|
|
|
|
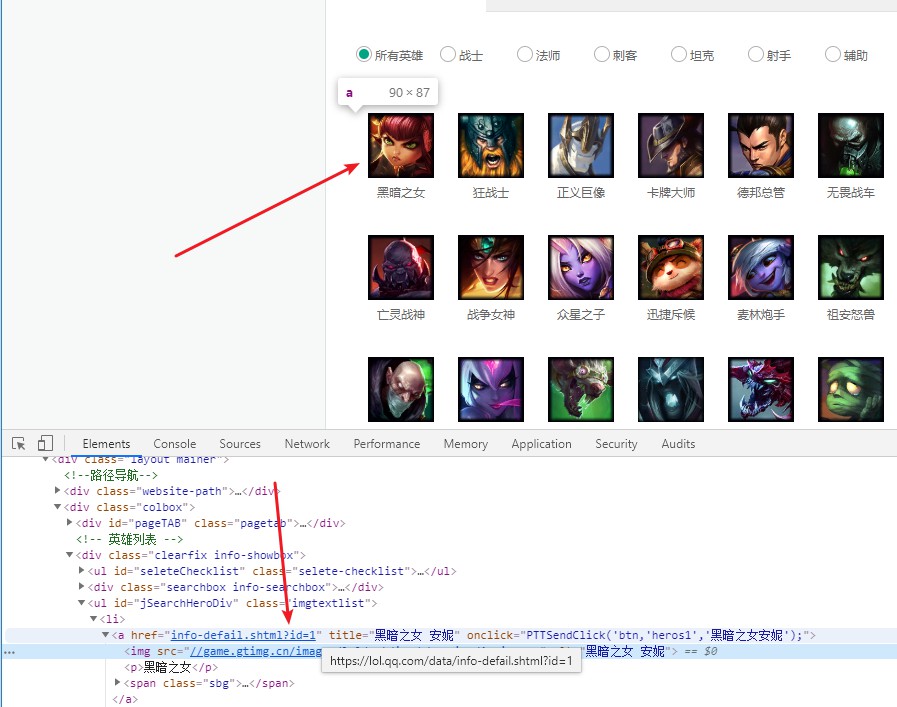
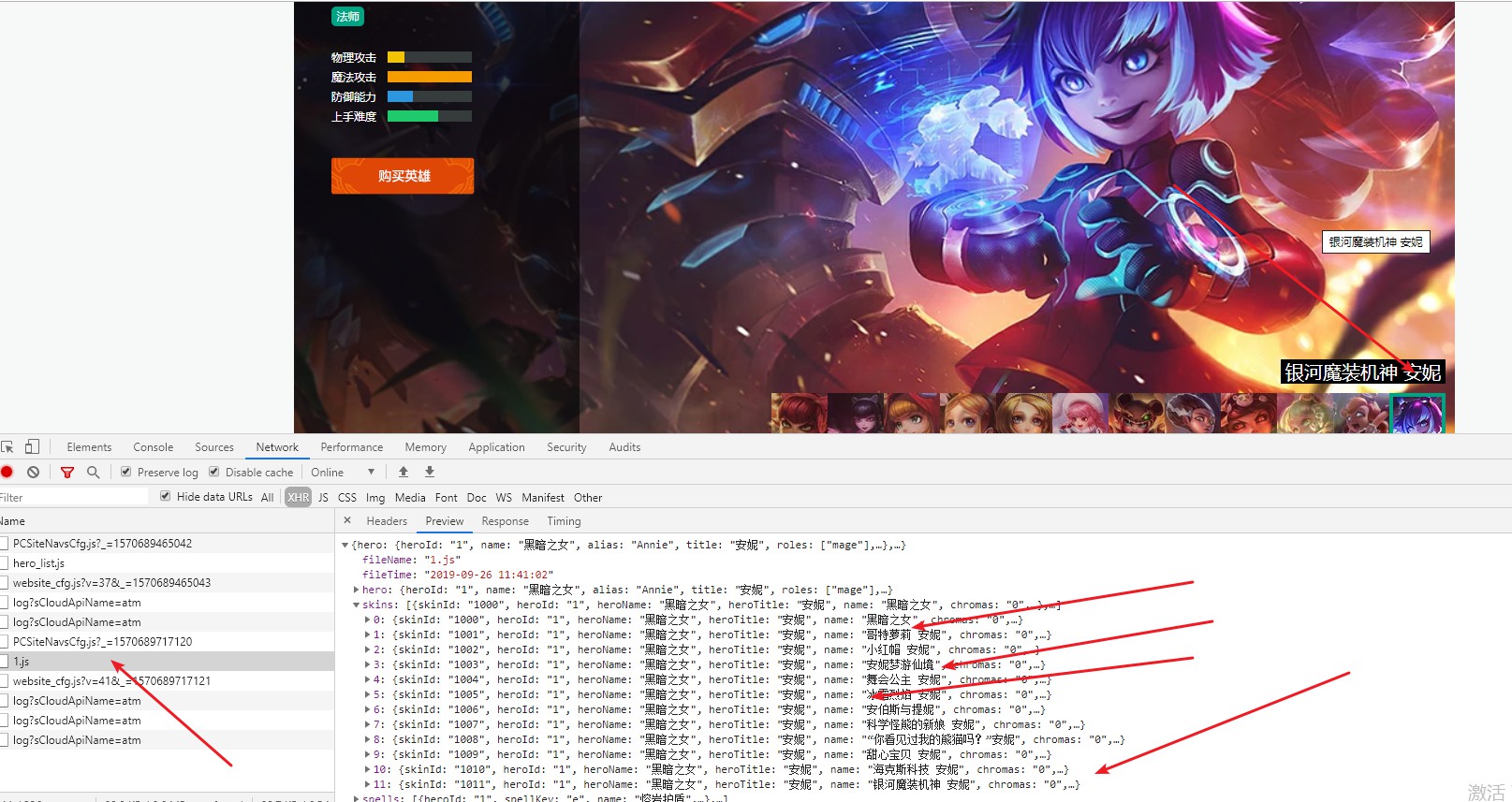
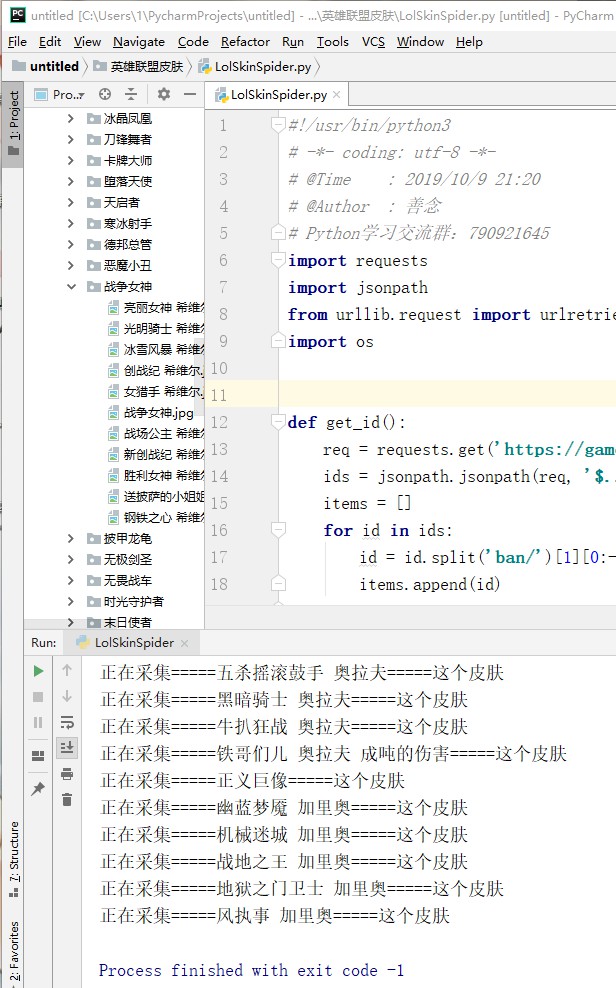
打造最全皮肤,Python采集英雄联盟(LOL)官...


猜你喜欢
转载自www.cnblogs.com/heimaguangzhou/p/11736255.html
今日推荐
周排行