1、配置 hosts(1分)
编辑/etc/hosts文件,添加 主机名和IP 映射关系,如图:

注意:在虚拟机里面无法修改主机名,请仔细核对主机名,别写错!
# hostname //查看主机名
2、配置SSH免密登录(3分)
在其中一台主机上执行以下命令,我们以10.42.216.142为例:
# ssh-keygen -t rsa
![]()
三次回车,到如下界面,

#ssh-copy-id 10.42.216.142
密码是123456
10.42.216.142即IP地址,也可以写主机名.
完成上面的步骤后再执行
# scp -r /root/.ssh 10.42.143.205:/root

密码是123456
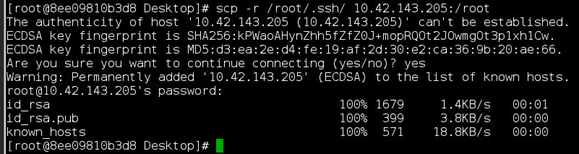
出现上面的截图,那么免密登录就配置好了!
3、安装配置JDK(1分)
任务二、配置Hadoop集群(安装包在 /opt/software目录下)
1、解压Hadoop安装包并修改配置文件(2分)
# tar -zxvf hadoop-2.7.2.tar.gz
# mv hadoop-2.7.2 /opt/hadoop #重命名并移动到/opt目录下
编辑core-site.xml,添加如下内容
<property>
<name>fs.defaultFS</name>
<value>hdfs://本机名或IP:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
</property>
编辑hdfs-site.xml,添加
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
编辑mapred-site.xml
# cp mapred-site.xml.template mapred-site.xml #复制一份
添加
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
编辑yarn-site.xml,添加
<property>
<name>yarn.resourcemanager.hostname</name>
<value>本机名或IP</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
编辑slaves,添加子节点的主机名或IP,
>vi slaves


编辑hadoop-env.sh,修改JAVA_HOME为本机实际的目录,如图

2、配置环境变量(在两台机器上都写一样的配置,如下)(1分)
# vi /etc/profile

# source /etc/profile #立即生效
3、拷贝hadoop到其他的机器上(1分)
命令如下
# scp -r /opt/hadoop 10.42.143.205:/opt
4、初始化hadoop集群(1分)
命令如下
# hadoop namenode -format
5、启动Hadoop集群(1分)
首先进入/opt/hadoop/sbin目录下,命令如下
#cd /opt/hadoop/sbin
#./start-dfs.sh
#./start-yarn.sh
验证启动结果:
# jps
如图

主节点Namenode、Resourcemanager

子节点Datanode、Nodemanager
任务二、配置HBase集群环境(5分)
1、HBase安装
我们在搭建好Hadoop集群之后就可以搭建HBase数据仓库了.在安装HBase之前检查Hadoop集群是否处于启动状态,如图

下面我们开始HBase的搭建
1、解压Hase、修改HBase的配置文件(3分)
进入/opt/software目录,找到HBase安装包并解压、重命名,命令如下
# cd /opt/software
# tar -zxvf hbase-1.4.3-bin.tar.gz
# mv hbase-1.4.3 /opt/hbase

A、进入/opt/hbase/conf目录下,修改hbase-env.sh和hbase-site.xml,命令如下,
# cd /opt/hbase/conf
# vi hbase-env.sh

去掉注释,并修改为我们自己的JAVA_HOME,

去掉前面的注释,OK,保存退出!
B、编辑hbase-site.xml文件,命令如下
# vi hbase-site.xml
添加如下几个属性值,
<property>
<name>hbase.rootdir</name>
<value>hdfs://本机名或IP:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>集群所有的主机名或IP,逗号隔开</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/hbase/zookeeper</value>
</property>
如图

C、配置环境变量(集群每台机器都要配置一下),命令如下
# vi /etc/profile

# source /etc/profile
D、编辑regionservers,添加子节点的主机名或者IP地址,如图

拷贝HBase到其他的机器上(1分)
A、我们将修改好的HBase安装包拷贝包子节点上,命令如下
# scp -r /opt/hbase 10.42.143.205:/opt

2、启动hbase集群(2分)
# cd /opt/hbase/bin
# ./start-hbase.sh
验证集群的启动情况
#jps

主节点 HMaster、HQuorumPeer

子节点HRegionServer、HQuorumPeer
任务三、配置Hive集群环境(5分)
- Hive是基于Hadoop的一个数据仓库工具,其运行依赖Hadoop和Mysql,其中Hadoop为其提供Hdfs文件系统,Mysql为其提供元数据存储。下面我们开始搭建Hive。
1、Mysql安装(2分)
-
- Mysql安装,命令如下
进入 /opt/software 目录下,解压Mysql安装包并重命名,
# tar –zxvf mysql-5.7.16-linux-glibc2.5-x86_64.tar.gz
# mv mysql-5.7.16 /opt/mysql //将重新命名后的mysql移动到/opt目录下
# mkdir -p /opt/mysql/data //mysql目录下生成data目录

b) # touch my.cnf //创建mycnf文件,里面添加内容如下:

# cp my.cnf /etc/ //覆盖/etc下原有的my.cnf
C) 初始化数据库
# /opt/mysql/bin/mysqld --initialize-insecure --basedir=/opt/mysql --datadir=/opt/mysql/data --user=root

# cp /opt/mysql/support-files/mysql.server /etc/init.d/mysql
//将mysql加入服务
# chkconfig mysql on
//设置mysql开机自启
# service mysql start
//启动mysql服务

D) 配置mysql环境变量
# vi /etc/profile //配置环境变量

# mysql -uroot -p //登录mysql,密码为空直接回车
# set password=password('ethink2018'); //在mysql登录进去后更改密码

# create database hive default charset utf8; //创建hive数据库
# grant all privileges on *.* to 'root'@'%' identified by 'ethink2018'; //赋权限
# flush privileges; //刷新权限

# exit //退出mysql
E)退出并重新登陆验证密码:

查看数据库

2、Hive搭建(2分)
A)解压安装包
#cd /opt/software/
#tar -zxvf apache-hive-2.2.0.tar.gz //解压hive软件
B)重命名,移动到/opt目录下
#mv apache-hive-2.2.0 /opt/hive

C).添加环境变量
#vi /etc/profile
导入下面的环境变量:
export HIVE_HOME=/opt/hive
export PATH=$PATH:$HIVE_HOME/bin

使其有效:
#source /etc/profile
D)、修改配置文件
根据环境部署的需求,修改主节点上的hive配置文件:hive-env.sh和hive-site.xml
,完成配置后,启动hive服务。
①修改hive-env.sh文件
# cd /opt/hive/conf/ //进入hive的conf目录
#cp hive-env.sh.template hive-env.sh //重新命名
#vi hive-env.sh //修改hadoop的安装目录
HADOOP_HOME=/opt/hadoop
![]()
②修改hive-site.xml文件
# cd /opt/hive/conf/ //进入hive的conf目录
# cp hive-default.xml.template hive-site.xml //重新命名
# vi hive-site.xml //编辑hive-site.xml
主要修改以下参数:
<property>
<name>javax.jdo.option.ConnectionURL </name>
<value>jdbc:mysql://主机ip:3306/hive?useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName </name>
<value>com.mysql.jdbc.Driver </value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword </name>
<value>ethink2018</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/opt/hive/iotmp</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/opt/hive/iotmp</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>






E).传输jar包
# scp -r /opt/hive 10.42.143.205:/opt //将hive传到子节点
# source /etc/profile //环境变量生效,子主节点都要执行
# cp -r /opt/software/mysql-connector-java-5.1.39-bin.jar /opt/hive/lib/
//将mysql jar包 拷贝到/hive/lib中
# cp -r /opt/hive/lib/jline-2.12.jar /opt/hadoop/share/hadoop/yarn/lib
//将jline包拷贝到hadoop中
3、启动测试hive(1分)
在hive/bin目录下执行:
# schematool -dbType mysql -initSchema //初始化元数据

启动hadoop后,执行hive命令
#hive
测试输入 show database;
hive> show databases;
OK
default
Time taken: 0.907 seconds, Fetched: 1 row(s)

任务五:大数据平台运维(10分)
参数优化化
在Hadoop集群环境里,完成以下参数的配置:
1:设置dfs权限打开true; (1分)
hdfs-site.xml文件
<property>
<name>dfs.permissions</name>
<value>true</value>
</property>
2:设置HDFS数据块的备份数为3;(1分)
hdfs-site.xml 文件
<property>
<name>dfs.replication</name>
<value>3</value>
<description></description>
</property>
3:设置数据块写入的最多重试次数5;(1分)
hdfs-site.xml 文件
<property>
<name>dfs.client.block.write.retries</name>
<value>5</value>
<description></description>
</property>
4:设置dfs最大并发对象数3;(1分)
hdfs-site.xml 文件
<property>
<name> dfs.max.objects</name>
<value>3</value>
<description></description>
</property>
5:设置DateNode启动的服务线程数3;(1分)
hdfs-site.xml 文件
<property>
<name> dfs.datanode.handler.count</name>
<value>3</value>
<description></description>
</property>