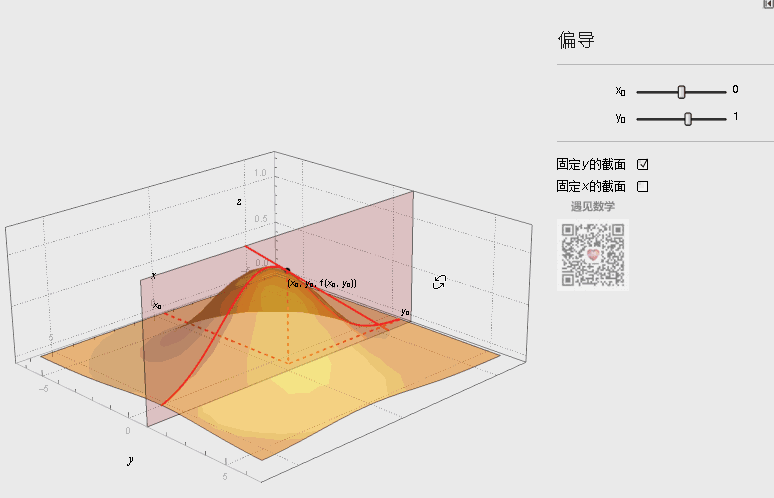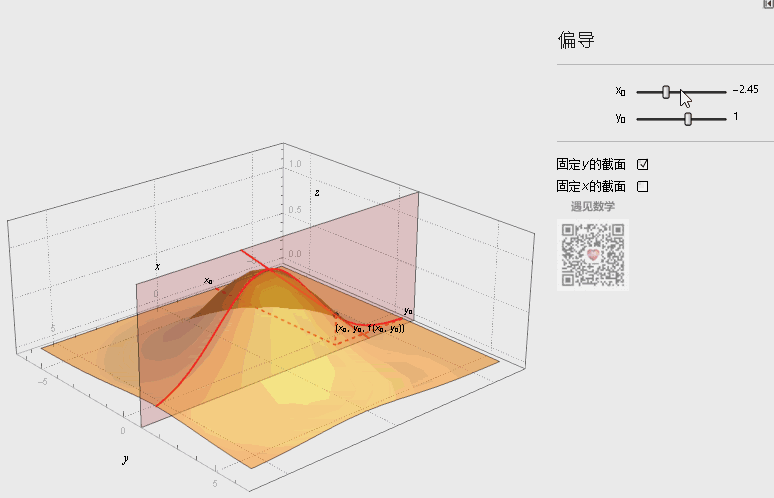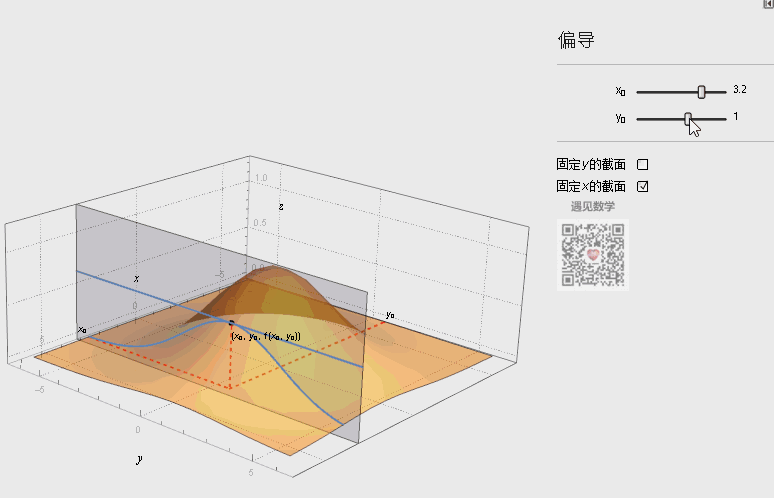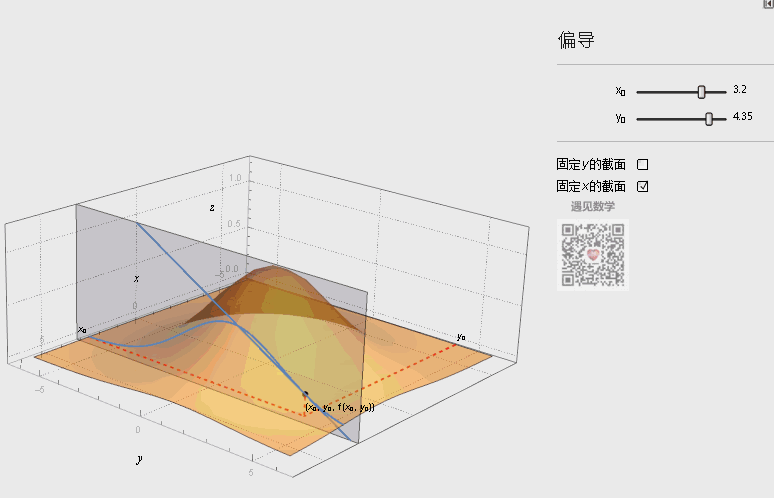
注:图片引用自公众号“遇见数学”
导数和偏导数有什么区别?
导数和偏导没有本质区别,如果极限存在,都是当自变量的变化量趋于0时,函数值的变化量与自变量变化量比值的极限。
- 一元函数,一个 对应一个 ,导数只有一个。
- 二元函数,一个 对应一个 和一个 ,有两个导数:一个是 对 的导数,一个是 对 的导数,称之为偏导。
- 求偏导时要注意,对一个变量求导,则视另一个变量为常数,只对改变量求导,从而将偏导的求解转化成了一元函数的求导。
2.3.3 方向导数、梯度
偏导只是多元函数沿着坐标轴的变化率,当我们扩展到曲面,如下图,能否沿着任意方向的变化率呢?
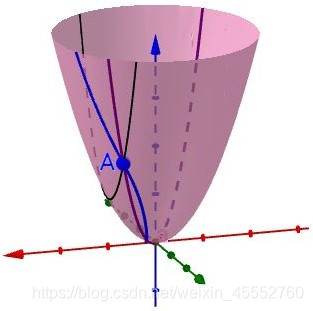
在上图曲面中,可以作无数条过 点的曲线(图中画出了3条示例),每一根曲线都可以作一条切线,也即是可以得到任意方向的变化率。这就是方向导数(Directional Derivative),进一步地,对于其中方向导数取最大值的方向就是梯度(Grad),也就是函数变化率最大的方向。如下图,观察底部的箭头指向(仅表示方向),其中蓝色表示方向导数,黑色表示梯度,梯度方向始终指向函数值上升最大的方向。
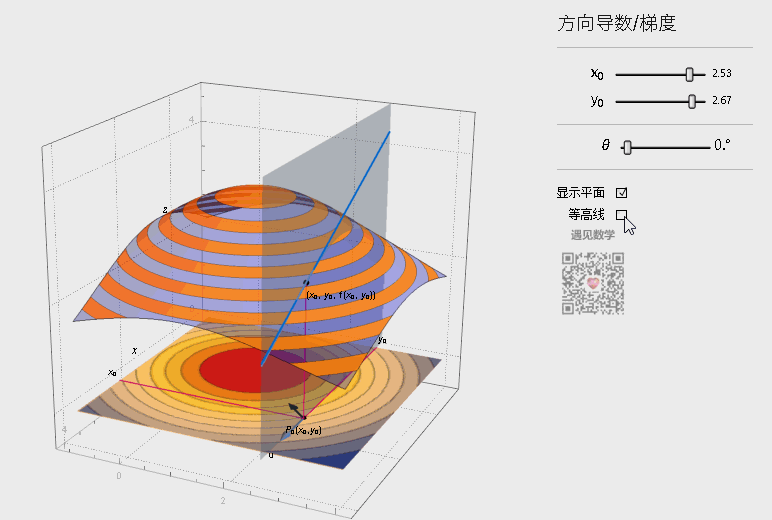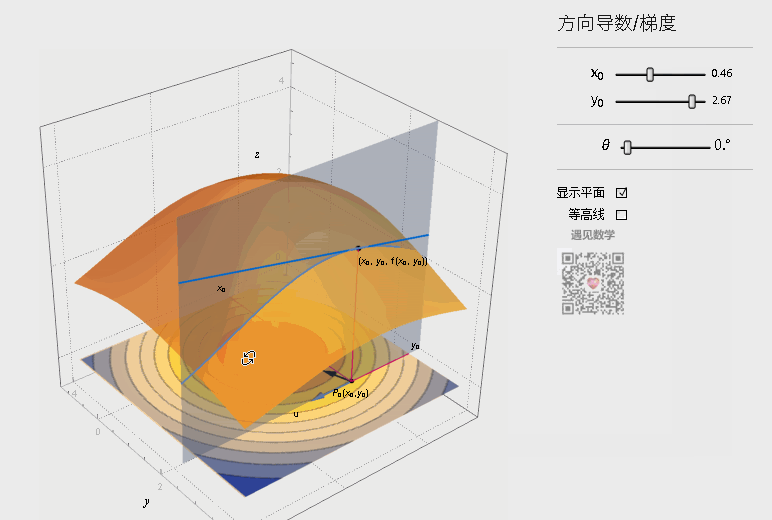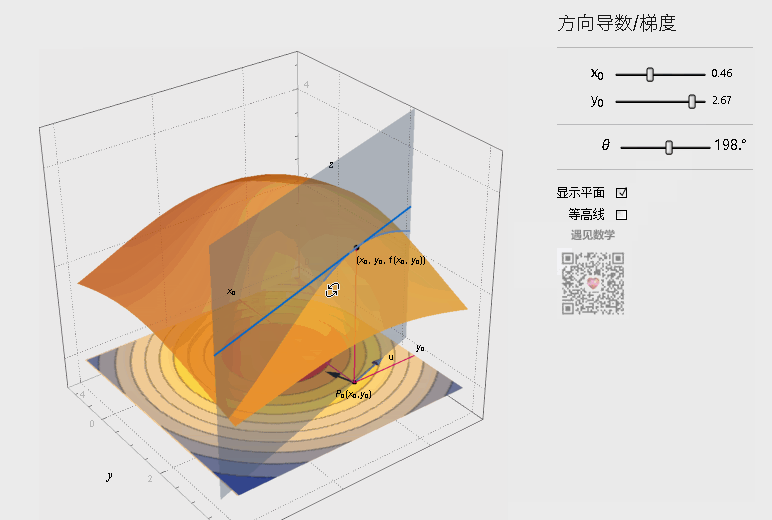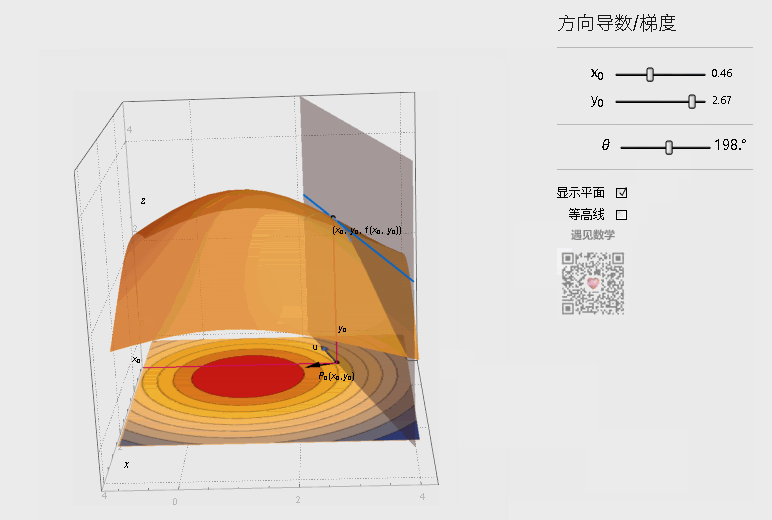
注:图片引用自公众号“遇见数学”
梯度在机器学习/深度学习中具有极其重要的地位,这儿多说一点,举个栗子:
假如你在一座山上,蒙着眼睛,但是你必须以最快的速度到达山谷中最低点的湖泊,你该怎么办?

只需要通过手感受附近梯度的最大的方向,然后一直沿着梯度相反的方向就可以以最快的速度到达谷底:
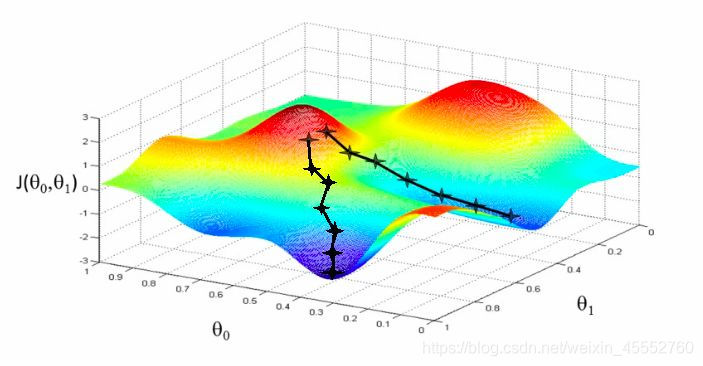
细节可参考:Introduction to Gradient Descent Algorithm (along with variants) in Machine Learning
这就是大名鼎鼎的梯度下降算法。
2.3.4 神经网络训练机制—反向传播算法
神经网络的训练过程就是对我们代价函数进行优化的过程,这个优化的参数更新过程需要梯度下降算法,且在更新参数权重的时候需要我们的误差回传,这就是我们反向传播算法。
这部分是一个例子,通俗介绍神经网络的训练机制,也就是梯度下降算法及反向传播算法的应用。例子中省略了公式推导细节,感兴趣的可参看本节末的扩展阅读加深理解。
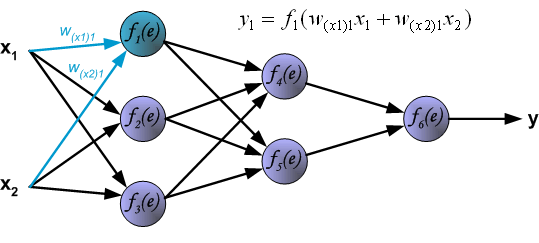
为了说明这个过程,引入一个简单的神经网络,如下图,是一个包含两个输入和一个输出的三层神经网络:
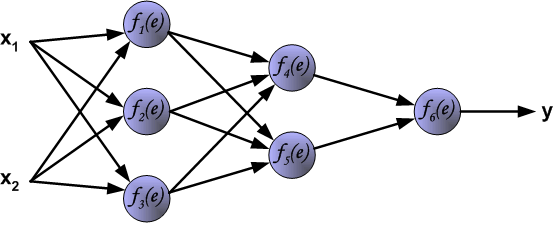
图中每个神经元由两个部分组成:第一部分为权重系数和输入信号的乘积和,第二部分为神经元的非线性激活功能。如下图,信号 是加法器的输出信息, 是非线性单元的输出信号,而 是神经元的输出信号。
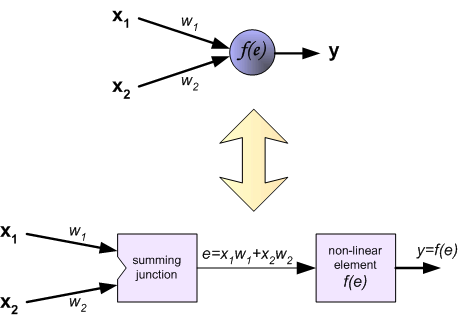
为了训练网络,我们需要训练数据,由输入信号x 和x 及对应的期望输出z组成。网络训练是一个迭代过程,在每次迭代中(前向传播过程):从输入开始,计算每个神经元的输出信号。如下图, 表示输入信号 到神经元 的连接权重, 表示神经元 的输出信号。
神经元1
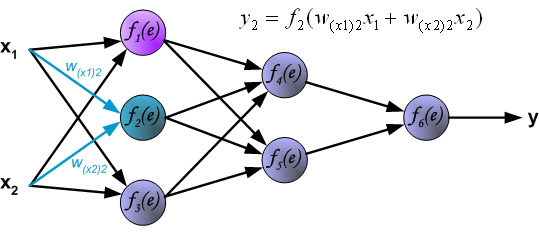
神经元2
神经元3
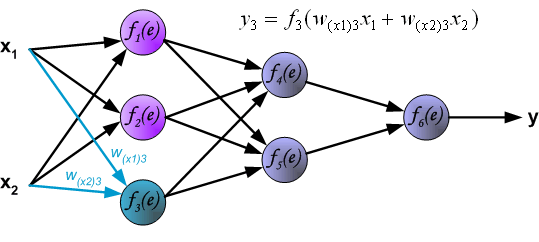
通过中间的隐藏层传播过程中, 表示从神经元 输出到输入下一层神经元 之间的连接权重。
隐藏层神经元4
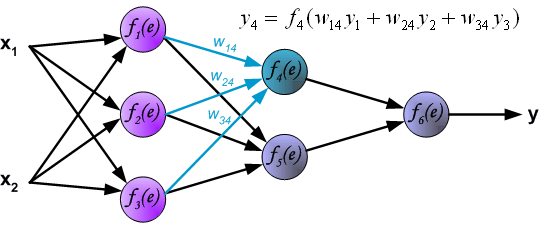
隐藏层神经元5
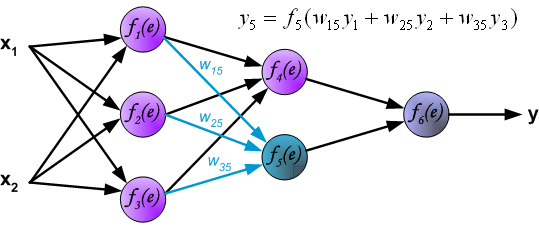
输出层神经元6
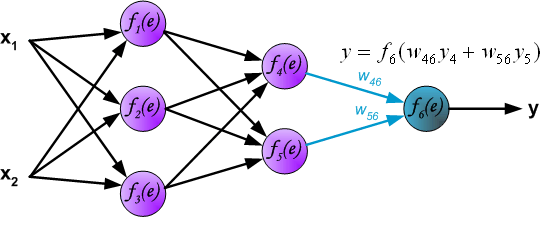
以上为我们的前向传播过程(forward-propagation)。
接下来,将网络的输出 与训练集中的期望输出 进行比较,得到输出神经元的误差 。
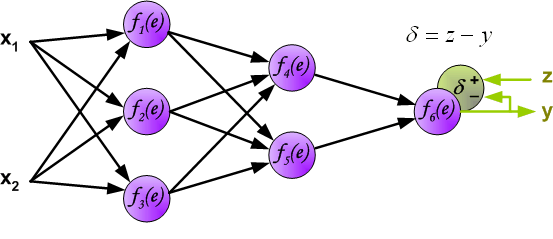
虽然我们计算了输出层神经元的误差,但是,我们不可能直接计算内部神经元的误差,因为内部神经元的期望输出是未知的。为了计算内部神经元的误差,上世纪80年代提出了反向传播算法,大概思路是将误差 反向传回所有神经元。
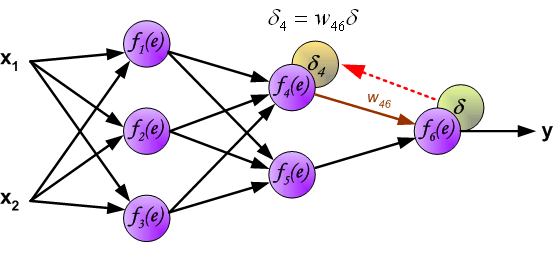
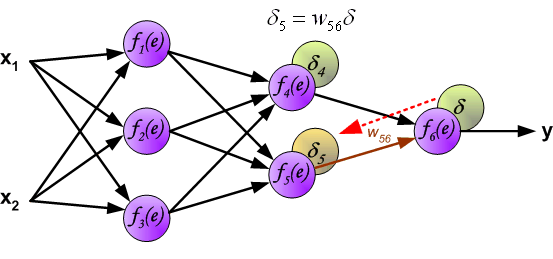
反向计算各神经元误差过程中,权重系数 与前项传播过程相同,一直回传至输入。
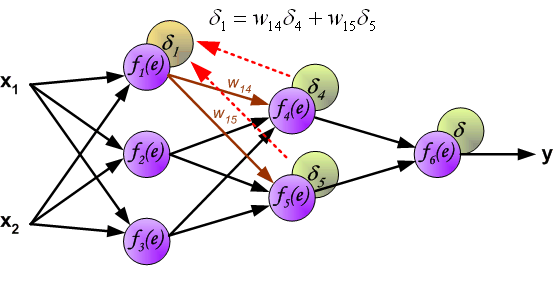
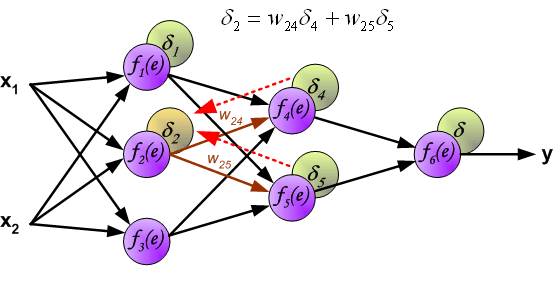
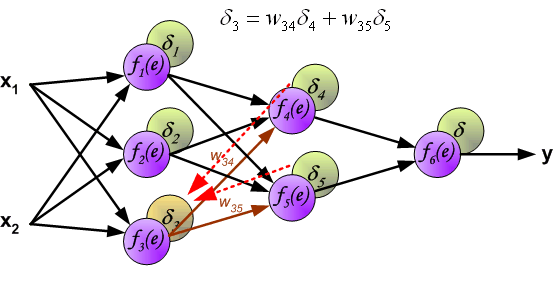
计算完每个神经元的误差之后,更新神经元间连接权重,这使用到了梯度下降发更新权重。
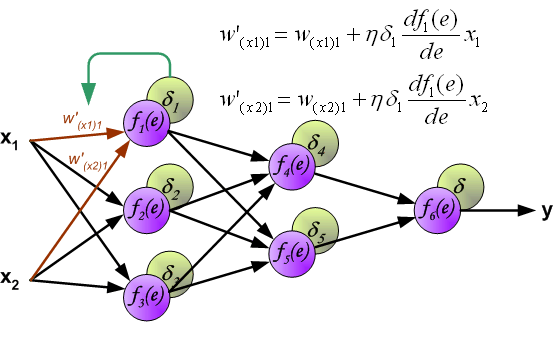
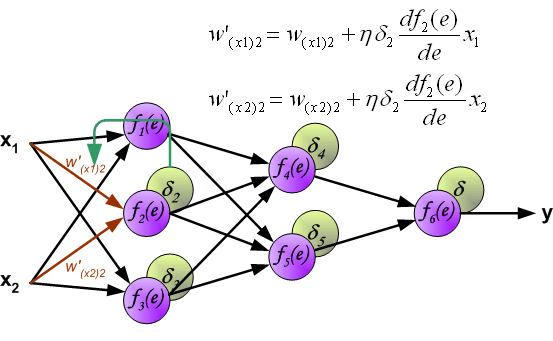
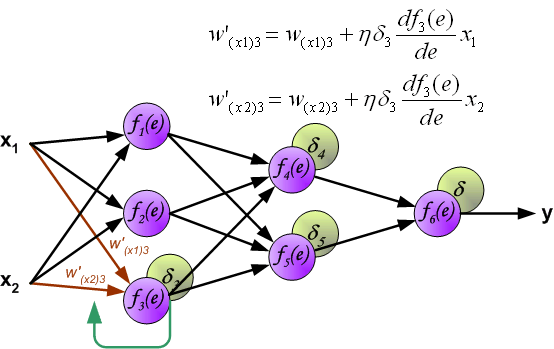
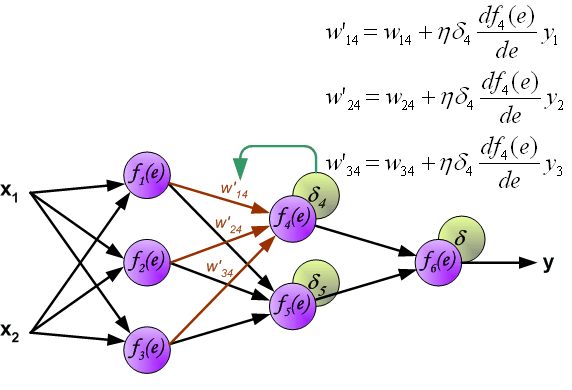
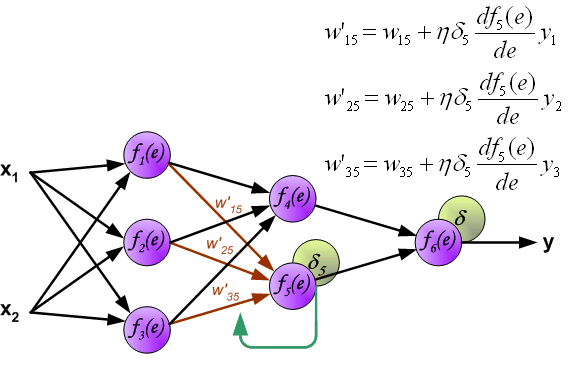
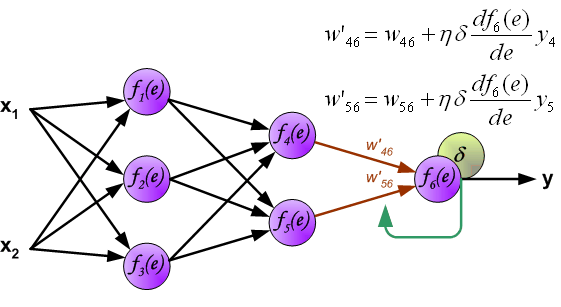
其中, 是学习率,影响学习速度。
如此往复一次次迭代,更新网络权重,就是网络训练过程。
扩展阅读
思考:如何成为武林高手?
以上就是本文的所有内容,最后讨论一个问题:如何成为武林高手?
借用台大教授李宏毅老师的话,武林高手讲究内外兼修。
Deep Learning 也需要內外兼修
-
内力:运算资源
-
招数:各种技巧
内力充沛,平常的招式也有可能发挥巨大威力,不需要太花哨的招式
只有内力,没有招数,也是不行的(空有一身蛮力)

最后,希望大家都可以成为内外兼修的高手~
声明
本博客所有内容仅供学习,不为商用,如有侵权,请联系博主谢谢!
参考文献
[1] 同济大学数学系.高等数学(第七版)[M],高等教育出版社,2014.
[2] 反向传播算法
[3] Jim Liang, Getting Started with Machine Learning,2018
[4] 周志华.机器学习[M].清华大学出版社,2016.
[5] Ian,Goodfellow,Yoshua,Bengio,Aaron…深度学习[M],人民邮电出版,2017