编译器简要介绍
一、语言的翻译
复杂就是将简单的事情重复一万遍
计算机只能识别简单的0-1串,高低电平控制着计算机内部各种简单的寄存器、逻辑门、触发器完成对应的功能,然后,这些寄存器、逻辑门、触发器会以不同的组合方式重组为更复杂的功能硬件。这个过程一再重复,最终生成了复杂的计算机芯片,如CPU、内存芯片等。
可是,0-1串只是计算机的语言,它并不符合人类的思维习惯。
为了解决这个问题,有人想出了一个办法:把各种特定的0-1串与单词联系在一起,组成一个映射表,如果我们输入某个单词,便会启动一个简单的程序将它翻译为映射表中对应的0-1串。这些“单词”就是助记符,这个“简单的程序”就是汇编器。
然而这些助记符只是特定0-1串的别名,芯片内部最微不足道的一次操作,如修改寄存器的值、给数据分配内存区域,都需要我们自己动手。
汇编并没有把人类从繁重的细节中拯救出来,它只是让不易理解的0-1串好记了点,仅此而已。
但人类天生就是爱征服的,为此他们又发明了各类高级语言。
高级语言的出现真正是计算机发展史上的一个重要里程碑,它拥有自己的一套词法、语法和语义,就像自然语言一样完善。它只关注怎么做,而把具体的细节交给编译器来承担。比如,我说“上天”,编译器会解析这条指令,然后根据含义帮我把飞机组装好,油加满,然后点燃发动机一飞冲天,我只看到了“上天”这个结果,而不知道到底是怎么上天的。
一条简单的高级语言指令往往对应着几十甚至几百条的汇编指令,编译器即是这两者之间的一座桥梁。
那么现在我们有了最底层的0-1串、汇编语言和高级语言,如何完成语言的翻译,这正是编译原理回答的问题。
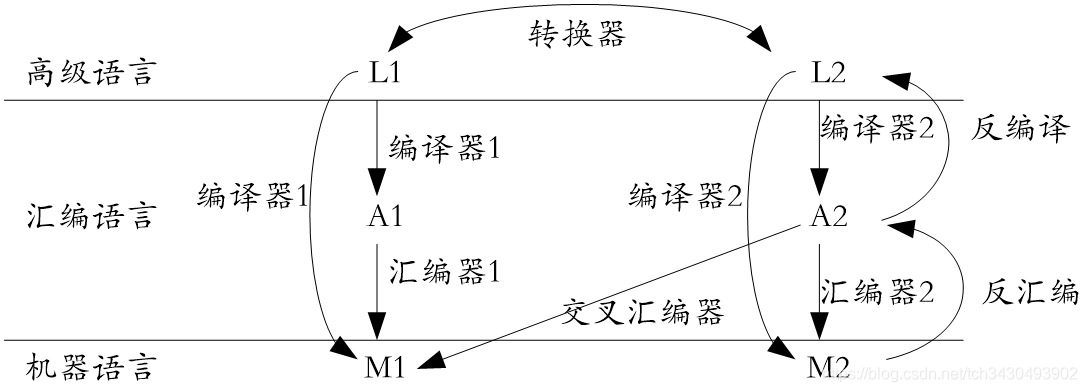
编译是指高级语言转换为汇编语言或机器语言,汇编是指汇编语言转换为机器语言。
二、编译器的基本组成
打开黑盒子!
编译器是一个黑盒子。
高级语言程序被编译器翻译为二进制目标程序,并最终链接相关库的二进制文件成为可执行文件。然而,在这里,我们只知道‘what’,而不知道‘how’。
那么我们打开这个盒子,一探究竟!
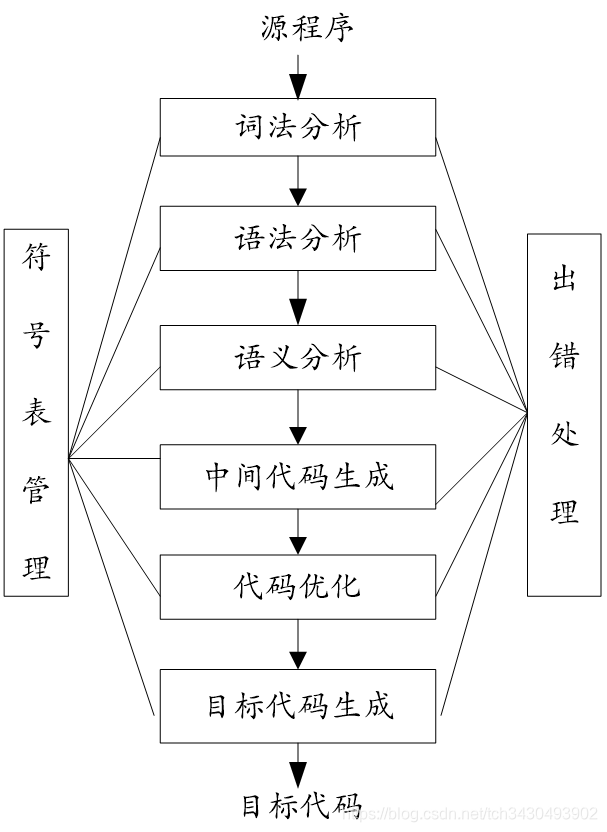
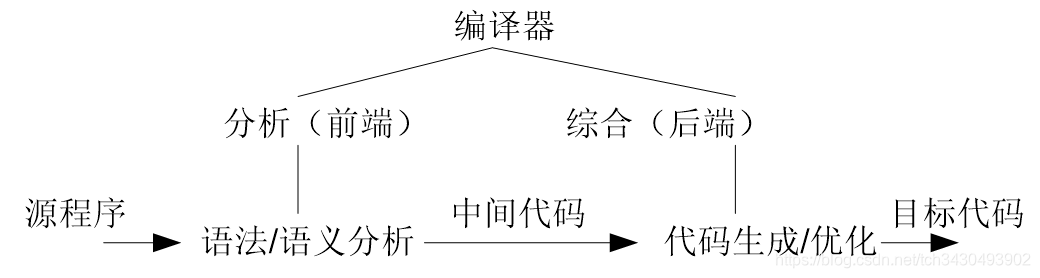
编译器内部基本是一个顺序执行的过程,按阶段可依次划分为词法分析、语法分析、语义分析、中间代码生成及优化、目标代码生成,有时候词法分析是语法分析的子程序。除此之外,还有两个管理器贯穿全局:符号表管理器和出错管理器。
世界具有灵魂,事物之间的关系简直剥离不开。
计算机理论是对现实世界的提取、抽象和模拟。
回想一下你把英语翻译为汉语的过程:识别单词、识别句子、理解意思、脑海中生成印象、表述为中文并做恰当的修饰。
把这个过程用到编译器上便是:词法分析、语法分析、语义分析、中间代码生成、目标代码生成。
1.词法分析
词法分析的主要任务是识别记号。
每一个记号都代表一类单词,常见的记号有关键字、标识符、字面量、特殊符号,每一个记号都有不同的构词规则,即“模式”。词法分析器根据“模式”匹配到不同的记号,然后交给语法分析器处理。
除此之外,词法分析还承担以下任务:
- 过滤源程序中的无用成分,如注释、空格、回车等。
- 处理与平台有关的具体输入。有些符号在不同平台有不同表示。
- 检测词法错误。
词法分析的工具:
- 正规式:对模式的形式化描述,你应该会联想到正则表达式。
- 有限自动机:记号的识别,分为NFA和DFA。
2.语法分析
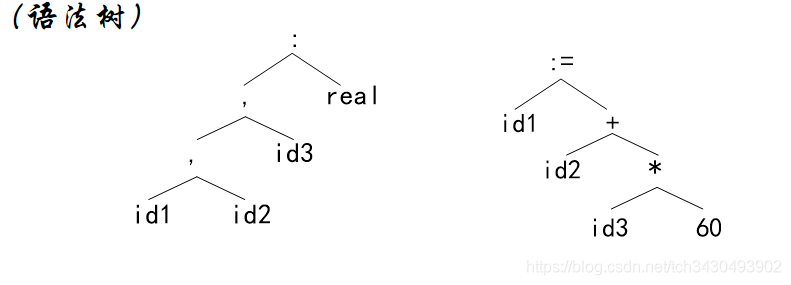
语法分析的任务是识别句子,构造语法树。
根据高级语言的语法规则,语法分析器对前一阶段产生的记号流进行结构上的识别,它在回答一个问题:”单词“的特定组合是否能组成结构正确的”句子“?
语法分析的工具:
- 上下文无关文法(非终结符、终结符、开始符号、产生式)
语法分析方法:
- 自顶向下语法分析(LL分析器)
- 自底向上语法分析(LR分析器)
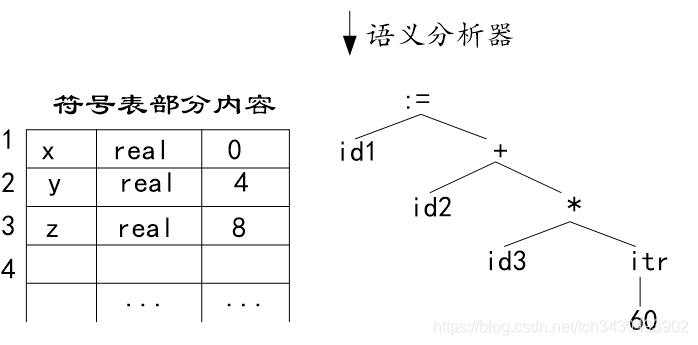
3.语义分析
语法分析保证句子结构正确,语义分析保证句子语义正确。
比如"人有翅膀”这句话,从句子结构上看,“人”是主语,“有”是谓语,“翅膀”是宾语,简直无懈可击;然而人是不可能有翅膀的,这里的宾语只能 是“腿”、“手”、“眼睛”,而不能是“翅膀”,所以从语义的角度看,此处存在类型错误,理当被改正或丢弃。
语义分析根据语义规则对语法树中的语法单元进行静态语义检查,检测到不符合语义规则就会生成一个错误。
4.中间代码生成及优化
与具体平台无关,这是中间代码的最大优势。
理论上说,语义分析完成之后,执行计算的基本元素已经具备,可以直接生成目标代码并加以执行了。然而各种机器之间的指令集存在差异,此时如果在一台机器上直接生成目标代码,则无法迁移到其他机器上执行,最好的解决办法就是生成一种与机器无关的中间码,然后每一台机器能针对中间码生成与平台相适应的底层硬件指令,皆大欢喜!
另外,在中间代码这一阶段还会有优化,通过去除中间代码中的冗余部分以达到提高空间和时间效率的作用。

5.目标代码生成
生成依赖平台的目标代码。
它有多种形式:
- 汇编语言形式。简单易读,仍需一次汇编才能执行。
- 可重定位二进制代码形式。二进制代码模块,没有链接库文件,最常见的编译形式。
- 内存形式。立刻执行,不写入磁盘。

6.符号表管理及出错管理
这两个管理器贯穿全局。
符号表记录了源程序中符号的必要信息,以便编译器在需要时可以进行快速、准确的查找。符号表管理器维护这个符号表。
出错管理器负责对编译过程中检测的错误,如词法错误、语法错误、语义错误等进行处理,要么停止并指出错误的地方,要么是修复这个错误。出错管理器是错误处理策略的集合。
三、编译器的分析/综合模式
了不起的中间代码!
为了便于分析问题,编译器被分为两种模式:分析、综合。
分析模式包括词法分析、语法分析、语义分析,整个过程与具体机器无关。
综合模式则是生成目标代码直至最后的所有过程,它与机器紧密相关。
连接这两种模式的,是中间代码。
通过一种这样的划分,我们可以使用不同的前端、后端,只要保证中间代码是相同的,编译器就照样能翻译一个程序。
四、编译器的编写工具
工欲善其事,必先利其器。
最初的编译器是纯汇编手工编制的,由于编译器结构的复杂性,手动编写的效率极其低下,如早期的FORTRAN用了18年才编完,简直惨不忍睹。
为了提高效率,人们开始着手编写能自动生成编译器组件的工具。只要给定必要的参数,这些工具就可以为你自动生成相应的编译器组件,从而快速完成编译器编写,如词法分析器生成器、语法分析器生成器等等。
所以希望快速部署到工程应用上的话,可以充分利用这些生成工具,但如果还希望有所优化的话,那就非得啃透编译原理不可了。