版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
DayDay up目录
- Python序列之列表(2019年10月6日)——第二周
- 引入
- Python序列分类
- 列表的定义
- 列表创建与转换
- 列表的索引
- del 命令
- 垃圾回收
- 列表常用方法
- append(),insert(),extend()
- + 与 * 运算符增加元素
- pop(),remove(),clear()
- count(),index()
- 列表对象方法:sort(),reverse()
- 内置函数:sorted(),reversed()
- 内置函数对列表的操作
- range(),max(),min(),sum(),len(),zip(),enumerate()
- map(),lambda,[ item for item in ..]
- filter()
- reduce()
- 列表推导式 `要理解执行顺序与嵌套关系`
- 列表切片
- `复习强调`
- `易混`
- 声明
Python序列之列表(2019年10月6日)——第二周
引入
- 合抱之木,生于毫末;九层之台,起于累土;千里之行,始于足下。
- 且夫水之积也不厚,则其负大舟也无力。
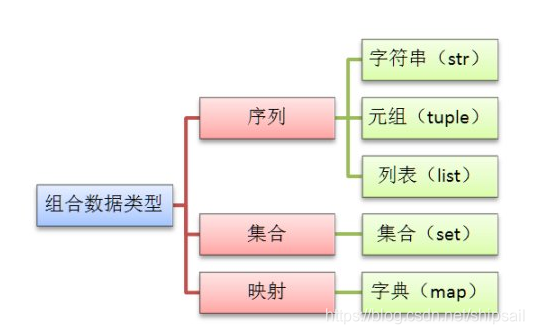
Python序列分类
列表的定义
- 包含若干元素的
有序连续内存空间 增,删时自动进行内存的扩展或收缩,从而保证元素之间没有空隙非尾部元素删除导致大量元素移动,效率较低。尽量从尾部删除元素。- 同一个列表中的元素
数据类型可各不相同,python内存管理基于值,变量储存的是引用,列表中储存的也是数据的引用。
列表创建与转换
a_list = [1,2,3,4]
a_list = [] # 创建空的列表
a_lsit = list() # 创建空的列表
a_list = list((1,2,3,4)) # 元组转列表
[1,2,3,4]
a_list = list(range(1,10,2)) # range对象转列表
[1,3,5,7,9]
a_list = list('hello,world') # 字符串转列表
['h','e','l','l','0',',','w','o','r','l','d']
a_list = list({1,3,5}) # 集合转列表
[1,3,5]
a_map = {'a':1,'b':2,'c':3}
a_list = list(a_map) # 将字典的键转为列表
['a','b','c']
a_list = list(a_map.items) # 将字典的元素(以元组为单位)转为列表
[('a',1),('b',2),('c',3)]
小知识:
list()这类函数被称为“工厂函数”,还学学到tuple(),set(),dict()。
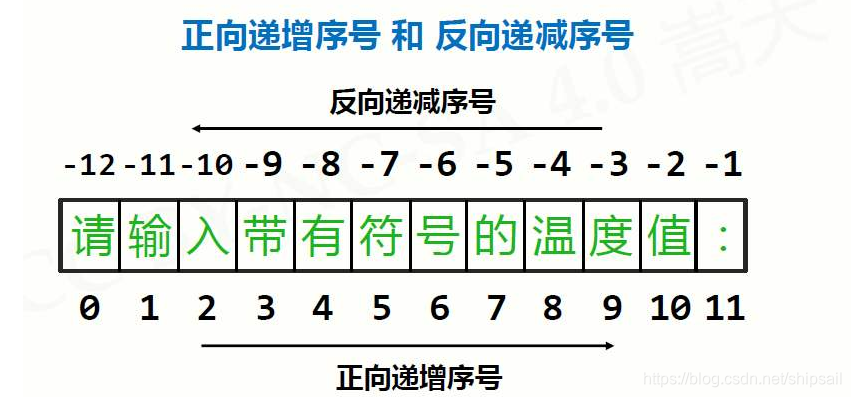
列表的索引
- 从0开始,表示第一个元素
- 支持
负整数作为下标,其中 -1 表示最后一个元素,以此类推
del 命令
当一个列表不再使用,可以用del命令将其删除,这适用于Python所有对象。
此外,del 命令还可以用于删除可变序列中的部分元素,而不能删除元组、字符串等不可变序列中的部分元素。
垃圾回收
一般来说,使用del删除对象之后,Python会在恰当的时机调用垃圾回收机制释放内存,有必要的时候我们也可以导入Python标准库 gc ,之后调用 gc.collect() 函数立刻启动垃圾回收机制。
列表常用方法
| 方 法 | 说 明 |
|---|---|
| lst.append(x) | 在尾部添加一个元素 |
| lst.insert(index,x) | 在index位置插入一个元素 |
| lst.extend(List) | 在尾部合并List列表中的元素 |
| lst.remove(x) | 移除从左到右第一个值为x的元素 |
| lst.pop(index) | 删除并返回下标为index的元素,默认为-1即最后一个元素 |
| lst.clear() | 清空 |
| lst.index(x) | 返回值为x的下标 |
| lst.count(x) | 返回值为x的个数 |
| lst.reverse() | 逆序 |
| lst.sort() | 排序 |
| lst.copy() | 返回浅复制 |
append(),insert(),extend()
此三个方法都属于
原地操作,不影响列表对象在内存中的起始地址
x = [1,2,3]
id(x) #50159368
x.append(4) #[1,2,3,4]
x.insert(0,3) #[3,1,2,3,4]
x.extend([5,6,7]) #[3,1,2,3,4,5,6,7]
id(x) #50159368
+ 与 * 运算符增加元素
此方法属于
新建列表,返回一个新的列表地址
x = [1,2,3]
id(x) # 50232456
x = x + [4] # 连接两个列表 [1,2,3,4]
id(x) # 50159368
x = x * 2 # 列表元素重复 [1,2,3,4,1,2,3,4]
id(x)q # 50226952
pop(),remove(),clear()
此三个方法都属于
原地操作,不影响列表对象在内存中的起始地址
要避免在列表中间插入删除元素,这会导致大量元素的移动
count(),index()
count()用于返回列表中指定元素出现的次数
index()用于返回元素在列表中首次出现的位置,若没有这个元素则抛出异常
此外成员测试运算符 in 也可以测试列表中是否有该元素
列表对象方法:sort(),reverse()
此方法都属于
原地操作,不影响列表对象在内存中的起始地址
sort()用来排序列表(默认是直接比较元素的大小)
reverse()用来逆序列表
内置函数:sorted(),reversed()
此方法返回
新的列表,功能与sort reverse相同
gameresult = [['Bob',95.0,'A'],
['Alan',86.0,'C'],
['Mandy',83.5,'A'],
['Rob',89.3,'E']]
from operator import itemgetter
list1 = sorted(gameresult,key = itemgetter(2)) # 按子列表第三个元素升序
list2 = sorted(gameresult,key = itemgetter(2,0)) # 按子列表第三个元素升序,后按第一个元素升序
list3 = sorted(gameresult,key = itemgetter(2,0),reverse = True) # 按子列表第三个元素降序,后按第一个元素降序
list4 = ["what","i'm","sorting","by"]
list5 = ["something","else","to","sort"]
pairs = zip(list4 ,list5)
[item[1] for item in sorted(pairs,key=lambda x:x[0],reverse=True)]
['something','to','sort','else']
# Lambda 表达式在后续会学习中会提到,这句语句的实质为for循环的简写
x = [[1,2,3],[2,1,4],[2,2,1]]
sorted(x,key=lambda item:(item[1],-item[2])) # 第二个元素升序,第三个降序
[[2,1,4],[1,2,3],[2,2,1]]
x = ['aaaa','bb','d','b','ba']
sorted(x,key = lambda item:(len(item),item)) # 按字符串长度升序,再按字符串升序
['b','d','ba','bc','aaaa']
内置函数对列表的操作
range(),max(),min(),sum(),len(),zip(),enumerate()
>>> x = list(range(10))
>>> x
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> import random
>>> random.shuffle(x) # 随机打乱
>>> x
[1, 4, 7, 2, 6, 0, 9, 5, 8, 3]
>>> max(x) # max(x,key = str) 可按指定规则找最大值
9
>>> min(x)
0
>>> sum(x)
45
>>> len(x)
10
>>> list(zip(x,[1]*10))
[(1, 1), (4, 1), (7, 1), (2, 1), (6, 1), (0, 1), (9, 1), (5, 1), (8, 1), (3, 1)]
>>> list(zip(range(1,10)))
[(1,), (2,), (3,), (4,), (5,), (6,), (7,), (8,), (9,)]
>>> enumerate(x)
<enumerate object at 0x0000022ECB05C558>
>>> list(enumerate(x))
[(0, 1), (1, 4), (2, 7), (3, 2), (4, 6), (5, 0), (6, 9), (7, 5), (8, 8), (9, 3)]
map(),lambda,[ item for item in …]
C:\Users\zhangchi>python
Python 3.7.0 (default, Jun 28 2018, 08:04:48) [MSC v.1912 64 bit (AMD64)] :: Anaconda, Inc. on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> list(map(str,range(5)))
['0', '1', '2', '3', '4']
>>> def add5(v):
... return v+5
...
>>> list(map(add5,range(10))) # 单参数
[5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
>>> def add(a,b):
... return a+b
...
>>> list(map(add,range(5),range(5,10))) #双参数
[5, 7, 9, 11, 13]
>>> list(map(add,range(5),range(5,100))) # 使用范围小的参数
[5, 7, 9, 11, 13]
>>> list(map(lambda x,y:x+y,range(5),range(5))) # lambda 表达式实现
[0, 2, 4, 6, 8]
>>> list(map(lambda x,y:x+y,range(5),range(50))) # 使用范围小的参数
[0, 2, 4, 6, 8]
>>> [add(x,y) for x,y in zip(range(5),range(5,10))] # 简易for循环实现
[5, 7, 9, 11, 13]
>>>
filter()
reduce()
列表推导式 要理解执行顺序与嵌套关系
列表推导式在逻辑上相当于一个循环,只是形式更加的简洁
例一
>>> aList = [x*x for x in range(10)]
>>> aList
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
等价于
>>> aList = []
>>> for x in range(10):
... aList.append(x*x)
...
>>> aList
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
等价于
>>> aList = list(map(lambda x:x*x,range(10)))
>>> aList
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
例二
food = ['banana','loganberry','passion fruit']
aList = [w.strip() for w in food]
等价于
Alist = []
food = ['banana','loganberry','passion fruit']
for item in food:
Alist.append(item.strip())
等价于
food = ['banana','loganberry','passion fruit']
Alist = list(map(str.strip(),food))
等比数列和
sum_ = sum([2**i for i in range(64)])
嵌套实现列表平铺
外循环执行慢,内循环执行快
vec = [[1,2,3],[4,5,6],[7,8,9]]
[num for elem in vec for num in elem]
等价于
aList = []
vec = [[1,2,3],[4,5,6],[7,8,9]]
for elem in vec:
for num in elem:
aList.append(num)
过滤元素
筛选文件
import os
[filename for filename in os.listdir('.') if filename.endswith('.py')]
筛选成绩
scores = {"Zhang San":90,"Li Si":70,"Wang Wu":99}
highest = max(scores.values)
lowest = min(scores.values)
average = sum(scores.values)/len(scores)
highestPerson = [name for name,score in scores.items() if score == highest]
找到最值下标
nums = [1,2,3,4,5,6,9,1]
m = max(nums)
[index for index,num in enumerate(nums) if num == m ]
排列
[(x,y) for x in [1,2,3] for y in [2,3,4] if x!=y]
矩阵转置
matrix = [[1,2,3],[4,5,6],[7,8,9]]
[[row[i] for row in matrix] for i in range(4)]
复杂表达式
def f(v):
if v%2 == 0:
v = v**2
else:
v = v + 1
return v
print([f(v) for v in [2,3,4,-1] if v>0])
print([v**2 if v%2==0 else v+1 for v in [2,3,4,-1] if v>0])
文件对象迭代
fp = open('./data.dat','r')
print([line for line in fp])
fp.close()
生成素数
[p for p in range(2,100) if 0 not in [p%d for d in range(2,int(sqrt(p)) + 1)]]
列表切片
表示方式
由两个冒号将三个数字分开
- 第一个数字为起始位置(默认为0)
- 第二个数字为结束位置(不包含该位置)
- 第三个数字为切片步长(默认为1)
- 当步长省略时可以省略最后一个冒号
适用对象类型
适用于列表、元组、字符串、range对象
获取部分元素
aList = list(range(100))
aList[::] # 全部
aList[::-1] # 逆序
aList[::2] # 隔着一个元素取一个元素,偶数取
aList[1::2] # 隔着一个元素取一个元素,奇数取
aList[1:50] # 指定起始位置和结束位置,取出下标[1,50)的值
aList[1:1000] # 结束为止 > 最大长度 则在最大长度时截断
aList[1000:] # 起始位置 > 最大疮毒 则返回空列表!!!
aList[1000] # 越界访问报错!!!
增删改列表
aList = [1,2,3]
aList[len(aList)] = [9] # 在尾部加入9
aList[:3] = [3,2,1] # 替换范围
aList[:3] = [] # 删除元素
aList = list(range(10))
aList[::2] = [0] ** (len(Alsit)//2)
aList[3,3] = [1,2,3] # 在指定位置插入元素
切片返回的是列表元素的浅复制,与对象的直接赋值是不一样的,浅复制不是同一个对象
aList = [1,2,3]
bList = aList
cList = aList[::]
aList == bList # True
aList == cList # False
print(id(aList),id(bList),id(cList))
复习强调
- Python是基于值的内存管理方式
- 变量储存的是值的引用,而不是真正的值
易混
虽然直接把一个列表变量赋值给另外一个变量的时候,两个变量指向了同一个内存地址,但是把列表分别赋值给不同的2个变量时,内存地址也就不同了。
>>> x = [1,2,3]
>>> y = [1,2,3]
>>> z = x
>>> print(id(x),id(z),id(y))
2343225149384 2343225149384 2343225236936
声明
以上内容为本人学习笔记,如有错误请指正哦。