Java集合类源码分析
〇、说明
-
集合类特性
任何对象加入集合类后,自动转变为Object类型,所以在取出的时候,需要进行强制类型转换。
如果要用线程安全的集合类,首选Concurrent并发包下的对应的集合类。 -
如何看源码
(1)看继承结构
看这个类的层次结构,处于一个什么位置,可以在自己心里有个大概的了解。
(2)看构造方法
在构造方法中,看做了哪些事情,跟踪方法中里面的方法。
(3)看常用的方法
跟构造方法一样,这个方法实现功能是如何实现的
一、Object类
1. 继承结构
public class Object
2. 构造方法
@HotSpotIntrinsicCandidate,java 9 中引入的HotSpot高校实现代码方式。
// java 9 之前是没有显示地写出来
@HotSpotIntrinsicCandidate
public Object() {}
3. 常用方法和参数
native方法调用了很多jni.h、jvm.h中的native方法。
transient关键字的作用:让某些被修饰的成员属性变量不被序列化。
只要这个类实现了Serilizable接口,这个类的所有属性和方法都会自动序列化。例如敏感信息、可以通过计算得到的数据,可以不被序列化,达到安全和节省空间的作用。
equals()方法:默认和 == 相同
public boolean equals(Object obj) {
return (this == obj);
}
finalize()方法:从Java 9之后就被标记为过时的方法,Oracle建议用java.lang.ref.Cleaner来替代。
@Deprecated(since="9")
protected void finalize() throws Throwable { }
toString()方法:该类的对象的实例名和用16进制表示的该对象的地址(哈希码)
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
很多线程方法:notify、wait等。
5. native关键字
通过JNI(Java Native Interface)接口调用其他语言来实现对底层的访问。
使用native关键字说明这个方法是原生函数,也就是这个方法是用C/C++语言实现的,并且被编译成了DLL(动态链接库文件,不在JDK中),由Java去调用。
二、ArrayList类
0. 数据结构
该类封装了一个动态再分配的Object[]数组,每一个类对象都有一个capacity属性。
1. 继承结构
// ArrayList类
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
// AbstractList类
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E>
// AbstractCollection类
public abstract class AbstractCollection<E> implements Collection<E>
// Collection接口
public interface Collection<E> extends Iterable<E>
2. 构造方法
默认无参的构造方法initial capacity of ten,有参的构造方法参数可以是:
初始化容量大小、集合类(方法内判断是否为空)
3. 常用方法和属性
List被修改的次数:在使用迭代器遍历的时候,用来检查列表中的元素是否发生结构性变化(列表元素数量发生改变)了,主要在多线程环境下需要使用,防止一个线程正在迭代遍历,另一个线程修改了这个列表的结构。ConcurrentModificationException异常。
protected transient int modCount = 0;
扩容机制:扩大到原来的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
克隆方法:利用了Arrays中的copyOf()方法(toArray()方法也利用了该方法)。
ArrayList<?> v = (ArrayList<?>) super.clone();
v.elementData = Arrays.copyOf(elementData, size);
三、LinkedList类
0. 数据结构
底层使用的是双向链表,有一个头节点和尾节点
/**
* Pointer to first node.
*/
transient Node<E> first;
/**
* Pointer to last node.
*/
transient Node<E> last;
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
1. 继承结构
实现了Deque(接口)双端队列,具有队列和栈的性质的数据结构,一端允许插入和删除,另一端允许插入。官方也是推荐使用 Deque 的实现来替代 Stack。
// LinkedList类
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
// AbstractSequentialList类
public abstract class AbstractSequentialList<E> extends AbstractList<E>
// AbstractList类
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E>
2. 构造方法
public LinkedList() {
}
public LinkedList(Collection<? extends E> c) {
this(); // 调用无参构造函数
addAll(c); // 添加集合中所有的元素
}
3. 常用方法和属性
add()方法:添加到链表尾部
索引查找节点时的优化:结点在前半段则从头开始遍历,在后半段则从尾开始遍历。
addall()方法:
Object[] a = c.toArray();先将集合转换成数组,1) 如果直接遍历集合的话,那么在遍历过程中需要插入元素,在堆上分配内存空间,修改指针域,这个过程中就会一直占用着这个集合,考虑正确同步的话,其他线程只能一直等待。2.)如果转化为数组,只需要遍历集合toArray(),而遍历集合过程中不需要额外的操作,所以占用的时间相对是较短的,这样就利于其他线程尽快的使用这个集合。有利于提高多线程访问该集合的效率,尽可能短时间的阻塞。
remove()方法:会调用unlink()方法
四、 HashMap类
0. 数据结构
在JDK1.8之前,HashMap采用数组+链表实现,即使用链表处理冲突。但是当位于一个桶中的元素较多,通过key值依次查找的效率较低。而JDK1.8中,HashMap采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
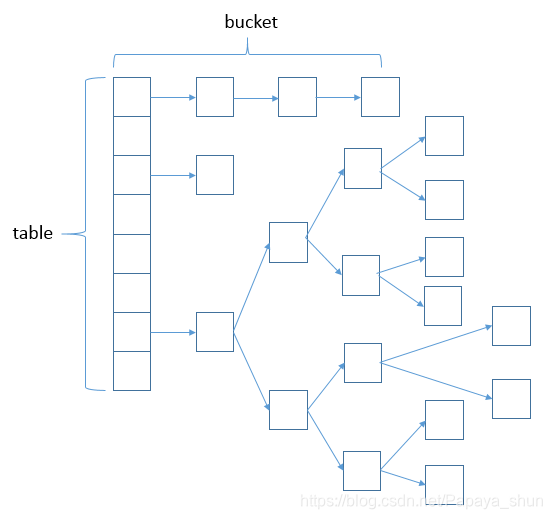
// 位桶
transient Node<k,v>[] table;// 存储(位桶)的数组
// Node是单向链表,它实现了Map.Entry接口
static class Node<k,v> implements Map.Entry<k,v>
// 红黑树
static final class TreeNode<k,v> extends LinkedHashMap.Entry<k,v>
1. 继承结构
// HashMap类
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
// AbstractMap类
public abstract class AbstractMap<K,V> implements Map<K,V>
// Map接口
public interface Map<K, V>
2. 构造方法
public HashMap(int initialCapacity, float loadFactor)
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR); // default: 0.75
}
public HashMap()
public HashMap(Map<? extends K, ? extends V> m)
3. 常用方法和参数
// 默认的初始容量是16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认的填充因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 当桶(bucket)上的结点数大于这个值时会转成红黑树
static final int TREEIFY_THRESHOLD = 8;
// 当桶(bucket)上的结点数小于这个值时树转链表
static final int UNTREEIFY_THRESHOLD = 6;
// 桶中结构转化为红黑树对应的table的最小大小
static final int MIN_TREEIFY_CAPACITY = 64;
// 每次扩容和更改map结构的计数器
transient int modCount;
// 临界值 当实际大小(容量*填充因子)超过临界值时,会进行扩容
int threshold;
// 填充因子
final float loadFactor;
hash()方法:将hashCode值右移16位,然后将右移后的值与原来的hashCode做异或运算。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
put()方法:调用putVal()方法,会进行多次扩容、修改数据结构的判断
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
resize()方法:
①.在jdk1.8中,resize方法是在hashmap中的键值对大于阀值时或者初始化时,就调用resize方法进行扩容;
②.每次扩展的时候,都是扩展2倍;
③.扩展后Node对象的位置要么在原位置,要么移动到原偏移量两倍的位置。
继承结构、构造方法、常用方法