1.1SVM模型
和感知机模型一样,SVM(支持向量机模型)也是旨在求出n维空间的最优超平面将正负类分开。这里的达到的最优是指在两类样本点距离超平面的最近距离达到最大,间隔最大使得它区别于感知机学习,SVM中还有核技巧,这样SVM就是实际上的非线性分类器函数。
1.2线性可分支持向量机
跟前面定义的问题一样,假设给定一个特征空间上的训练数据集
1.2.1函数间隔和几何间隔
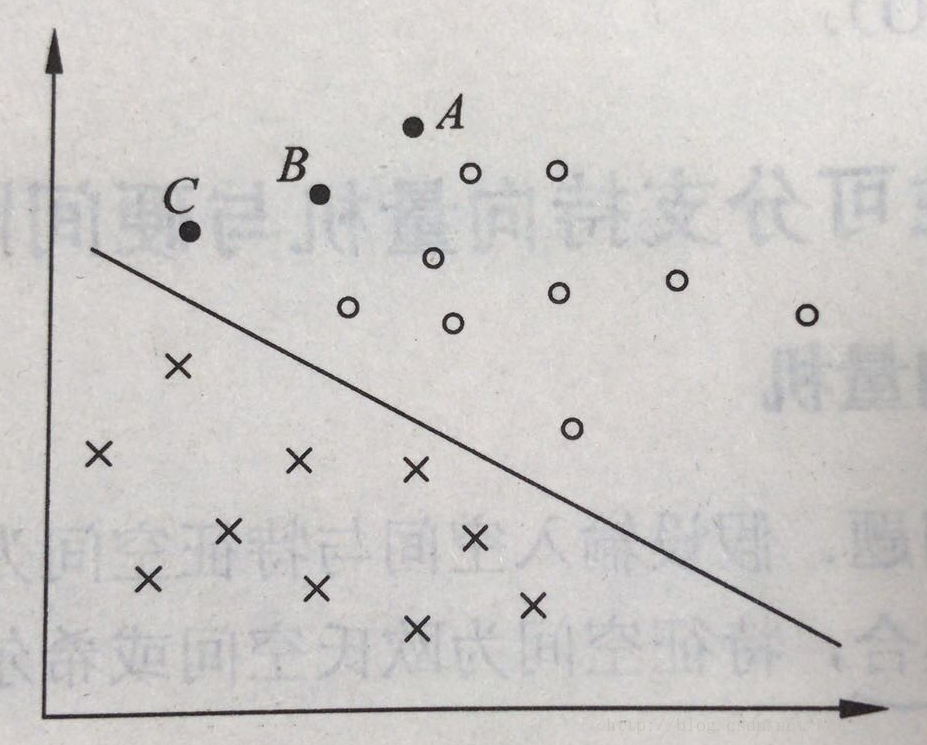
上图中有A,B,C三个点,其中A点离超平面较远,将其决策为正类的确信度比较高,C点预测为正类的置信度就不是很高,相同的,B位于A,C之间,所以将其预测为正类的置信度也在点A和点C之间。一般来说,一个点距离超平面的远近决定了其分类结果的置信度,所以最优的平面即为离超平面最近的样本点到其的距离最大的时候。
给定样本点(xi,yixi,yi为几何间隔,为了便于求得最优解,我们通常通过缩放变换使得函数间隔为1。所以SVM求解的目标函数为函数间隔为1情况下的几何间隔。
1.2.2 SVM学习算法
支持向量机的目的在于求得最优的即几何间隔最大的超平面,在样本数据是线性可分的时候,这里的间隔最大化又叫硬间隔最大化(训练数据近似可分的话就叫软间隔)
支持向量机的学习算法可以表示为下面的约束最优化问题:
这就是支持向量机的目标函数,这是一个 凸二次规划问题,所以支持向量机的学习算法又叫 最大间隔法。那么该如何求得在约束条件下最优的超平面的参数(w,b)呢?
1.2.3 SVM对偶算法
SVM通过对其对偶问题的求解求得最优的超平面参数(w,b),对于目标函数(12),目标函数是二次的,约束条件是线性的,是一个标准的QP问题,但是可以通过拉格朗日对偶性求得对偶问题的最优解,一者,这样更高效,二者还可以自然引入核函数,推广到非线性的分类问题。
首先构建拉格朗日函数,对每一个约束条件引进拉格朗日乘子αi≥0,i=1,2,3,⋯,Nαi≥0,i=1,2,3,⋯,N,直观解释就是最大值中最小的总比最小值中的最大值要大,在满足某些条件的时候,两者相等,这里的条件即为KKT条件。
将公式(4)后面括号展开,就得到
带入公式5,得: