图的基本概念
图(Graph)是一种非线性数据结构。
顶点:树中的元素我们叫做节点;图中的元素我们叫做顶点(vertex)。
边:图中的一个顶点可以与任意其他顶点建立关系,我们把这种建立的关系叫做边(edge)。
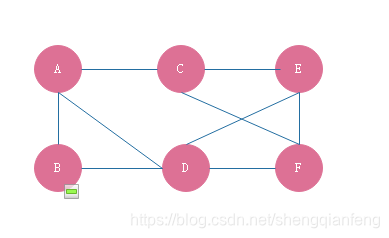
度:以微信为例,我们可以把每个用户看成一个顶点,如果两个用户之间互加好友,那就在两者之间建立一条边。所以整个微信的好友关系就可以用一张图来表示。其中每个用户有多少个好友,对应到图中就是就叫做顶点的度(degree),即跟顶点相连接的边的条数。
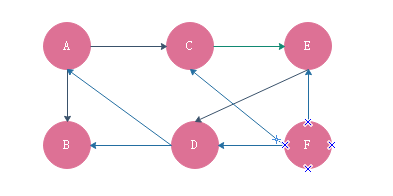
实际上,微博的好友关系跟微信不同,微博更复杂,因为微博允许单行关注,即A用户关注了B用户,但是B用户可以不关注A用户。这种关系也可以用图来表示。不过此时的关系即边是有方向的。
如果A关注B,那么就画一条从A指向B的边。
如果A和B互相关注,那么画一条从A指向B的边,再画一条从B指向A的边。
有向图:我们把这种边有方向的图叫做有向图,而反之边没有方向的就叫做无向图。
无向图中有度的概念,表示一个顶点有多少条边。
有向图中也有度的概念,分为入度和出度。
顶点的入度(In-degree):表示有多少条边指向这个顶点。
顶点的出度(out-degree):表示有多少条边是以这个顶点为起点指向其他顶点的。
以微博为例,入度可以表示有多少粉丝,出度可以表示自己关注了多少人。
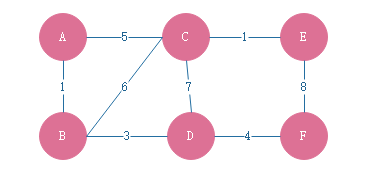
实际上,QQ的好友关系跟微博和微信都不同,QQ有亲密度,这个亲密度其实就是图中的边的权重的概念。
带权图:在图中每条边都有一个权重(weight),可以通过这个权重来表示QQ好友间的亲密度。
图的存储
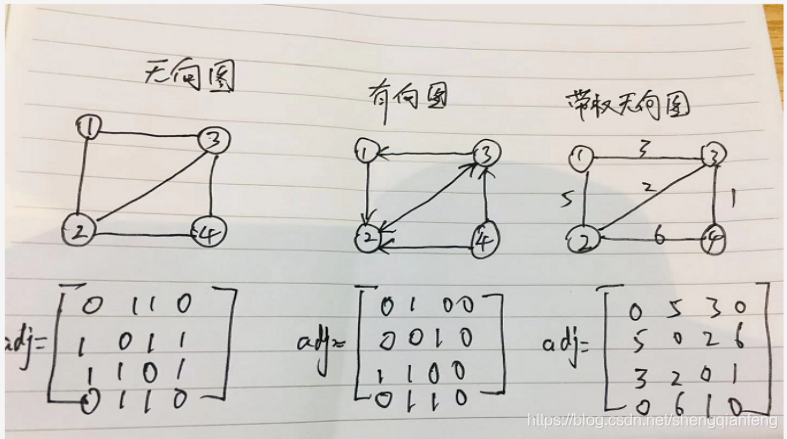
邻接矩阵存储法
图最直观的一种存储方法就是邻接矩阵存储法(Adjacency Matrix)
邻接矩阵底层依赖于一个二维数组。
对于无向图来说,如果顶点i和顶点j之间有边,我们就将a[i][j]和a[j][i]标记为1
对于有向图来说,如果顶点i到顶点j之间,有一条箭头从顶点i指向顶点j的边,那么我们就将
a[i][j]标记为1,同理,如果有一条箭头从顶点j指向顶点i的边,那么我们就将a[j][i]标记为1。
对于带权图,数组中就存储相应的权重。
使用邻接矩阵来存储图,确实很简单直接,但是非常浪费空间。
比如对于无向图来说,如果a[i][j]=1,那么a[j][i]肯定也等于1.实际上我们只需要存储一个就可以了。也就是说,无向图中我们可以用对角线将其划分为上下两部分,那么我们只需要利用上下两部分就足够了,剩下一半就浪费了。
还有,如果存储的图示稀疏图(Sparse Matrix),即顶点很多但是每个顶点的边并不多。这种情况下邻接矩阵存储法更加浪费空间了。
比如说,微信用户有很多好几个亿,也就是有好几个亿的顶点,但是每个用户也就几百好友不等,那么绝大多数的存储空间就浪费了。
邻接矩阵存储法的优点:简单直接、基于数据访问友好、矩阵计算方便。
邻接表存储法
邻接表存储法(Adjacency List)跟散列表相似,如图,每个顶点对应一条链表,链表中存储的是跟这个顶点连接的其他顶点,下图是一个有向图邻接表的存储,每个顶点对应链表存储的是这个顶点所指向的其他顶点,可以用来表示自己关注的微博用户。无向图类似。
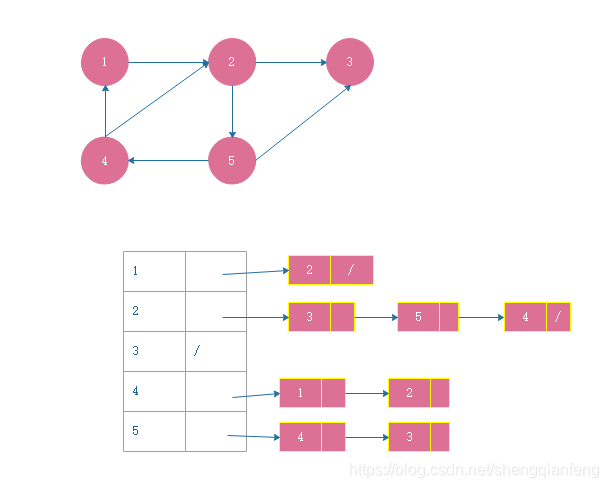
其实邻接矩阵存储法简单直接,耗费内存,但是速度比较快。而邻接表空间利用率高但查找速度相对慢。这就是空间和时间相互交换的思想的体现。
比如我们想确定一个顶点是否有到另一个顶点的边,利用邻接表存储方式,就得遍历原始顶点对应的那条链表。由于链表存储方式对缓存不友好,相对于邻接矩阵存储法查找效率就偏低了。但是不要紧,可以升级改造这条链表为其他支持快速crud的数据结构比如跳表、红黑树这种平衡二叉查找树等。或者改造为动态有序数组利用二分法查找定位顶点是否存在。