github: https://github.com/containernetworking/plugins
对 K8S 集群中 Pod 的出入带宽进行限制,使用Token Bucket Filter(TBF)来限流的插件
1. cmdAdd 函数
得到 conf 配置从标准输入输出内容为:
- CNIVersion:\"0.3.0\"
- Name:\"k8s-pod-network\"
- Type:\"bandwidth\", Capabilities:map[string]bool{\"bandwidth\":true}
func cmdAdd(args *skel.CmdArgs) error {
conf, err := parseConfig(args.StdinData)
if err != nil {
return err
}1.1 结构体 PluginConf
type PluginConf struct { types.NetConf RuntimeConfig struct { Bandwidth *BandwidthEntry `json:"bandwidth,omitempty"` } `json:"runtimeConfig,omitempty"` *BandwidthEntry }
1.2 getHostInterface 函数
sandbox 为空的 host interface,如果存在vetp peer ,则验证查找成功
func getHostInterface(interfaces []*current.Interface) (*current.Interface, error) {
if len(interfaces) == 0 {
return nil, errors.New("no interfaces provided")
}
var err error
for _, iface := range interfaces {
if iface.Sandbox == "" { // host interface
_, _, err = ip.GetVethPeerIfindex(iface.Name)
if err == nil {
return iface, err
}
}
}
return nil, errors.New(fmt.Sprintf("no host interface found. last error: %s", err))
}1.3 如果指标都大于 0 则调用函数创建
qdisc tbf 1: dev calif779b875532 root refcnt 2 rate 50000bit burst 1073740b lat 4123.2s
qdisc ingress ffff: dev calif779b875532 parent ffff:fff1 ----------------
qdisc tbf 1: dev c9fe root refcnt 2 rate 80000bit burst 2491080b lat 824.7s
if bandwidth.IngressRate > 0 && bandwidth.IngressBurst > 0 {
err = CreateIngressQdisc(bandwidth.IngressRate, bandwidth.IngressBurst, hostInterface.Name)
if err != nil {
return err
}
}1.3.1 createTBF 函数
func createTBF(rateInBits, burstInBits, linkIndex int) error {
// Equivalent to
// tc qdisc add dev link root tbf
// rate netConf.BandwidthLimits.Rate
// burst netConf.BandwidthLimits.Burst
if rateInBits <= 0 {
return fmt.Errorf("invalid rate: %d", rateInBits)
}
if burstInBits <= 0 {
return fmt.Errorf("invalid burst: %d", burstInBits)
}1.3.2 调用 netlink.QdiscAdd 命令创建 tbf 令牌桶过滤器
参见后面 tfb 内容
rateInBytes := rateInBits / 8
burstInBytes := burstInBits / 8
bufferInBytes := buffer(uint64(rateInBytes), uint32(burstInBytes))
latency := latencyInUsec(latencyInMillis)
limitInBytes := limit(uint64(rateInBytes), latency, uint32(burstInBytes))
qdisc := &netlink.Tbf{
QdiscAttrs: netlink.QdiscAttrs{
LinkIndex: linkIndex,
Handle: netlink.MakeHandle(1, 0),
Parent: netlink.HANDLE_ROOT,
},
Limit: uint32(limitInBytes),
Rate: uint64(rateInBytes),
Buffer: uint32(bufferInBytes),
}
err := netlink.QdiscAdd(qdisc)
if err != nil {
return fmt.Errorf("create qdisc: %s", err)
}1.3.3 创建 ifb 类型的接口
func CreateIfb(ifbDeviceName string, mtu int) error {
err := netlink.LinkAdd(&netlink.Ifb{
LinkAttrs: netlink.LinkAttrs{
Name: ifbDeviceName,
Flags: net.FlagUp,
MTU: mtu,
},
})
if err != nil {
return fmt.Errorf("adding link: %s", err)
}
return nil
}bug:
https://github.com/kubernetes/kubernetes/pull/76584 (单位少 1000 倍)
calico 配置
{
"name": "k8s-pod-network",
"cniVersion": "0.3.0",
"plugins": [
{
"type": "calico",
"log_level": "info",
"datastore_type": "kubernetes",
"nodename": "master-node",
"mtu": 1440,
"ipam": {
"type": "calico-ipam"
},
"policy": {
"type": "k8s"
},
"kubernetes": {
"kubeconfig": "/etc/cni/net.d/calico-kubeconfig"
}
},
{
"type": "portmap",
"snat": true,
"capabilities": {"portMappings": true}
},
{ "type": "bandwidth", "capabilities": { "bandwidth": true } }
]
}
TC原理介绍
流量控制器TC(Traffic Control)用于Linux内核的流量控制,利用队列规定建立处理数据包的队列,并定义队列中的数据包被发送的方式, 从而实现对流量的控制。
TC模块实现流量控制功能使用的队列规定分为两类,一类是无类队列规定, 另一类是分类队列规定。
- 无类队列规定是对进入网络设备(网卡) 的数据流不加区分统一对待。使用无类队列规定形成的队列能够接受数据包以及重新编排、延迟或丢弃数据包。可以对整个网络设备( 网卡) 的流量进行整形。常用的无类队列规定主要有 pfifo _fast (先进现出) 、TBF ( 令牌桶过滤器) 、SFQ(随机公平队列) 、ID (前向随机丢包)等等。这类队列规定使用的流量整形手段主要是排序、 限速和丢包。
- 分类队列规定是对进入网络设备的数据包根据不同的需求以分类的方式。 数据包进入一个分类的队列后, 需要对数据包做分类处理。对数据包进行分类的工具是过滤器,过滤器会返回一个决定,队列规定就根据这个决定把数据包送入相应的类进行排队。每个子类都可以再次使用它们的过滤器进行进一步的分类。直到不需要进一步分类时, 数据包才进入该类包含的队列排队。 除了能够包含其它队列规定之外, 绝大多数分类的队列规定还能够对流量进行整形。 这对于需要同时进行调度( 如使用 S F Q ) 和流量控制的场合非常有用。
流量控制包括以下几种方式:
SHAPING(限制)
当流量被限制,它的传输速率就被控制在某个值以下。限制值可以大大小于有效带宽,这样可以平滑突发数据流量,使网络更为稳定。shaping(限制)只适用于向外的流量。SCHEDULING(调度)
通过调度数据包的传输,可以在带宽范围内,按照优先级分配带宽。SCHEDULING(调度)也只适于向外的流量。POLICING(策略)
SHAPING用于处理向外的流量,而POLICIING(策略)用于处理接收到的数据。DROPPING(丢弃)
如果流量超过某个设定的带宽,就丢弃数据包,不管是向内还是向外。
流量控制处理对象
流量的处理由三种对象控制,它们是:qdisc(排队规则)、class(类别)和filter(过滤器)。
QDISC(排队规则) queueing discipline的简写,它是理解流量控制(traffic control)的基础。内核如果需要通过某个网络接口发送数据包,都需要按照为这个接口配置的qdisc(排队规则)把数据包加入队列。然后内核尽可能多地从qdisc里面取数据包,把它们交给网络适配器驱动模块。最简单的QDisc是pfifo它不对进入的数据包做任何的处理,数据包采用先入先出的方式通过队列。
引入图片
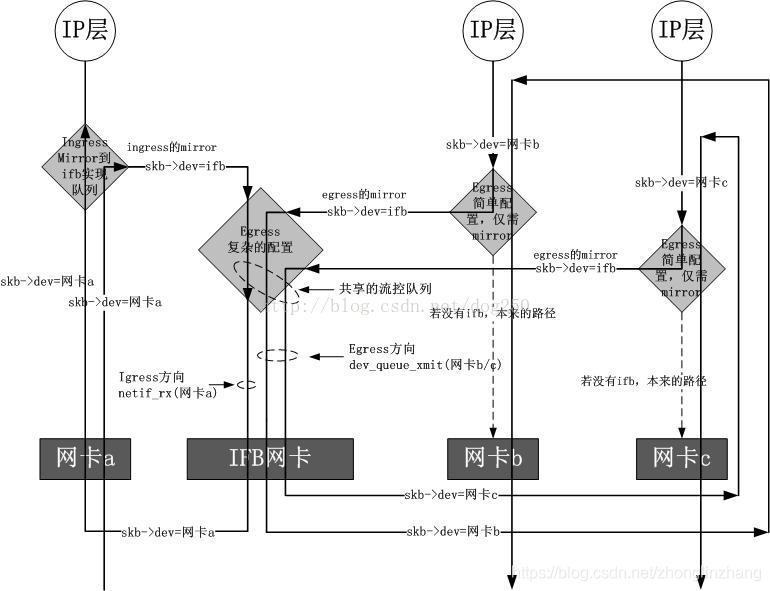
ifb驱动模拟一块虚拟网卡,它可以被看作是一个只有TC过滤功能的虚拟网卡,说它只有过滤功能,是因为它并不改变数据包的方向,即对于往外发的数据包被重定向到ifb之后,经过ifb的TC过滤之后,依然是通过重定向之前的网卡发出去,对于一个网卡接收的数据包,被重定向到ifb之后,经过ifb的TC 过滤之后,依然被重定向之前的网卡继续进行接收处理,不管是从一块网卡发送数据包还是从一块网卡接收数据包,重定向到ifb之后,都要经过一个经由ifb 虚拟网卡的dev_queue_xmit操作
1.pfifo_fast
先进先出(FIFO),没有任何数据包被特殊处理。这个队列有3个所谓的“频道”(band)。FIFO规则应用于每一个频道。并且:如果在0频道有数据包等待发送,1频道的包就不会被处理,1频道和2频道之间的关系也是如此。
内核遵照数据包的TOS标记,把带有“最小延迟”标记的包放进0频道。
*参数与使用*
pfifo_fast队列规则作为硬性的缺省设置,不能对它进行配置。
2.令牌桶过滤器(TBF)
令牌桶过滤器(TBF,Token Bucket Filter)是一个简单的队列规则:只允许以不超过事先设定的速率到来的数据包通过,但可能允许短暂突发流量超过设定值。
TBF很精确,对于网络和处理器的影响都很小。所以如果您想对一个网卡限速,它应该是最好选择!
TBF的实现在于一个缓冲器(桶),缓冲器(桶)被一些叫做”令牌”的虚拟数据以特定速率(token rate)填充着。能够存储令牌的数量。
每个到来的令牌从数据队列中收集一个数据包,然后从桶中被删除。这个算法关联到两个流上-令牌流和数据流,于是我们得到3种情景:
*数据流以等于令牌流的速率到达TBF。这种情况下,每个到来的数据包都能对应一个令牌,然后无延迟地通过队列。
*数据流以小于令牌流的速度到达TBF。通过队列的数据包只消耗了一部分令牌,剩下的令牌会在桶里积累下来,直到桶被装满。剩下的令牌可以在需要以高于令牌流速率发送数据流的时候消耗掉,这种情况下会发生突发传输。
*数据流以大于令牌流的速率到达TBF。这意味着桶里的令牌很快就会被耗尽。导致TBF中断一段时间,称为”越限”(overlimit)。如果数据包持续到来,将发生丢包。
第三种情景非常重要,因为它会对数据通过过滤器的速率进行整形。令牌的积累可以导致越限的数据进行短时间的突发传输而不必丢包,但是持续越限的话会导致传输延迟直至丢包。实际的实现是针对数据的字节数进行的,而不是针对数据包进行的。
*参数与使用*
TBF提供了一些可调控的参数。第一个参数永远可用:
limit/latency
limit确定最多有多少数据(字节数)在队列中等待令牌。你也可以通过设置latency来指定这个参数,latency参数确定了一个包在TBF中等待传输的最长等待时间。两者计算决定桶的大小、速率和峰值速率。
burst/buffer/maxburst
桶的大小,以字节计。这个参数指定了最多可以有多少个令牌能够即刻被使用。通常,管理的带宽越大,需要的缓冲器就越大。在Intel体系上,10Mbit/s的速率需要至少10k字节的缓冲区才能达到期望的速率。
如果你的缓冲区太小,就会导致到达的令牌没有地方放(桶满了),这会导致潜在的丢包。
MPU
一个零长度的包并不是不耗费带宽。比如以太网,数据帧不会小于64字节。MPU(Minimum Packet Unit,最小分组单元)决定了令牌的最低消耗。
rate
速度操纵杆。参见上面的limit。
如果桶里存在令牌而且允许没有令牌,相当于不限制速率(缺省情况)。如果不希望这样,可以调入以下参数:
peakrate(峰值速率)
如果有可用的令牌,数据包一旦到来就会立刻被发送出去,就像光速一样。那可能并不是你希望的,特别是你有一个比较大的桶的时候。
峰值速率可以用来指定令牌以多快的速度被删除。用书面语言来说,就是:释放一个数据包,然后等待足够的时间后再释放下一个。我们通过计算等待时间来控制峰值速率。例如:UNIX定时器的分辨率是10毫秒,如果平均包长10kb,我们的峰值速率被限制在了1Mbps。
MTU(Maximum Transmission Unit, 最大传输单元)/minburst
但是如果你的常规速率比较高,1Mbps的峰值速率就需要调整。要实现更高的峰值速率,可以在一个时钟周期内发送多个数据包。最有效的办法就是:再创建一个令牌桶!这第二个令牌桶缺省情况下为一个单个的数据包,并非一个真正的桶。
要计算峰值速率,用MTU乘以100就行了。(应该说是乘以HZ数,Intel体系上是100,Alpha体系上是1024)
*配置范例*
这是一个非常简单而实用的例子:
# tc qdisc add dev ppp0 root tbf rate 220kbit latency 50ms burst 1540
为什么它很实用呢?如果你有一个队列较长的网络设备,比如DSL modem或者cable modem什么的,并通过一个快速设备(如以太网卡)与之相连,你会发现上传数据会破坏交互性。
这是因为上传数据会充满modem的队列,而这个队列为了改善上载数据的吞吐量而设置的特别大。你可能为了提高交互性只需要一个不太大的队列,也就是说你希望在发送数据的时候干点其他的事情。
上面的命令行并非直接影响了modem中的队列,而是通过控制Linux中的队列而放慢了发送数据的速度。
把220kbit修改为你实际的上载速度再减去几个百分点。如果你的modem确实很快,就把“burst”值提高一点。