准备工作
%matplotlib inline
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow.examples.tutorials.mnist.input_data as input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
由于使用jupyter notebook,若不加入%matplotlib inline,图片将不会在notebook中显示。
其中read_data_sets("MNIST_data/", one_hot=True)的第一个参数是数据集保存的位置,第二个参数决定数据是否采用独热编码。因为是分类问题,一般使用独热编码,设置其参数为
。如果此时该目录下没有数据文件,那么将花费几分钟下载后再读取;如果有数据文件,则会自动读取。
定义模型
定义占位符
x = tf.placeholder(tf.float32, [None, 784], name="X")
y = tf.placeholder(tf.float32, [None, 10], name="Y")
定义占位的
,最后在
中将数据通过
喂入神经网络。
注:placeholder是Tensorflow1.x版本中定义占位符的函数,在最新的Tensorflow2.x中失效。
定义神经网络和前向传播过程
# 隐藏层神经元数量
H1_NN = 256
W1 = tf.Variable(tf.random_normal([784, H1_NN], stddev=0.1),name="W1")
b1 = tf.Variable(tf.zeros([H1_NN]),name="b1")
Y1 = tf.nn.relu(tf.matmul(x,W1) + b1)
W = tf.Variable(tf.random_normal([H1_NN,10], stddev=0.1),name="W")
b = tf.Variable(tf.zeros([10]),name="b")
# 前向传播
forward = tf.matmul(Y1,W) + b
pre = tf.nn.softmax(forward)
即我们最后得到的一个一行十列的向量,用来训练模型或者预测图片上的数字。由于在这里只定义了一个隐藏层,所以本文中的是简单的一层神经网络模型,下次将使用模块化思想设计定义隐藏层函数。
损失函数及优化器
# 交叉熵损失函数
loss_fun = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=forward, labels=y))
# 优化器
lr = 0.0001
opt = tf.train.AdamOptimizer(lr).minimize(loss_fun)
由于此问题是一个多元分类问题,所以不能使用逻辑回归中的损失函数
而使用
将逻辑回归延申到多类别。
这里优化器使用的是
优化器,其中参数
是学习率,.minimize(loss_fun)是将
降低,可以尝试换成别的优化器观察一下结果。
定义准确率
# 检查预测类别tf.argmax(pre, 1)与实际类别tf.argmax(y, 1)的匹配情况
correct_pre = tf.equal(tf.argmax(pre, 1), tf.argmax(y, 1))
# cast将布尔值投射成浮点数
acc = tf.reduce_mean(tf.cast(correct_pre, tf.float32))
函数argmax用来得到一行或者一列中数值最大的数的位置,若参数设置为1,则得到同一列中的最大值的位置;若设置为0,则得到同一行中最大值的位置。
超参数及参数的设置
# 训练轮数
epochs = 50
# 一次喂入神经网络的个数
batch_size = 40
totle_batch = int(mnist.train.num_examples/batch_size)
# 显示粒度
display_step = 1
Loss = []
每训练
轮即输出当前的轮数,损失和准确率。
Loss用来保存每次验证集测试的损失,并在最后通过画图显示出来。
训练模型
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(epochs):
for batch in range(totle_batch):
xs, ys = mnist.train.next_batch(batch_size)
# 使用feed_dict将xs和ys喂入神经网络中,训练神经网络
sess.run(opt,feed_dict = {x:xs, y:ys})
# 每训练一轮测试模型在验证集上的表现
loss, accuracy = sess.run([loss_fun, acc], feed_dict={x:mnist.validation.images, y:mnist.validation.labels})
Loss.append(loss)
# 每训练display_step轮就输出当前训练信息
if (epoch+1) % display_step == 0:
print("Train Epoch:%02d" % (epoch+1),"Loss=%f" % loss, "Acc=%.4f" % accuracy)
# 模型在测试集上的正确率
acca = sess.run(acc, feed_dict={x:mnist.test.images, y:mnist.test.labels})
plt.plot(Loss)
plt.show()
print("Accuracy=%f" % acca)
print("Train Finished")
训练结果

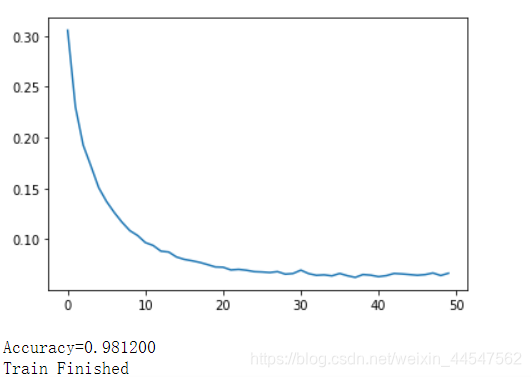
可见训练50轮后验证集的正确率已达到98.3%,测试集上的准确率达到98.12%,正确率算是比较高。
观察Loss的图像发现后面部分loss在波动,猜测应该是由于学习率高导致,后面可采用动态指数下降学习率来使学习率逐渐降低,以弱化或者避免这种结果的出现。