不要羡慕别人拥有的,只能说明我们付出的还不够。——马化腾(腾讯公司主要创办人)
一、列表
思考:有一个⼈的姓名(Amo)怎么书写存储程序?
答:变量。
name = "Amo"
思考:如果一个班级 100 位学⽣,每个人的姓名都要存储,应该如何书写程序?声明 100 个变量吗?
答:列表即可, 列表一次性可以存储多个数据。
列表(list) 是 Python 最基本的数据结构之一,它具有如下特点:
- 有序的数据结构。同字符串一样,可以通过下标索引访问内部数据。
- 可变的数据类型。可以随意添加、删除和更新列表内的数据,列表对象会自动伸缩,确保内部数据无缝隙有序排列。
- 内部数据统称为元素,元素的值可以重复,可以为任意类型的数据,如数字、字符串、列表、元组、字典和集合等。
- 列表的字面值使用中括号([])包含所有元素,元素之间使用逗号分隔。
1. 列表基本操作:定义列表、删除列表、访问列表、遍历列表
1.1 定义列表
(1) 中括号语法,列表的语法格式如下:
list_name = [element1, element2, element3, …, elementn]
其中,list_name 表示列表的名称,可以是任何符合 Python 命名规则的标识符;element1, element2, element3, …, elementn 表示列表中的元素,个数没有限制,并且只要是 Python 支持的数据类型就可以。
【示例1】演示使用中括号语法定义多个列表对象的方法。
list1 = ["a", "b", "c"] # 定义字符串列表
list2 = [1, 2, 3] # 定义数字列表
list3 = ["a", 1, 2.4] # 定义混合类型的列表
list4 = [] # 定义空列表
注意:尽管列表中可以存储不同类型的数据,但是一般来说存储的都是相同类型的数据,因为我们经常会对列表当中的数据进行操作,如果列表中元素的数据类型不一致,那么操作的方法就会不同,会增加程序的复杂度。所以从代码的可读性和程序的执行效率考虑,建议统一列表元素的数据类型。
(2) 使用 list() 函数可以将元组、range 对象、字符串,或者其他类型的可迭代数据转换为列表。
【示例2】使用 list() 函数把常用的可迭代数据都转换为列表对象。
list1 = list((1, 2, 3)) # 元组
list2 = list([1, 2, 3]) # 列表
list3 = list({
1, 2, 3}) # 集合
list4 = list(range(1, 4)) # 数字范围
list5 = list("Python") # 字符串
list6 = list({
"x": 1, "y": 2, "z": 3}) # 字典
list7 = list() # 空列表
print(list1, list2, list3, list4, list5, list6, list7)
输出显示为:
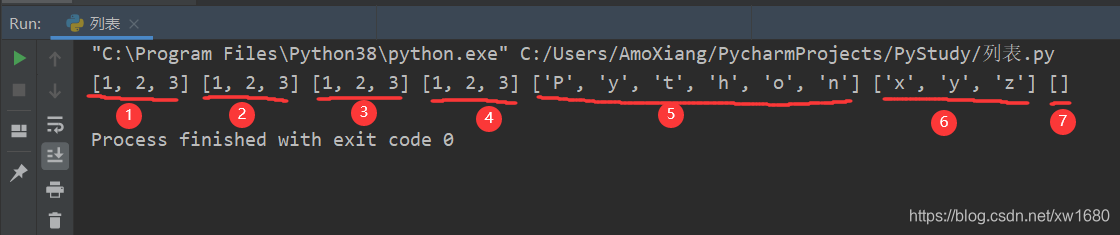
1.2 删除列表
当列表不再使用时,可以使用 del 命令手动删除列表。例如:
# 定义字符串列表
lipstick_list = ["阿玛尼405", "香奈儿154", "古驰505", "迪奥999", "纪梵希n37", "TF16"]
del lipstick_list # 删除列表
print(lipstick_list) # 报错:NameError: name 'lipstick_list' is not defined
1.3 访问列表
(1) 使用 print() 函数可以查看列表的数据结构,而使用中括号语法可以直接访问列表的元素。语法格式如下:
list_name[index]
list_name 表示列表对象(变量名),index 表示下标索引值。index 起始值为 0,即第 1 个元素的下标值为 0,最后一个元素的下标值为列表长度减 1。index 也可以为负值,负数的索引表示从右往左数,由 -1 开始,-1 表示最后一个元素,负列表长度表示第 1 个元素。
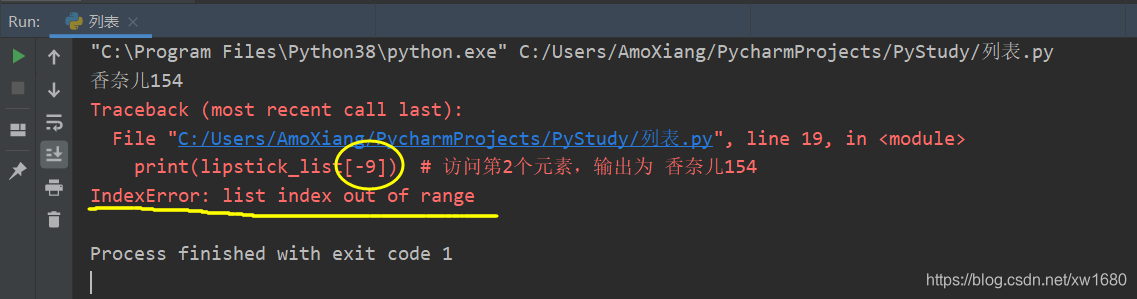
【示例3】定义一个列表 lipstick_list,分别使用正数和负数下标读取第 2 个元素的值。
# 定义字符串列表
lipstick_list = ["阿玛尼405", "香奈儿154", "古驰505", "迪奥999", "纪梵希n37", "TF16"]
print(lipstick_list[1]) # 访问第2个元素,输出为 香奈儿154
print(lipstick_list[-5]) # 访问第2个元素,输出为 香奈儿154
如果指定下标超出列表的范围,将抛出异常,如下图所示:
(2) 修改列表元素的语法与访问列表元素的语法类似,语法格式如下:
list_name[index] = value
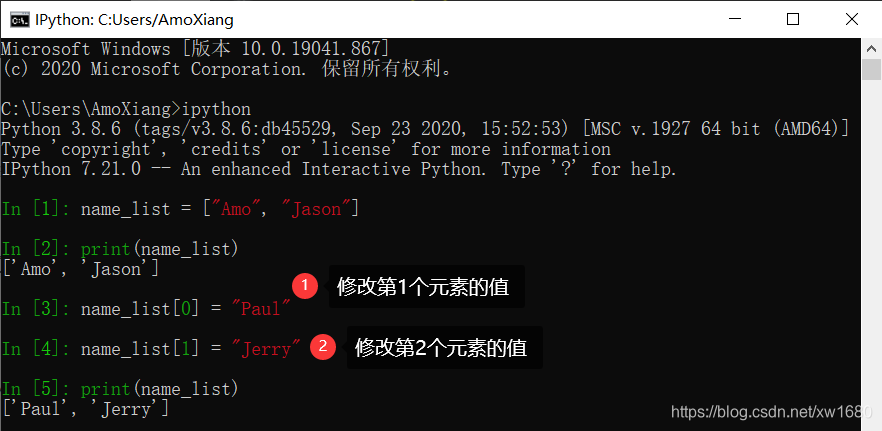
【示例4】定义一个列表 name_list,包含 2 个元素,然后重新修改第 1 个和第 2 个元素的值。
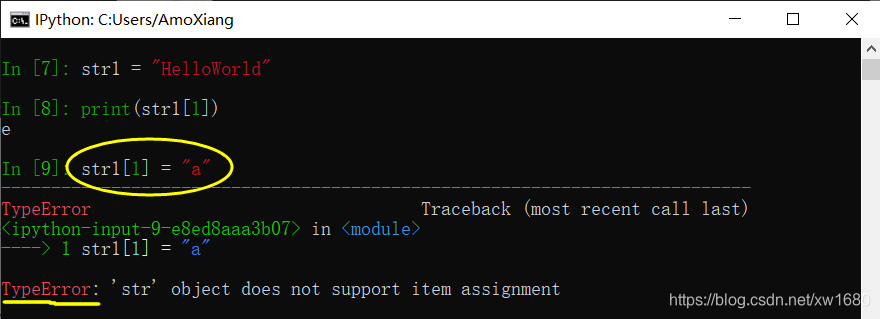
通过该方式修改只能修改可变数据结构,不可修改不可变数据结构。例如,下面代码定义了一个字符串,可以通过下标访问元素的值,但是不可以通过下标修改元素的值。
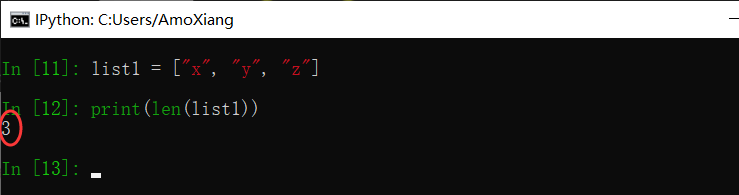
(3) 列表长度:定义一个列表 list1,然后使用 len() 函数统计元素的个数。如下:
练习:使用 while、for 语句遍历列表元素,并且把每个元素的字母转换为大写形式。
(4) 统计元素次数:使用列表对象的 count() 方法可以统计指定元素在列表对象中出现的次数。
【示例5】统计数字4在列表中出现的次数。

如果指定元素不存在就返回0。
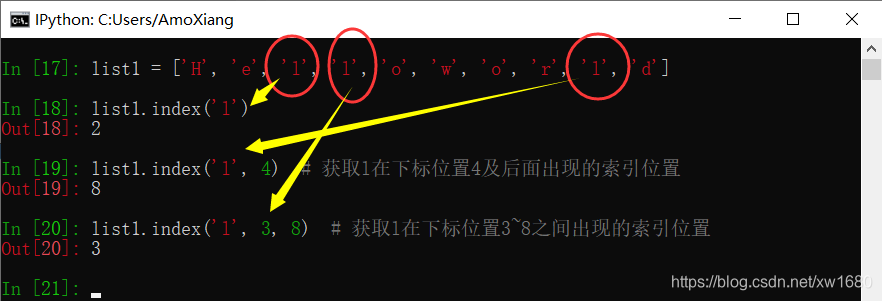
(5) 获取元素下标:使用列表对象的 index() 方法可以获取指定元素的 下标索引值。语法格式如下:
list_name.index(value, start, stop)
list_name 表示列表对象。参数 value 表示元素的值。start 和 stop 为可选参数,start 表示起始检索的位置,包含 start 所在位置,stop 表示终止检索的位置,不包含 stop 所在的位置。index() 方法将在指定范围内,从左到右查找第 1 个匹配的元素,然后返回它的下标索引值。示例代码如下:
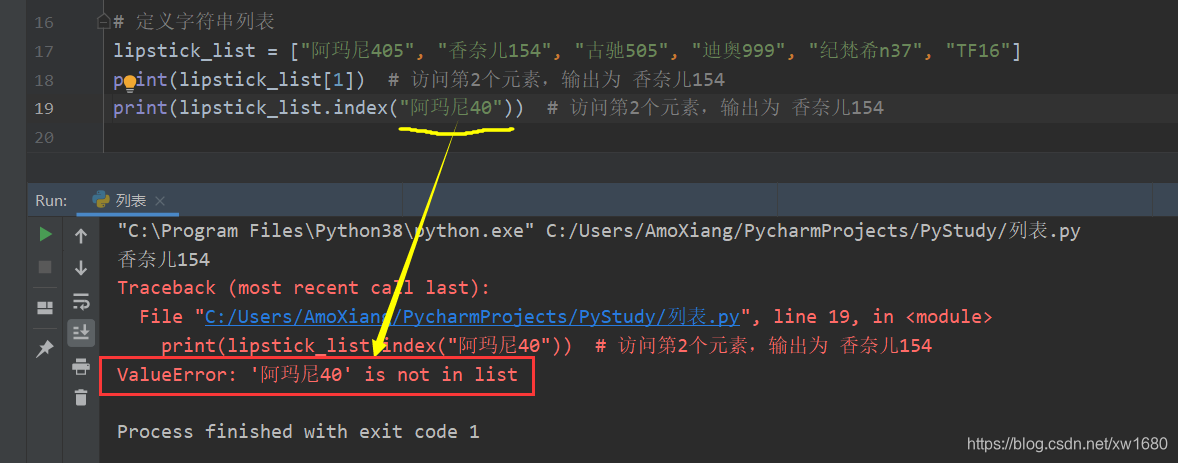
如果列表对象中不存在指定的元素,将会抛出异常,如下图所示。
(6) 切片操作:列表同字符串一样,可以使用切片操作。由于列表是可变数据结构,因此不仅可以使用切片来截取列表中的任何部分,获取一个新的列表,也可以通过切片来修改和删除列表中的部分元素,甚至可以通过切片操作为列表对象增加元素。在 Chapter Three : Python 序列之字符串操作详解 一文中已经详细介绍了切片的语法规则,同样适用于列表,故这里不再进行赘述。
【示例6】使用切片读取列表元素。
list1 = [3, 4, 5, 6, 7, 9, 11, 13, 15, 17]
print(list1[::])
print(list1[::-1])
print(list1[::2])
print(list1[1::2])
print(list1[3::])
print(list1[3:6])
print(list1[0:100:1])
print(list1[100:])
print(list1[100])
【示例7】使用切片原地修改列表元素。
list1 = [2, 4, 6]
list1[len(list1):] = [8] # 在尾部追加元素
print(list1)
list1[:3] = [1, 2, 3] # 替换前3个元素
print(list1)
list1[:3] = [] # 删除前3个元素
print(list1)
list1 = list(range(10)) # 修改为0-9的数字列表
print(list1)
list1[::2] = [0] * 5 # 替换偶数位置上的元素
print(list1)
list1[0:0] = [1] # 在索引为0的位置插入元素
print(list1)
# ValueError: attempt to assign sequence of size 3 to extended slice of size 6
list1[::2] = [0] * 3 # 切片不连续,两个元素个数必须一样多,否则抛出异常
# TypeError: can only assign an iterable
list1[:3] = 123 # 对切片赋值时,只能使用序列
【示例8】使用 del 与切片结合来删除列表元素。
list1 = [3, 5, 7, 9, 11]
del list1[:3] # 删除前三个元素
print(list1) # 输出:[9, 11]
list1 = [3, 5, 7, 9, 11]
list1[:3] = [] # 删除前三个元素
print(list1) # 输出:[9, 11]
list1 = [3, 5, 7, 9, 11]
del list1[::2] # 删除偶数位置上的元素
print(list1) # 输出:[5, 9]
切片操作都是列表元素的浅拷贝。所谓浅拷贝,是指生成一个新的列表,并且把原列表中所有元素的引用都复制到新列表中。如果原列表中只包含整数、实数、复数等基本类型或元组、字符串这样的不可变类型的数据,浅拷贝生成的新列表不会受原对象的影响。但是对于可变类型的数据,原对象的变动会影响新列表。
【示例9】简单比较列表引用和浅拷贝的异同。
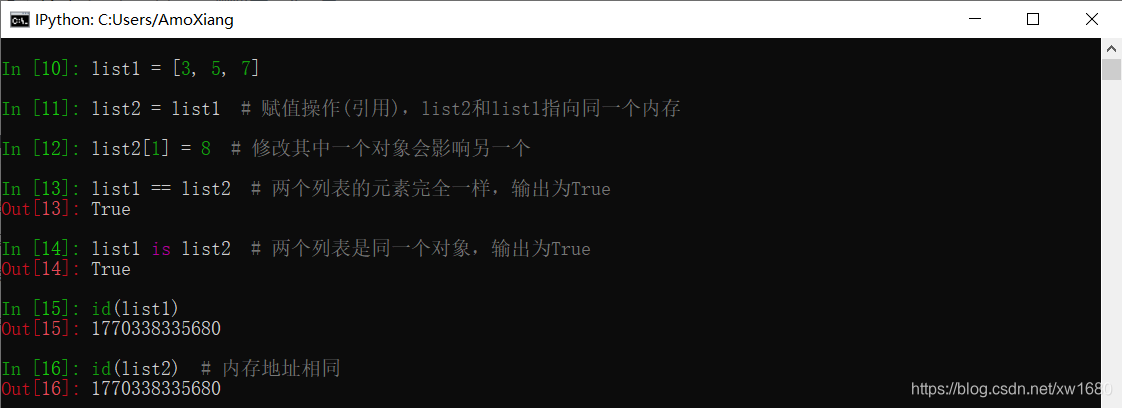
列表切片复制:
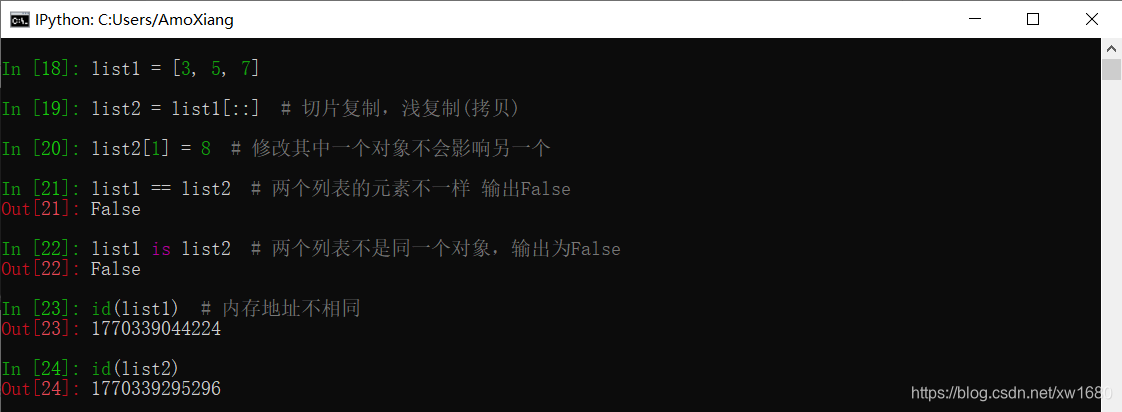
如果原列表中包含列表之类的可变数据类型,由于浅拷贝时只是把子列表的引用复制到新列表中,这样修改任何一个都会影响另一个。

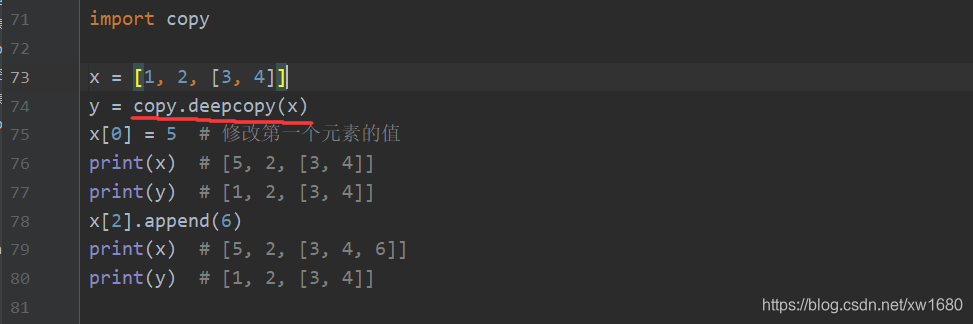
在 Python 中,对象赋值实际上就是引用对象。当创建一个对象,然后把它赋值给一个变量的时候,Python 只是把这个对象的引用赋值给变量。在上面的基础上使用 copy 模块中 copy 函数执行浅拷贝。
import copy
x = [1, 2, [3, 4]]
y = copy.copy(x)
x[0] = 5 # 修改第一个元素的值
print(x) # [5, 2, [3, 4]]
print(y) # [1, 2, [3, 4]]
x[2].append(6)
print(x) # [5, 2, [3, 4, 6]]
print(y) # [1, 2, [3, 4, 6]]
使用 deepcopy() 函数执行深拷贝,包含对象内的可变类型对象的复制,所以原对象的改变不会影响深拷贝后列表对象的元素内容。
1.4 遍历列表
遍历列表就是对列表中每个元素执行一次访问,这种操作在程序设计中会频繁应用,如过滤、筛选数据,或者对每个值执行一次处理等。Python 支持多种遍历列表的方法,具体说明如下。
(1) 使用 while 语句。
在日常开发中,while 语句遍历列表并不是常用的方法,语法格式如下:
i = 0
while i < len(list_name):
# 处理语句
i += 1
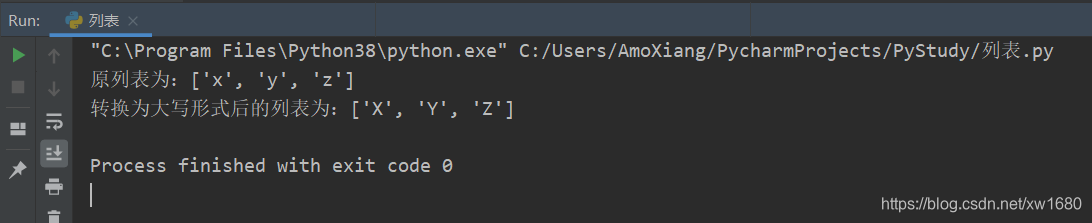
i 变量用来作为下标索引;list_name 表示列表对象;len() 函数获取列表对象的长度。在处理语句块中,可以通过 list_name[i] 访问对象中每个元素的值。使用 while 语句快速把每个元素的字母转换为大写形式。
letter_list = ["x", "y", "z"] # 定义列表
print(f"原列表为:{letter_list}")
i = 0 # 定义初始值
while i < len(letter_list): # 遍历列表
letter_list[i] = letter_list[i].upper() # 读取每个元素,然后转换为大写形式,再写入
i += 1
print(f"转换为大写形式后的列表为:{letter_list}")
程序运行结果为:
(2) 使用 for 语句。
这是在开发过程中最常用的方法,语法格式如下:
for item in list_name:
# 处理语句
item 变量用来临时存储每个元素的值,注意这个 item 只是个变量名,你取其他的也可,只要符合 Python 的变量命名规范;list_name 表示列表对象。在处理语句块中,可以引用 item 变量访问列表对象中每个元素的值。使用 for 语句快速把每个元素的字母转换为大写形式。
letter_list = ["x", "y", "z"] # 定义列表
print(f"原列表为:{letter_list}")
for letter in letter_list:
letter_list[letter_list.index(letter)] = letter.upper() # 读取每个元素,然后转换为大写形式,再写入
print(f"转换为大写形式后的列表为:{letter_list}")
注意:在上面的代码中,使用 letter_list_index(letter) 反向索引每个元素的下标值,这种操作存在很大风险。如果列表中出现重复的元素,则 letter_list_index(letter) 返回的总是第一次出现的下标值。如果为 letter_list 添加一个元素,值为 y,当使用 for 循环遍历时,letter_list.index(letter) 返回的 y 元素下标值总是 1。

解决这个问题,可以使用下面这个方法进行规避。
(3) 使用 for + enumerate()函数。enumerate() 函数可以将一个可迭代的对象转换为一个索引序列,常和 for 循环结合进行使用。语法格式如下:
enumerate(sequence, [start=0])
参数 sequence 表示一个序列、迭代器,或者其他可支持迭代的对象;start 表示下标起始位置。enumerate() 函数将返回一个 enumerate(枚举) 对象。
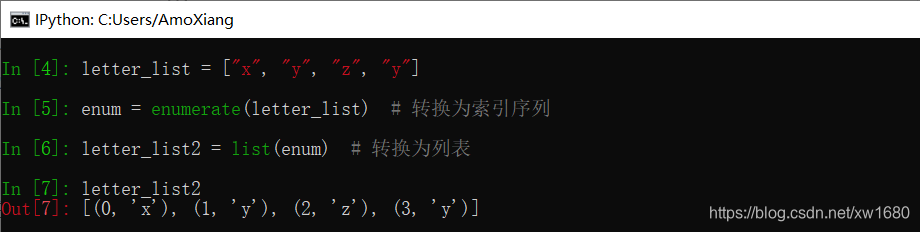
从 ipython 测试的结果看出,两个 y 元素的下标值是不同的,一个是 1,一个是 3。针对之前的案例,使用 for 循环遍历 enumerate 对象,就可以避免元素重复时所获取下标值重复问题。
letter_list = ["x", "y", "z"] # 定义列表
print(f"原列表为:{letter_list}")
for index, letter in enumerate(letter_list):
letter_list[index] = letter.upper() # 读取每个元素,然后转换为大写形式,再写入
print(f"转换为大写形式后的列表为:{letter_list}")
在上面的代码中,index 可以获取列表中当前元素的下标值,letter 可以获取列表中当前元素的值。
小结:遍历列表中的所有元素是常用的一种操作,在遍历的过程中可以完成查询、处理等功能。在生活中,如果想要去商场买一件衣服,就需要在商场中逛一遍,看看是否有想要的衣服,逛商场的过程就相当于列表的遍历操作。在 Python 中,遍历列表的方法有多种,for 语句的方式最为常用。
2. 列表常用方法及操作详解
2.1 添加元素:append()、extend()、insert()、+ 运算符、*运算符
(1) 列表对象的 append() 方法 用于在列表的末尾追加元素,语法如下:
list_name.append(obj)
其中,list_name 为要添加元素的列表名称,obj 为要添加到列表末尾的对象。例如,定义一个包括5个元素的列表,然后应用 append() 方法向该列表的末尾添加一个元素,可以使用下面的代码:

append() 是添加元素最快的方法。整个操作不改变列表在内存中的地址。列表中包含的是元素值的引用,而不是直接包含元素值。如果直接修改序列变量的值,则与 Python 普通变量的情况是一样的。
a = [1, 2, 4]
b = [1, 2, 4]
print(a == b) # True,值相等
print(id(a) == id(b)) # False,不等,内存地址不同
print(id(a[0]) == id(b[0])) # True,相等,第一个元素的值的地址相同
a = [1, 2, 3]
print(id(a)) # 2615215978176
a.append(4)
print(id(a)) # 2615215978176
a[0] = 5
print(id(a)) # 2615215978176
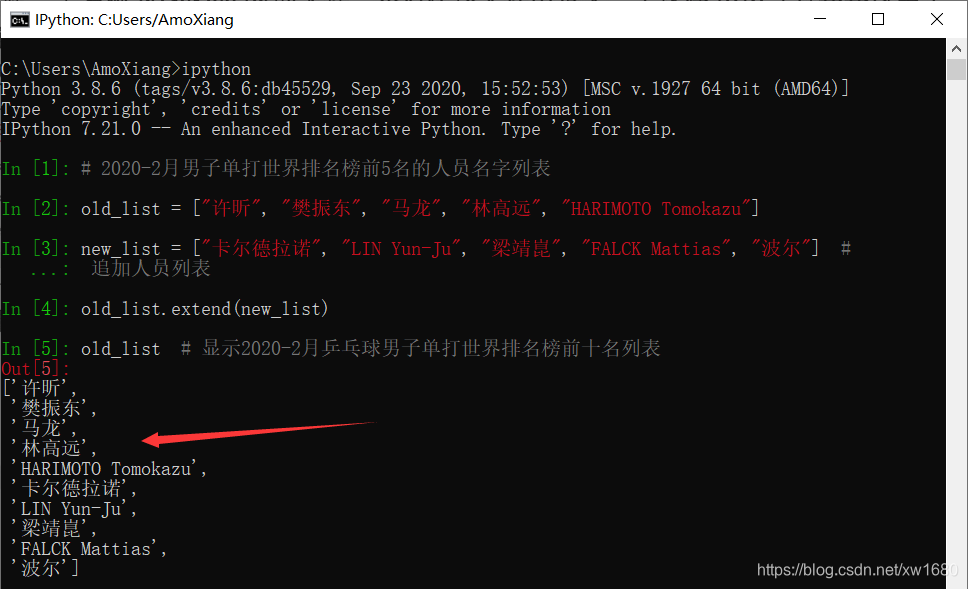
上面介绍的是向列表中添加一个元素,如果想要将一个迭代对象中的全部元素添加当前列表对象的尾部,可以使用列表对象的 extend() 方法实现。
(2) extend() 方法的语法如下:
list_name.extend(seq)
其中,list_name 为当前列表;seq 为要添加的迭代对象。语句执行后,seq 的内容将追加到 list_name 的后面。
(3) 使用 insert() 方法。 使用列表对象的 insert() 方法可以将元素添加到指定下标位置。语法格式如下:
list_name.insert(index, obj)
参数 index 表示插入的索引位置;obj 表示要插入列表中的对象。该方法没有返回值,只是在原列表指定位置插入对象。
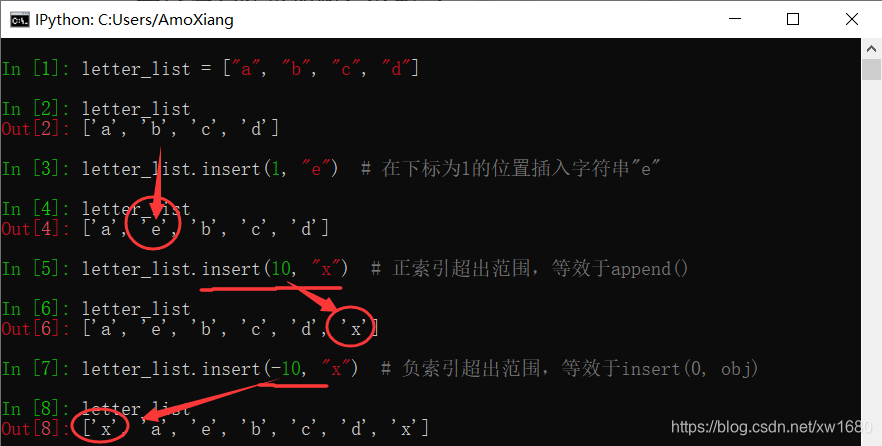
由于列表的内存自动管理功能,insert() 方法会引起插入位置之后所有元素的移位,这会影响处理速度。
(4) 使用 + 运算符。
与 extend() 方法功能类似,使用 + 运算符可以将两个列表对象合并为一个新的列表对象。

+ 运算符实际上并不是在原列表中添加元素,而是创建了一个新列表,并将原列表中的元素和参数对象依次复制到新列表中。由于涉及大量元素的复制,该操作速度较慢,在涉及大量元素添加时不建议使用该方法。
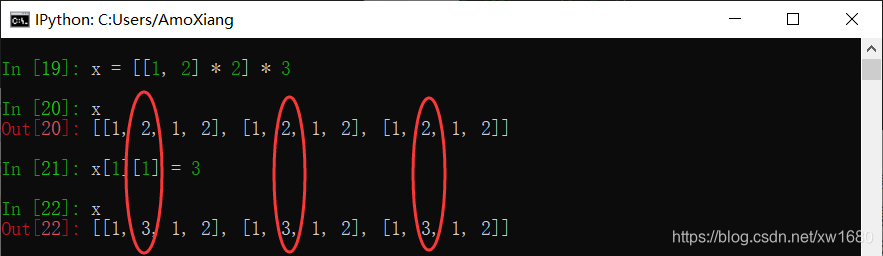
(5) 使用 * 运算符。 使用 * 运算符可以扩展列表对象,将列表与整数相乘,生成一个新列表,新列表是原列表中元素的重复。
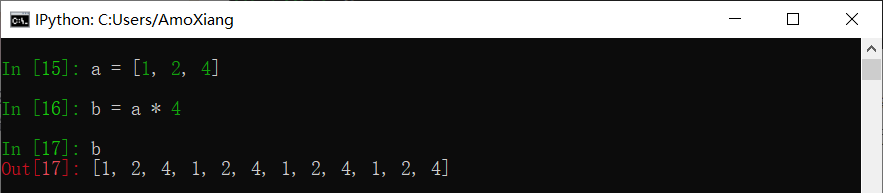
* 并不是复制原列表的值,而是复制已有元素的引用。因此,当修改其中一个值时,相应的引用也会被修改。
2.2 删除元素:del、pop()、remove()、clear()
删除元素主要有两种情况:一种是根据索引删除;另一种是根据元素值进行删除。
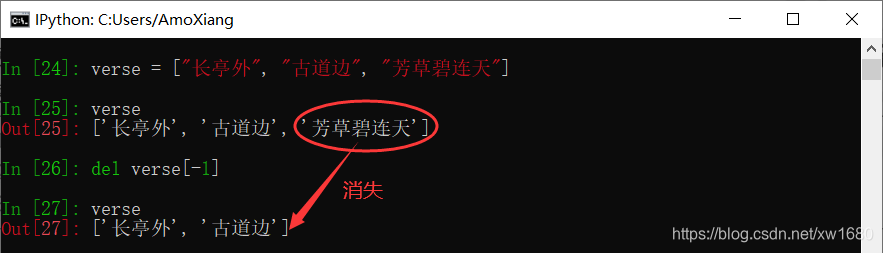
1. 使用 del 命令
定义一个保存3个元素的列表,删除最后一个元素,可以使用下面的代码:
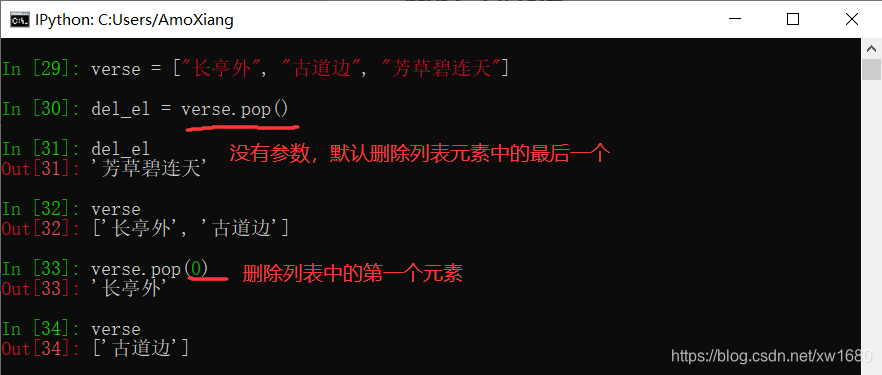
2. 使用 pop() 方法
使用列表的 pop() 方法可以删除并返回指定位置上的元素。语法格式如下:
list_name.pop([index=-1])
参数 index 表示要移除列表元素的索引值,默认值为-1,即删除最后一个列表值。如果给定的索引值超出了列表的范围,将抛出异常。
3. 使用 remove() 方法
使用列表对象的 remove() 方法可以删除首次出现的指定元素。语法格式如下:
list_name.remove(obj)
参数 obj 表示列表中要移除的对象,即列表元素的值。该方法没有返回值,如果列表中不存在要删除的元素,则抛出异常。
使用 remove() 方法删除列表中的重复元素2:
num_list = [1, 2, 3, 4, 2, 3, 4, 2, 3, 2, 4]
for num in num_list:
if 2 == num:
num_list.remove(num)
print(num_list)
仅就上面示例中的列表对象来说,操作结果是正确的,然而,上面的代码设计存在缺陷。如果是下面列表对象,重新执行删除操作,会发现并没有把所有的 2 都删除。演示代码如下:
num_list = [1, 2, 2, 2, 2, 2, 3, 4, 2, 3, 4, 2, 3, 2, 4]
for num in num_list:
if 2 == num:
num_list.remove(num)
print(num_list)
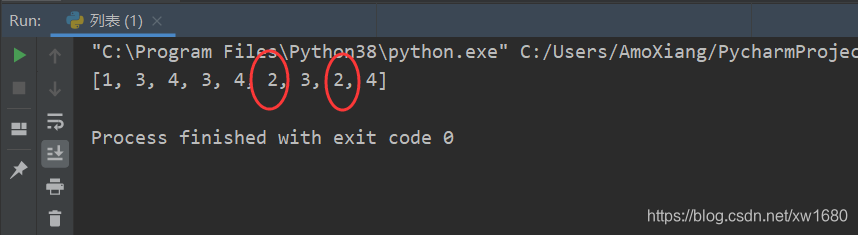
出现上述情况的原因,在删除列表元素时,Python 会自动对列表内存进行收缩,并移动列表元素以保证所有元素之间没有空隙。同理,在增加列表元素时,也会自动扩展内存,并对元素进行移动,以保证元素之间没有空袭。每当插入或删除一个元素之后,该元素位置后面所有元素的索引值都改变了。所以,在 for 循环遍历中,就会遗漏掉部分元素。【正确方法】如下:
num_list = [1, 2, 2, 2, 2, 2, 3, 4, 2, 3, 4, 2, 3, 2, 4]
for num in num_list[:]:
if 2 == num:
num_list.remove(num)
print(num_list) # [1, 3, 4, 3, 4, 3, 4]
或者下面这种:
num_list = [1, 2, 2, 2, 2, 2, 3, 4, 2, 3, 4, 2, 3, 2, 4]
for index in range(len(num_list) - 1, -1, -1):
if 2 == num_list[index]:
del num_list[index]
print(num_list) # [1, 3, 4, 3, 4, 3, 4]
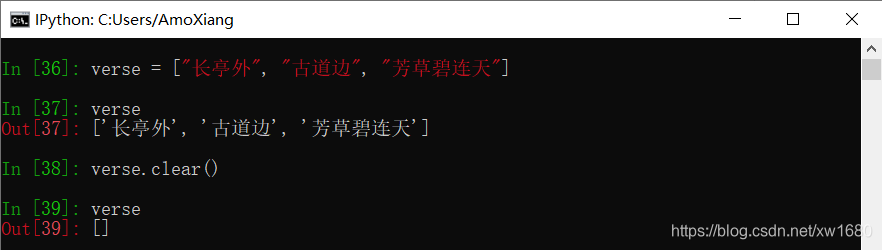
4. 使用 clear() 方法
使用列表对象的 clear() 方法可以删除列表中所有的元素。该方法没有参数,也没有返回值。
【比较】:
- pop() 方法是删除索引对应的值,remove() 方法是删除列表对象中最左边的一个值。
- pop() 方法针对的是元素的索引进行操作,remove() 方法针对的是元素的值进行操作。
- del 是一条命令,而不是方法,使用频率不及 pop() 和 remove() 方法。
2.3 使用 in 关键字检测元素
使用 in 关键字可以检测一个列表中是否存在指定的值,如果存在,则返回 True;否则返回 False。使用 not in 关键字也可以检测一个值,返回值与 in 关键字相反。

2.4 列表排序:reverse()、sort()
在 Python 中,列表排序有多种方法,具体说明如下。
1. 倒序
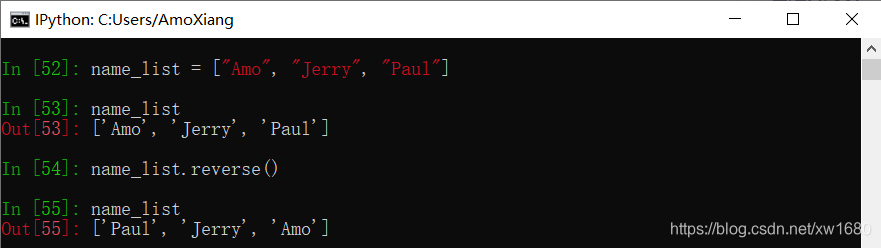
使用列表的 reverse() 方法可以反转列表中的元素,也可以使用 Python 内置函数 reversed() 对可迭代的对象进行反转,并返回反转后的新对象。reverse() 方法语法格式如下:
list_name.reverse()
该方法没有参数,也没有返回值,仅对原列表的元素进行反向排序。例如:
reversed() 函数需要传入一个序列对象,并返回一个新的序列对象。

2. 基本排序
使用列表对象的 sort() 方法可以进行自定义排序,也可以使用 Python 内置函数 sorted() 对可迭代的对象进行排序,然后返回新的对象。sorted() 函数的详细用法点击 Python 函数 | sorted 函数详解 一文进行学习,这里笔者就不再进行赘述。也可以使用 list_name.sort() 方法来排序,此时列表对象本身被修改,list_name.sort() 方法包含 2个可选参数,进行比较的关键字和排序规则,具体语法格式与 sorted() 函数相同。
2.5 列表推导式
推导式又称解析式,是 Python 语言独有的特性。推导式是可以从一个序列构建另一个新的序列的结构体。共有三种推导式:列表推导式、字典推导式、集合推导式。使用列表推导式可以快速生成一个列表,或者根据某个列表生成满足指定需求的列表。列表推导式通常有以下几种常用的语法格式。
2.5.1 生成指定范围的数值列表
语法格式如下:
list = [Expression for var in range]
参数说明:
- list:表示生成的列表名称。
- Expression:表达式,用于计算新列表的元素。
- var:循环变量。
- range:采用range()函数生成的range对象。
例如,要生成一个包括10个随机数的列表,要求数的范围在10~100(包括)之间,具体代码如下:
import random # 导入random标准库
num_list = [random.randint(10, 100) for i in range(10)]
print("生成的随机数为:", num_list)
执行结果如图所示:

2.5.2 根据列表生成指定需求的列表
语法格式如下:
newlist = [Expression for var in list]
参数说明:
- newlist:表示新生成的列表名称。
- Expression:表达式,用于计算新列表的元素。
- var:变量,值为后面列表的每个元素值。
- list:用于生成新列表的原列表。
例如,定义一个记录商品价格的列表,然后应用列表推导式生成一个将全部商品价格打五折的列表,具体代码如下:
price = [1200, 5330, 2988, 6200, 1998, 8888]
sale = [int(x * 0.5) for x in price]
print("原价格: ", price)
print("打五折的价格: ", sale)
运行结果如图所示:

2.5.3 从列表中选择符合条件的元素组成新的列表
语法格式如下:
newlist = [Expression for var in list if condition]
参数说明:
- newlist:表示新生成的列表名称。
- Expression:表达式,用于计算新列表的元素。
- var:变量,值为后面列表的每个元素值。
- list:用于生成新列表的原列表。
- condition:条件表达式,用于指定筛选条件
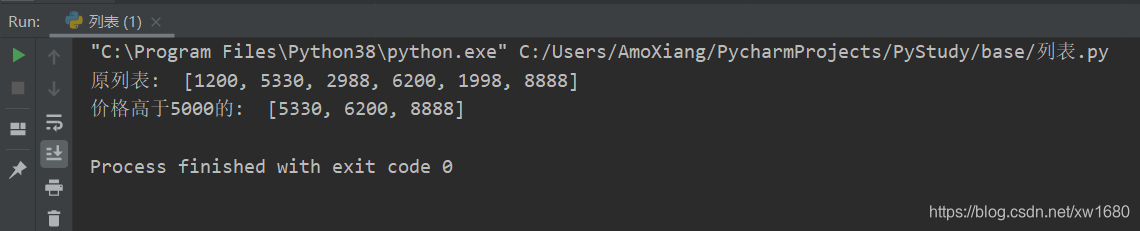
例如,定义一个记录商品价格的列表,然后应用列表推导式生成一个商品价格高于5000元的列表,具体代码如下:
price = [1200, 5330, 2988, 6200, 1998, 8888]
sale = [x for x in price if x > 5000]
print("原列表: ", price)
print("价格高于5000的: ", sale)
运行结果如图所示:
3. 二维列表的使用
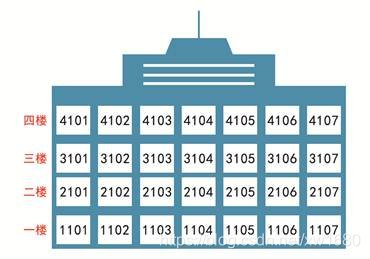
在 Python 中,由于列表元素还可以是列表,所以它也支持二维列表的概念。那么什么是二维列表?酒店有很多房间,这些房间都可以构成一个列表,如果这个酒店有 500 个房间,那么拿到 499 号房钥匙的旅客可能就不高兴了,从 1 号房走到 499 号房要花好长时间,因此酒店设置了很多楼层,每一个楼层都会有很多房间,形成一个立体的结构,把大量的房间均摊到每个楼层,这种结构就是二维列表结构。使用二维列表结构表示酒店每个楼层的房间号的效果如图所示。
二维列表中的信息以行和列的形式表示,第一个下标代表元素所在的行,第二个下标代表元素所在的列。在 Python 中,创建二维列表有以下三种常用的方法。
3.1 直接定义二维列表
在Python中,二维列表是包含列表的列表,即一个列表的每一个元素又都是一个列表。例如,下面就是一个二维列表:
[['千', '山', '鸟', '飞', '绝'],
['万', '径', '人', '踪', '灭'],
['孤', '舟', '蓑', '笠', '翁'],
['独', '钓', '寒', '江', '雪']]
在创建二维列表时,可以直接使用下面的语法格式进行定义:
list_name = [[元素11, 元素12, 元素13, …, 元素1n],
[元素21, 元素22, 元素23, …, 元素2n],
…,
[元素n1, 元素n2, 元素n3, …, 元素nn]]
参数说明:
- list_name:表示生成的列表名称。
- [元素11, 元素12, 元素13, …, 元素1n]:表示二维列表的第一行,也是一个列表。其中"元素11,元素12,…元素1n"代表第一行中的列。
- [元素21, 元素22, 元素23, …, 元素2n]:表示二维列表的第二行。
- [元素n1, 元素n2, 元素n3, …, 元素nn]:表示二维列表的第n行。
例如,定义一个包含 4 行 5 列的二维列表,可以使用下面的代码:
verse_list = [['千', '山', '鸟', '飞', '绝'], ['万', '径', '人', '踪', '灭'],
['孤', '舟', '蓑', '笠', '翁'], ['独', '钓', '寒', '江', '雪']]
print(verse_list)
执行结果如图所示:

3.2 使用嵌套的 for 循环创建
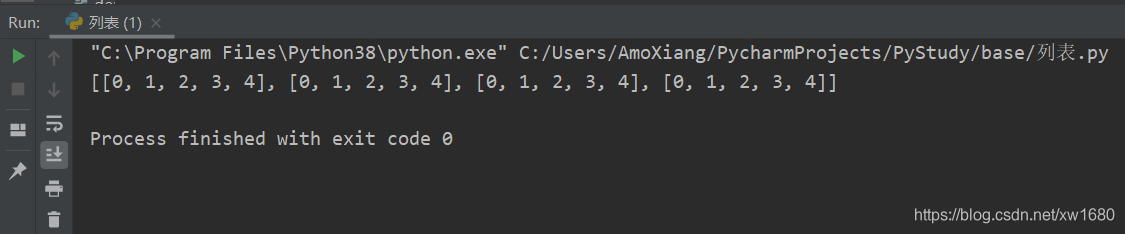
创建二维列表,可以使用嵌套的 for 循环实现。例如,创建一个包含 4 行 5 列的二维列表,可以使用下面的代码:
arr = [] # 创建一个空列表
for i in range(4):
arr.append([]) # 在空列表中再添加一个空列表
for j in range(5):
arr[i].append(j) # 为内层列表添加元素
print(arr)
运行结果如图所示:
3.3 使用列表推导式创建
使用列表推导式也可以创建二维列表,因为这种方法比较简洁,所以建议使用这种方法创建二维列表。例如,使用列表推导式创建一个包含 4 行 5 列的二维列表可以使用下面的代码:
arr = [[j for j in range(5)] for i in range(4)]
创建二维数组后,可以通过以下语法格式访问列表中的元素:
list_name[下标1][下标2]
参数说明:
- list_name:列表名称。
- 下标1:表示列表中第几行,下标值从0开始,即第一行的下标为0。
- 下标2:表示列表中第几列,下标值从0开始,即第一列的下标为0。
例如,要访问二维列表中的第 2 行,第 4 列,可以使用下面的代码:
verse_list[1][3]
下面通过一个具体实例演示二维列表的应用
在 PyCharm 中创建一个名称为 print_verse.py 的文件,然后在该文件中首先定义4个字符串,内容为柳宗元的《江雪》中的诗句,并定义一个二维列表,然后应用嵌套的 for 循环将古诗以横版方式输出,再将二维列表进行逆序排列,最后应用嵌套的 for 循环将古诗以竖版方式输出,代码如下:
str1 = "千山鸟飞绝"
str2 = "万径人踪灭"
str3 = "孤舟蓑笠翁"
str4 = "独钓寒江雪"
verse = [list(str1), list(str2), list(str3), list(str4)] # 定义一个二维列表
print("\n-- 横版 --\n")
for i in range(4): # 循环古诗的每一行
for j in range(5): # 循环每一行的每个字(列)
if j == 4: # 如果是一行中的最后一个字
print(verse[i][j]) # 换行输出
else:
print(verse[i][j], end="") # 不换行输出
verse.reverse() # 对列表进行逆序排列
print("\n-- 竖版 --\n")
for i in range(5): # 循环每一行的每个字(列)
for j in range(4): # 循环新逆序排列后的第一行
if j == 3: # 如果是最后一行
print(verse[j][i]) # 换行输出
else:
print(verse[j][i], end="") # 不换行输出
说明:在上面的代码中,list() 函数用于将字符串转换为列表;列表对象的 reverse() 方法用于对列表进行逆序排列,即将列表的最后一个元素移到第一个,倒数第二个元素移到第二个,以此类推。运行结果如图所示:

二、元组
元组 (tuple) 是只读列表,也是 Python 最基本的数据结构之一,它具有如下特点:
- 有序的数据结构。同列表一样,可以通过下标索引访问内部数据。
- 不可变的数据类型。不能够添加、删除和更新元组内的数据。
- 内部数据统称为元素,元素的值可以重复,可以为任意类型的数据,如数字、字符串、列表、元组、字典和集合等。
- 元组的字面值使用小括号
()包含所有元素,元素之间使用逗号分隔。
1. 定义元组
在 Python 中,定义元组有两种方法,简单说明如下。
1. 小括号语法
在 Python 中,可以直接通过小括号 () 创建元组。创建元组时,小括号内的元素用逗号分隔。其语法如下:
tuple_name = (element1, element2, element3, …, elementn)
其中,tuple_name 表示元组的名称,可以是任何符合 Python 命名规则的标识符;element1、element2、element3、elementn 表示元组中的元素,个数没有限制,并且只要是 Python 支持的数据类型就可以。
【示例1】演示使用小括号语法定义多个元组对象的方法。
tuple1 = ("a", "b", "c") # 定义字符串元组
tuple2 = (1, 2, 3) # 定义数字元组
tuple3 = ("渔舟唱晚", "高山流水", "出水莲", "汉宫秋月")
tuple4 = () # 定义空元组
un_title = ("Python", 28, ("人生苦短", "我用Python"), ["爬虫", "自动化运维", "云计算", "Web开发"])
在 Pytho n中,元组使用一对小括号将所有的元素括起来,但是小括号并不是必须的,只要将一组值用逗号分隔开来,Python 就可以视其为元组。
【示例2】针对示例1代码,可以省略小括号,同样能够定义元组。
tuple1 = "a", "b", "c" # 定义字符串元组
tuple2 = 1, 2, 3 # 定义数字元组
tuple3 = "渔舟唱晚", "高山流水", "出水莲", "汉宫秋月"
un_title = "Python", 28, ("人生苦短", "我用Python"), ["爬虫", "自动化运维", "云计算", "Web开发"]
如果要创建的元组只包括一个元素,则需要在定义元组时,在元素的后面加一个逗号 ,。例如,下面的代码定义的就是包括一个元素的元组:
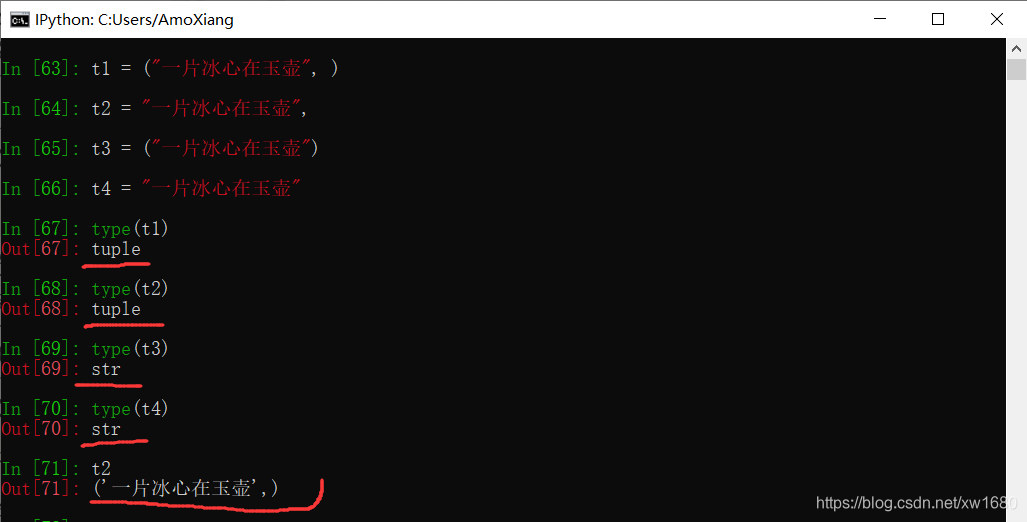
与列表一样,Python 对元组元素的类型没有严格的限制,每个元素可以是不同的数据类型,但是从代码的可读性和程序的执行效率考虑,建议统一元组元素的数据类型。
2. 使用 tuple() 函数
使用 tuple() 函数可以将列表、range 对象、字符串或者其他类型的可迭代数据转换为元组。
【示例3】使用 tuple() 函数把常用的可迭代数据都转换为元组对象。
tuple1 = tuple((1, 2, 3)) # 元组
tuple2 = tuple([1, 2, 3]) # 列表
tuple3 = tuple({
1, 2, 3}) # 集合
tuple4 = tuple(range(1, 4)) # 数字范围
tuple5 = tuple("Python") # 字符串
tuple6 = tuple({
"x": 1, "y": 2, "z": 3}) # 字典
tuple7 = tuple() # 空列表
print(tuple1, tuple2, tuple3, tuple4, tuple5, tuple6, tuple7)
2. 元组常见操作
关于元组的删除、访问、计算元组的长度、统计元素个数、获取元素下标、转换为索引序列的操作和列表类似,故笔者这里就不再进行赘述,简单进行一下演示,如下:
"""
1.删除元组 del tuple_name
del 语句在实际开发时,并不常用。因为 Python 自带的垃圾回收机制会自动销毁不用的元组,
所以即使不手动将其删除,Python也会自动将其回收。
"""
verse = ("春眠不觉晓", "Python不得了", "夜来爬数据", "好评知多少")
del verse
"""
2.元组长度:len()函数
"""
tuple1 = ("a", "b", "c") # 定义字符串元组
print(len(tuple1)) # 3
"""
3.访问元组:tuple_name[index]
"""
tuple2 = ("a", "b", "c") # 定义字符串元组
print(tuple1[0], tuple1[-1]) # a c
"""
4.count()方法:统计指定元素出现在元组对象中的次数
"""
tuple3 = (1, 2, 3, 4, 5, 5, 4, 3, 2, 1, 4)
print(tuple3.count(3), tuple3.count(0)) # 2 0
"""
5.index()方法:获取指定元素的下标索引值,元组对象中不存在指定的元素,将会抛出异常。
"""
tuple4 = (1, 2, 3, 4, 5, 5, 4, 3, 2, 1, 4)
print(tuple3.index(4)) # 3
"""
enumerate()函数
"""
t1 = ("a", "b", "c", "d") # 定义元组
enum = enumerate(t1)
t2 = tuple(enum)
print(t2) # ((0, 'a'), (1, 'b'), (2, 'c'), (3, 'd'))
另外元组也是可以使用 for 循环进行遍历以及切片操作的,跟列表使用方法类似,注意:元组是不可变序列,所以我们不能对它的单个元素值进行修改。
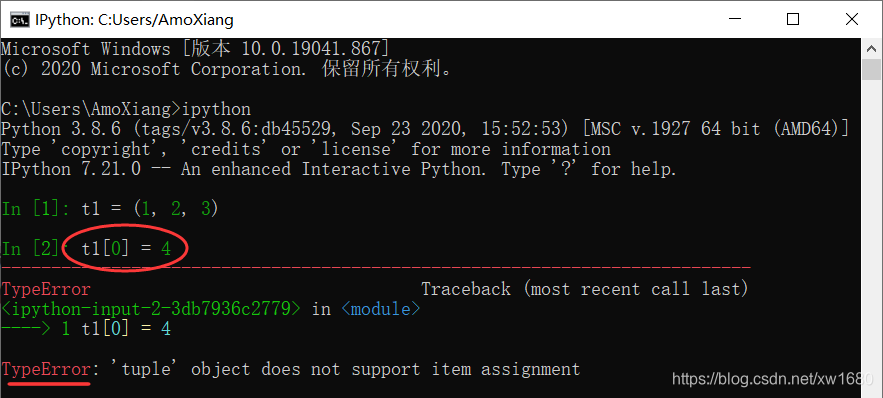
3. 元组与列表比较
元组是不可变的序列,而列表是可变的序列。具体比较说明如下:
1. 相同点
- 定义元组与定义列表的方式相似,但是语法表示不同,元组使用小括号表示,而列表使用中括号表示。
- 元组的元素与列表的元素一样按定义的次序进行排序。元组的索引与列表一样从0开始,所以一个非空元组的第一个元素总是t[0]。
- 负数索引与列表一样从元组的尾部开始计数,倒数第1个元素为-1。
- 与列表一样也可以使用切片。当分隔一个元组时,也会得到一个新的元组。
- 可以使用 in 或 not in 运算符查看一个元素是否存在于元组或列表中。
2. 不同点
- 元组是只读序列,与列表相比,没有写操作的相关方法。不能增加元素,因此元组没有 append() 和 extend() 方法。不能删除元素,因此元组没有remove() 和 pop() 方法。
- 列表不能够作为字典的键使用,而元组可以作为字典的键使用。
3. 元组的优点
元组比列表操作速度快。
- 如果定义一个常量集,并且仅用于读取操作,建议优先选用元组结构。
- 如果对一组数据进行
写保护,建议使用元组,而不是列表。如果必须要改变这些值,则需要执行从元组到列表的转换。
4. 相互转换
从效果上看,元组可以冻结一个列表,而列表可以解冻一个元组。
- 使用内置的 tuple() 函数可以将一个列表转换为元组。
- 使用内置的 list() 函数可以将一个元组转换为列表。