Hadoop安装部署
虚拟机数量:3
系统版本:Centos 7.5
Hadoop版本: Apache Hadoop 2.7.3
主节点信息:
操作系统:CentOS7.5
软件包位置:/home/zkpk/tgz
数据包位置:/home/zkpk/experiment
从节点信息:
操作系统:CentOS7.5
扫描二维码关注公众号,回复: 16838020 查看本文章
软件包位置:/home/zkpk/tgz
数据包位置:/home/zkpk/experiment
从节点信息:
操作系统:CentOS7.5
软件包位置:/home/zkpk/tgz
数据包位置:/home/zkpk/experiment
一、实验目标
- 掌握VMware虚拟机的下载和安装。
- 掌握Linux操作系统Ubuntu或CentOS的下载和安装方法。
- 掌握Linux操作系统的基本命令。
- 掌握主机名和主机列表配置方法。
- 掌握时钟同步配置方法。
- 掌握JDK安装配置方法。
- 熟悉查看防火墙状态、关闭防火墙的命令。
- 掌握免密钥登录配置方法。
- 掌握配置部署hadoop集群方法,理解相关配置文件作用。
- 掌握启动hadoop集群方法。
二、实验要求
- 给出每步操作成功后的效果的截图,最终效果是检查集群启动成功截图。
- 对本次实验工作进行全面的总结。
三、实验内容
- 登录大数据实验室,ping一个外网网址,确保能够ping通。
- 配置主机名,配置hosts列表。(临时设置主机名,名字用自己的姓名拼音,最后设置回原有主机名)。
- 配置时钟同步。
- 防火墙设置:查看防火墙状态、关闭防火墙、开启防火墙、禁止开机启动防火墙。
语句:systemctl status firewalld可以查询防火墙的状态(默认为关闭)
语句:systemctl start firewalld.service开启防火墙(此时查询,防火墙已经开启)
语句:systemctl stop firewalld.service 可以关闭防火墙(此时查询防火墙状况,为关闭)
语句:systemctl disable firewalld.service禁止开机启动防火墙(此时查询,防火墙为关闭) - 安装JDK,测试java是否配置成功(创建一个用自己名字拼音命名的Java类,类名和文件内容自拟)。
- 配置免密钥登录,在master机器上远程登录slave01或slave02。
- 安装部署Hadoop集群,通过实例验证集群配置成功。
四、实验步骤
备注:给出每一个操作步骤成功的效果截图,也可以自己设置实验步骤,完成集群配置,并通过实例验证集群配置成功,下面实验步骤供参考。
-
登录大数据实验室,进入实验,打开一个终端,ping一个外网网址,确保能够ping通。
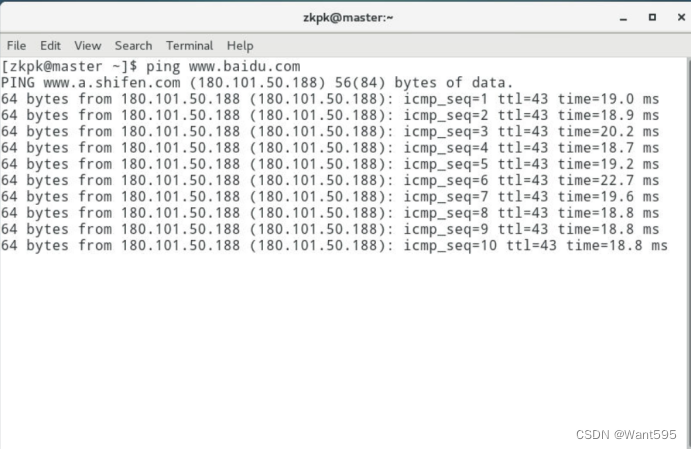
-
配置主机名,配置hosts列表。
- 2.1 操作需要root权限,所以先切换成root用户,密码:zkpk
[zkpk@localhost ~]$ su root
- 2.2 使用gedit编辑主机名文件
[root@localhost ~]# gedit /etc/hostname
- 2.3 临时设置主机名,名字用自己的姓名拼音,检测主机名是否修改成功:bash命令让上一步操作生效,最后设置回原有主机名
[root@localhost ~]# hostname master
[root@localhost zkpk]# bash
[root@master zkpk]# hostname
master
-
2.4 临时设置主机名为slave01,检测主机名是否修改成功:bash命令让上一步操作生效
-
2.5 临时设置主机名为slave02,检测主机名是否修改成功:bash命令让上一步操作生效
-
2.6 配置hosts列表
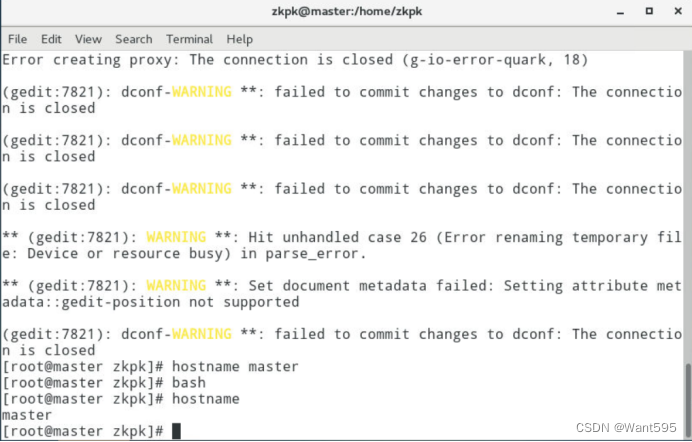
-
配置时钟同步。
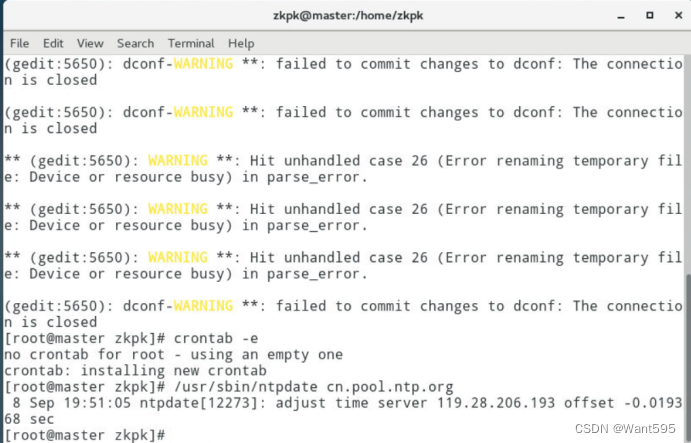
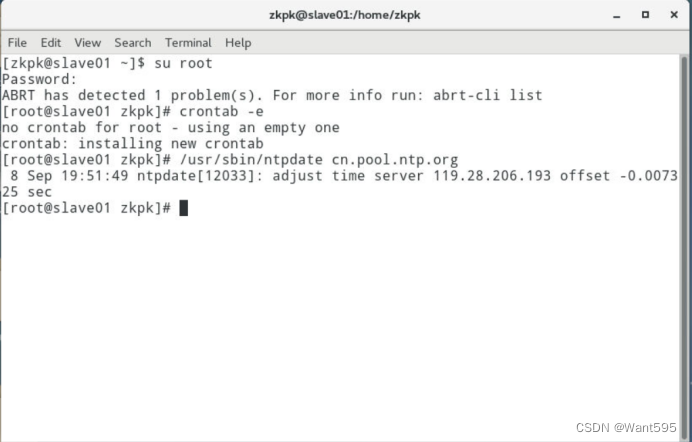
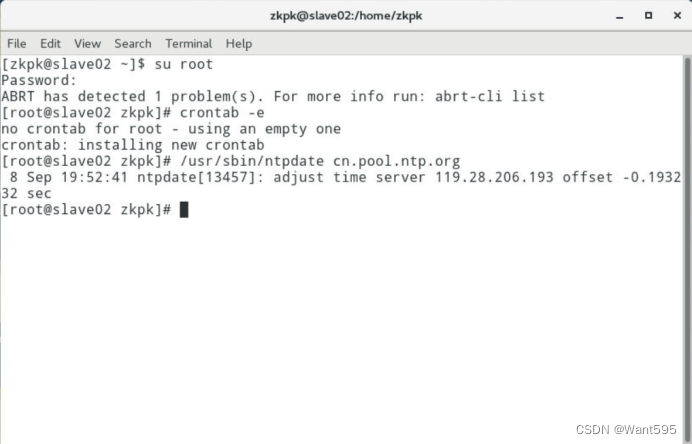
-
查看防火墙状态、关闭防火墙。
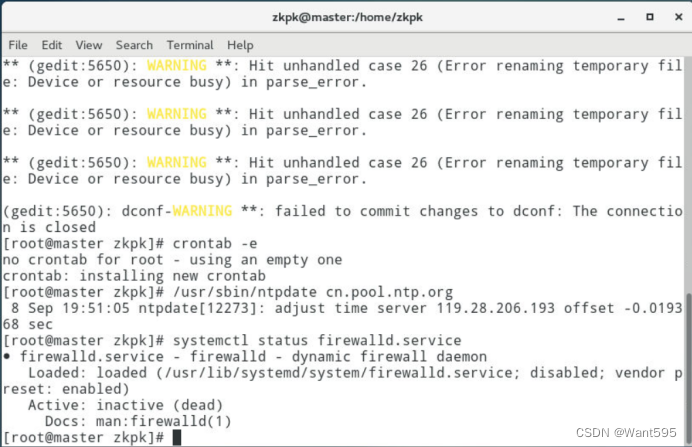
-
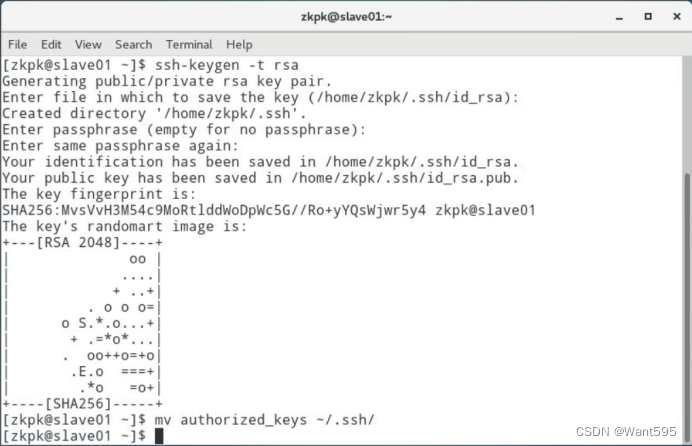
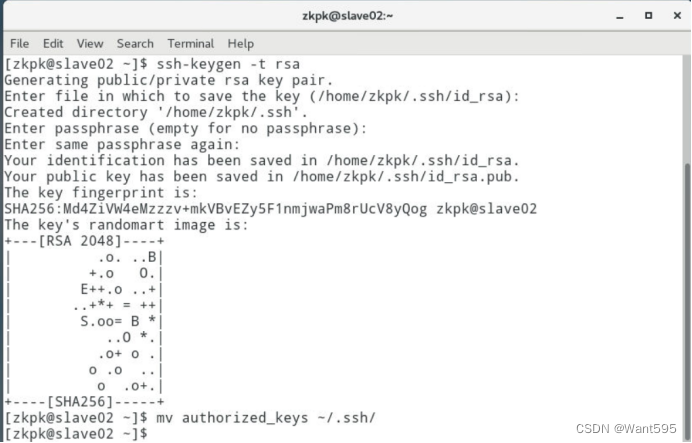
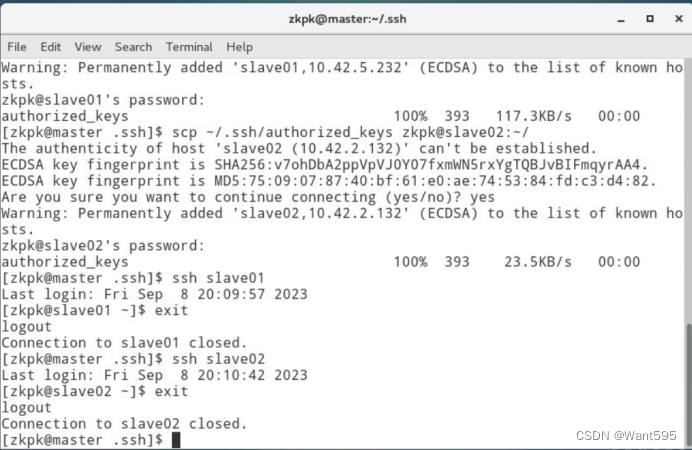
配置免密钥登录,在master机器上远程登录slave01或slave02。
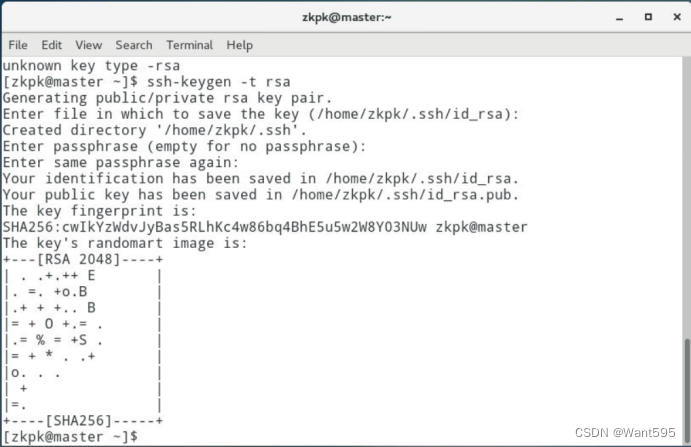
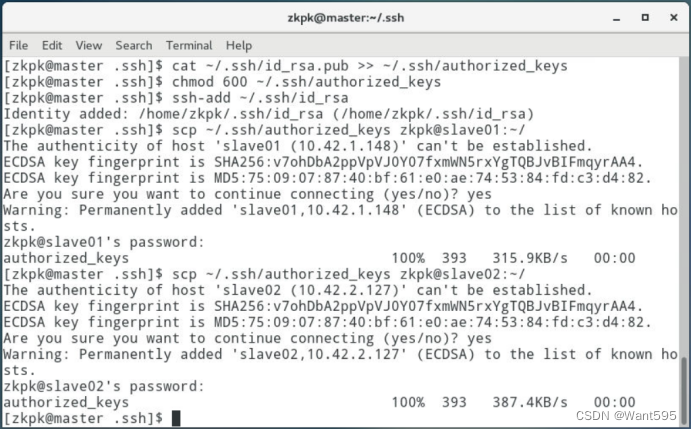
-
安装JDK。
- 6.1 切换root用户,移除系统自带的jdk
- 6.2 创建存放jdk文件目录,将/home/zkpk/tgz下的JDK压缩包解压到/usr/java目录下
- 6.3 配置zkpk用户环境变量
- 6.4 使环境变量生效
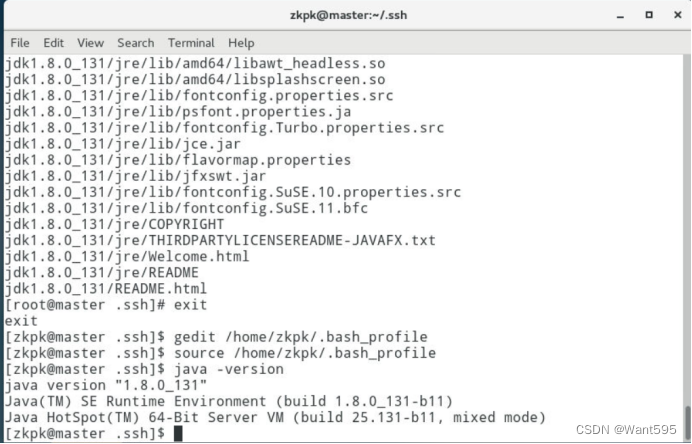
- 6.5 查看、测试java是否配置成功(创建一个用自己名字拼音命名的Java类,类名和文件内容自拟):
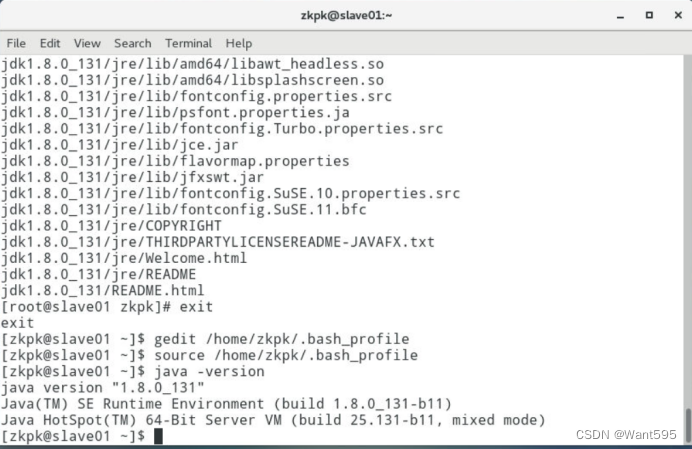
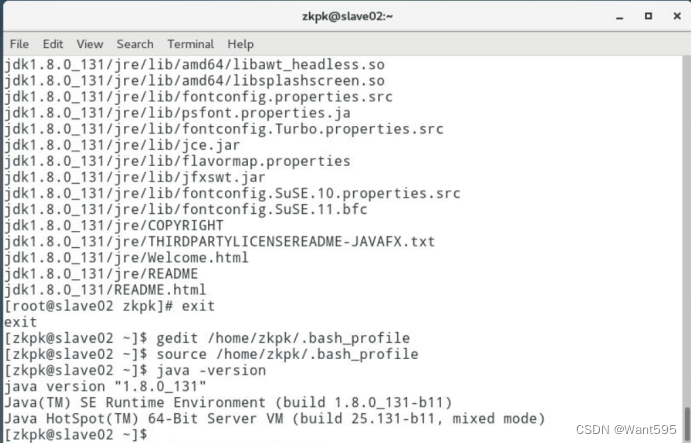
- 安装部署Hadoop集群。
说明:每个节点上的Hadoop配置基本相同,在master节点操作,然后复制到slave01、slave02两个节点。
-
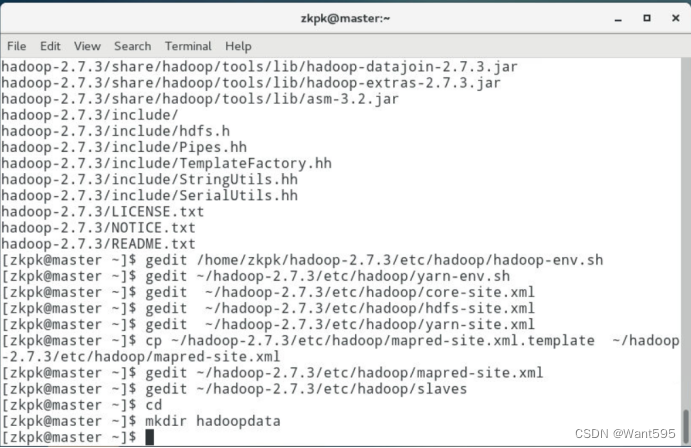
7.1 将/home/zkpk/tgz/hadoop目录下的Hadoop压缩包解压到/home/zkpk目录下
-
7.2 配置hadoop-env.sh文件使用gedit命令修改hadoop-env.sh文件修改JAVA_HOME环境变量
-
7.3 配置yarn-env.sh文件,使用gedit命令修改yarn-env.sh文件,修改JAVA_HOME环境变量
-
7.4 配置core-site.xml 文件,使用gedit命令修改core-site.xml文件
-
7.5 配置hdfs-site.xml文件使用gedit命令修改hdfs-site.xml文件
-
7.6 配置yarn-site.xml文件,使用gedit命令修改yarn-site.xml文件
-
7.7 配置mapred-site.xml文件,复制mapred-site-template.xml文件,使用gedit编辑mapred-site.xml文件
-
7.8 配置slaves文件,使用gedit编辑slaves文件
-
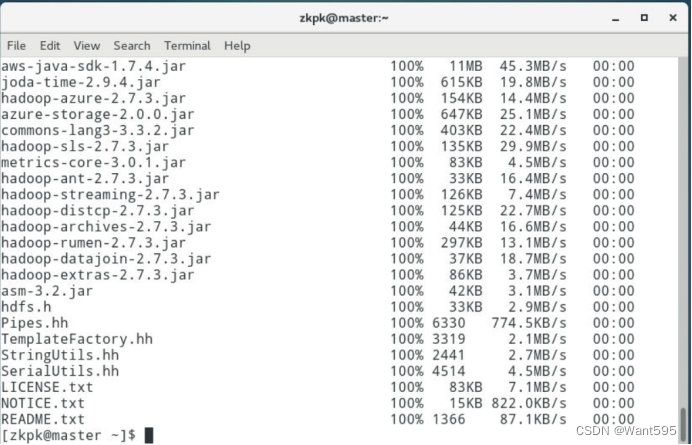
7.9 将配置好的hadoop文件夹复制到从节点,使用scp命令将文件夹复制到slave01、slave02上【说明:因为之前已经配置了免密钥登录,这里可以直接免密钥远程复制】
-
7.10 格式化hadoop环境变量,格式化hadoop文件目录

-
7.11 启动Hadoop集群(在master上执行)运行start-all.sh命令。【说明:格式化后首次执行此命令,提示输入yes/no时,输入yes】
-
7.12 查看进程是否启动,分别在master,slave01和slave02终端执行jps命令
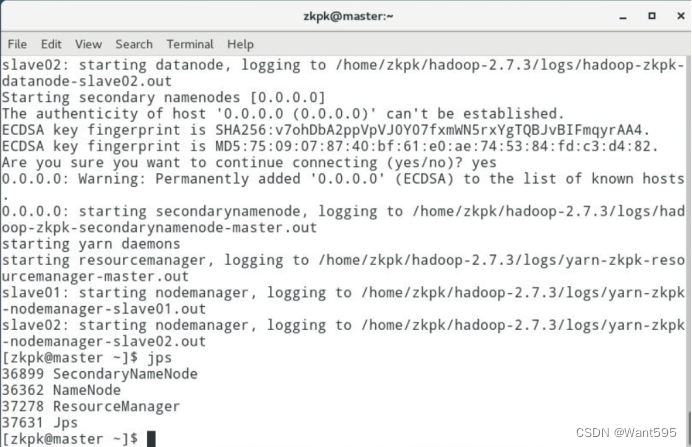
-
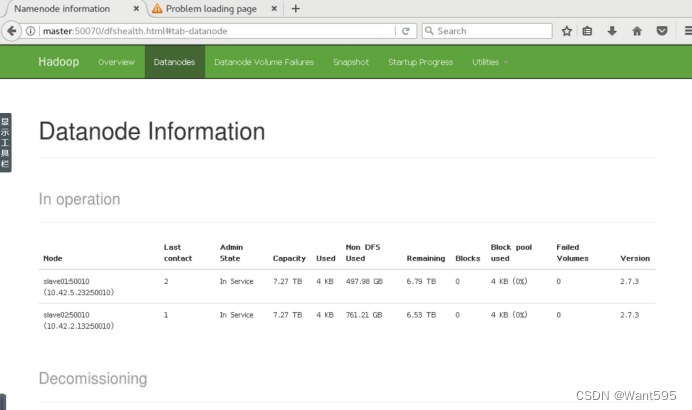
7.13 Web UI查看集群是否成功启动
(1)在master上打开Firefox浏览器,在浏览器地址栏中输入http://master:50070/,检查namenode 和datanode 是否正常
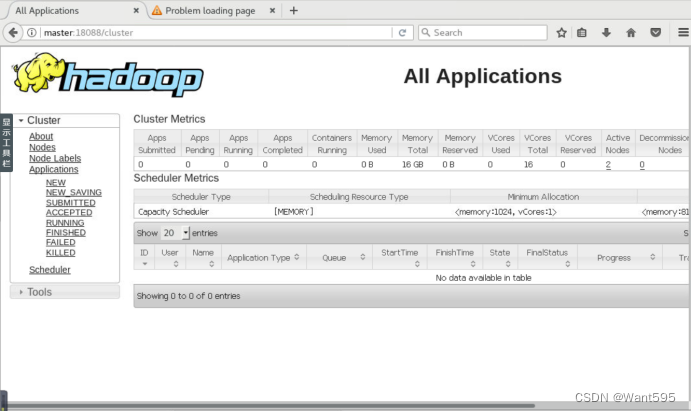
(2)打开浏览器新标签页,地址栏中输入http://master:18088/,检查Yarn是否正常
-
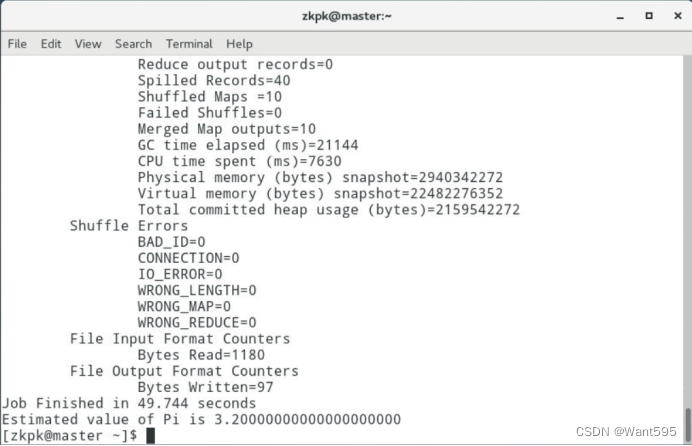
7.14 运行PI实例检查集群是否成功,最后输出:Estimated value of Pi is 3.20000000000000000000
附:系列文章
| 实验 | 文章目录 | 直达链接 |
|---|---|---|
| 实验01 | Hadoop安装部署 | https://want595.blog.csdn.net/article/details/132767284 |
| 实验02 | HDFS常用shell命令 | https://want595.blog.csdn.net/article/details/132863345 |
| 实验03 | Hadoop读取文件 | https://want595.blog.csdn.net/article/details/132912077 |
| 实验04 | HDFS文件创建与写入 | https://want595.blog.csdn.net/article/details/133168180 |
| 实验05 | HDFS目录与文件的创建删除与查询操作 | https://want595.blog.csdn.net/article/details/133168734 |