- Hadoop
Hadoop是一个能够对海量数据进行分布式处理的系统架构,为大数据计算提供了分布式的集群环境及计算框架;Hadoop框架的核心是:HDFS和Map Reduce。
HDFS分布式文件系统为海量的数据提供了存储,MapReduce分布式处理框架为海量的数据提供了计算。 - Hadoop部署
Hadoop部署方式分三种,Standalone mode单节点、Pseudo-Distributed mode伪多节点、Cluster mode多节点,其中前两种都是在单机部署。

 节点安装Hadoop
节点安装Hadoop
部署概要:三台机器,且它们都刚装好64位CentOS-6.5,安装系统时用户名为自己的名字拼音,请按要求完成:
① 修改三台机器名为cMaster,cSlave0和cSlave1,并添加域名映射、关闭防火墙和安装JDK。
② 以cMaster作为主节点,cSlave0和cSlave1作为从节点,部署Hadoop。
1.制定部署规划
此Hadoop集群需三台机器(cMaster,cSlave0和cSlave1),其中cMaster作为主节点,cSlave0和cSlave1作为从节点。
2.准备机器
准备三台机器,它们可以是实体机也可以是虚拟机,若使用虚拟机三台机器硬件方面最低要求有1G内存,20G存储空间。
操作系统都安装好CentOS;虚拟机的机器名称分别为cMaster,cSlave0和cSlave1;都创建同一个用户名(你的姓名拼音缩写,下面以ojf这个用户名为例),同一个密码。
3.准备机器软件环境
三台机器都要完成:修改机器名、添加域名映射、关闭防火墙和安装JDK。
(1) 修改机器名
[xmy@localhost~]$ su – root #切换成root用户修改机器名
[root@localhost~]# vim /etc/sysconfig/network #编辑存储机器名文件
将“HOSTNAME=localhost.localdomain”中的“localhost.domain”替换成需要使用的机器名,如cMaster,即此行内容为:
HOSTNAME=cMaster #指定本机器名为cMaster
注意重启机器后更名操作才能生效。其他两台机器cSlave0和cSlave1操作雷同。
(2) 添加域名映射
首先使用ifconfig命令查看本机IP地址,以cmaster为例
[root@ cMaster ~]#ifconfig # 查看cMaster机器IP地址
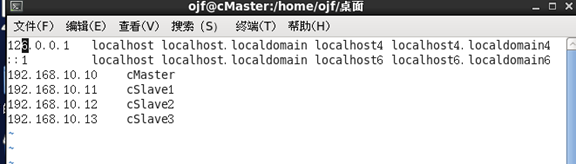
假如获得地址为“192.168.10.10”,机器名为cMaster,接着编辑域名映射文件“/etc/hosts”,
[root@ cMaster ~] vim /etc/hosts #编辑域名映射文件
在文件添加如下内容:
192.168.1.10 cMaster
192.168.1.11 cSlave01
192.168.1.12 cSlave02
 (3) 配置ssh免密码登录
(3) 配置ssh免密码登录
集群之间的机器需要相互通信,所以我们得先配置免密码登录。在三台机器上分别运行如下命令,生成密钥对:
[root@ cMaster ~]# ssh-keygen -t rsa # 三台机器都需要执行这个命令生成密钥对
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
0d:00:bd:a3:69:b7:03:d5:89:dc:a8:a2:ca:28:d6:06 root@ cMaster
The key’s randomart image is:
±-[ RSA 2048]----+
| .o. |
| … |
| . … |
| B +o |
| = .S . |
| E. * . |
| .oo o . |
|=. o o |
|… . |
±----------------+
[root@ cMaster ~]# ls .ssh/
authorized_keys id_rsa id_rsa.pub known_hosts
[root@ cMaster ~]#
以cMaster为主,执行以下命令,分别把公钥拷贝到其他机器上:
[root@ cMaster ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub cMaster
[root@ cMaster ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub cSlave01
[root@ cMaster ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub cSlave02
(4) 关闭防火墙
[root@ cMaster ~]# chkconfig –level 35 iptables off #永久关闭iptables,重启后生效
(5) 安装JDK
Hadoop只能使用Oracle的1.6及以上版本的JDK,不能使用openjdk。用户先下载jdk-x.rpm包,如jdk-7u40-linux-x64.rpm。把jdk-7u40-linux-x64.rpm复制到机器的某个位置,执行如下命令(此方式安装JDK无需配置java_home):
[root@ cMaster ~]# java #查看java是否安装
[root@ cMaster ~]# rpm –ivh /home/xmyjdk-7u40-linux-x64.rpm #以root权限,rpm方式安装JDK
[root@ cMaster ~]# java #验证java是否安装成功
4.下载Hadoop
谷歌搜索“Hadoop download”并下载,以xmy用户身份,将Hadoop分别复制到三台机器上。
5.解压Hadoop
分别以xmy用户登录三台机器,每台都执行如下命令解压Hadoop文件:
[xmy@cMaster~]# tar –zxvf /home/ojf/hadoop-2.7.3.tar.gz #cMaster上ojf用户解压Hadoop
6.配置Hadoop
三台机器都要配置,且配置相同。
首先,编辑文件“/home/ojf/ hadoop-2.7.3/etc/hadoop/hadoop-env.sh”,找到如下一行:
export JAVA_HOME=${JAVA_HOME}
将这行内容改为:
export JAVA_HOME=/usr/java/jdk1.7.0_79
注意:这里的“/usr/java/jdk1.7.0_79”就是JDK的真实安装位置,需根据真实情况更改。
其次,编辑文件“/home/ojf/ hadoop-2.7.3/etc/hadoop/core-site.xml”,将如下内容嵌入到此文件的configuration标签间,三台机器操作相同:
hadoop.tmp.dir/home/ojf/cloudData
fs.defaultFShdfs://cMaster:8020
编辑文件“/home/xmy/ hadoop-2.7.3/etc/hadoop/yarn-site.xml”,将如下内容嵌入到此文件的configuration标签间,三台机器操作相同:
yarn.resourcemanager.hostnamecMaster
yarn.nodemanager.aux-servicesmapreduce_shuffle
最后,将文件“/home/ojf/ hadoop-2.7.3/etc/hadoop/mapre-site.xml.template”重命名为“/home/xmy/ hadoop-2.7.3/etc/hadoop/mapre-site.xml”。接着编辑此文件,将如下内容嵌入到此文件的configuration标签间,三台机器操作相同:
mapreduce.framework.nameyarn
- 启动Hadoop
首先,在主节点cMaster上格式化主节点命名空间:
[ojf@cMaster~]# hadoop-2.7.3/bin/hdfs namenode -format
其次,在主节点cMaster上启动存储主服务namenode和资源管理主服务resourcemanager。
[ojf@cMaster~]# hadoop-2.7.3/sbin/hadoop-daemon.sh start namenode #cMaster启动存储主服务
[ojf@cMaster~]# hadoop-2.7.3/sbin/yarn-daemon.sh start resourcemanager #cMaster启动资源管理主服务
最后,在从节点上启动存储从服务datanode和资源管理从服务nodemanager
[ojf@cSlave0~]# hadoop-2.7.3/sbin/hadoop-daemon.sh start datanode # cSlave0启动存储从服务
[ojf@ cSlave0~]# hadoop-2.7.3/sbin/yarn-daemon.sh start nodemanager
启动hadoop服务,并激活,如下我用的是cSlave1ssh登录cSlave2并激活

同理再配置第三台cSlave3 并验证弹性扩展
然后在主节点cmaster上登录cmaster:8088
 可见activenodes是接受到三台cSlave。
可见activenodes是接受到三台cSlave。