论文地址:https://arxiv.org/pdf/1801.10308.pdf
文章未公开源码,Github上有各种版本的实现供参考学习(如下):
- Keras Implementation of Nested LSTMs
- Tensorflow Implementation of Nested LSTM Cell
- Pytorch Implementation of Nested LSTMs
写在前面:在谷歌2016年发布的神经机器翻译(GNMT)中,就采用了堆栈LSTM,编码器由8个LSTM组成,其中第一个是双向的(其输出是连接的),来自连续层的输出之间存在残余连接(从第3层开始)。解码器是8个单向LSTM的独立堆栈。通过加深网络的深度。获得更高的准确率。而这篇文章(2018年发布)的研究者们提出并探索了一种全新的嵌套 LSTM 架构(Nested LSTM,NLSTM),并认为其有潜力直接取代堆栈 LSTM。嵌套LSTM通过嵌套而不是堆叠来增加深度!!!
Abstract
我们提出嵌套式长短期记忆网络(Nested LSTMs,NLSTM),一种具有多级记忆的新型循环神经网络(RNN)架构。嵌套式LSTM通过嵌套而不是堆栈来增添LSTM的深度。在NLSTM中,记忆单元的值是由LSTM单元计算的,其中,LSTM单元具有自身内在的记忆单元。对外部单元进行计算,NLSTM记忆单元使用级联,并将其作为内部LSTM(或NLSTM)记忆单元的输入。在我们各种字符级语言建模任务的实验中,在参数数量相似的情况下,嵌套式LSTM的性能要远优于堆栈和单层LSTM,并且,与堆栈式LSTM的高级单元相比,LSTM的内部记忆能够学习更长期的依赖关系。
一、Introduction
学习长期的依赖关系是当前人工智能领域中机器学习方法的关键性挑战。对于人类来说,将这些长期依赖关系与直接的环境相调和的能力是必不可少的,即适应和使用以前所获得的,且能够与当前参考框架相关的知识。如果从一个小规模的概念出发,这种能力的一个典型示例可以是这样的,即一个人能够基于过去的经验预测句子或文档中的字符和单词(例如,以常见的结构和短语的形式)、文档处理中的通用问题、以及问题中有关具体句子的确切措辞。基于循环神经网络的体系结构已经在使得机器能够模仿这种能力方面取得了显著进展。
循环神经网络(RNN)在其整个输入历史中,都是以世界状态的当前表示为依据的(或强化学习说法中的“观察”),因此对于学习时间上的抽象特征自然而然是适合的。理论上来说,一个简单的RNN可以表示任意函数,因此有能力在任意时间尺度上解决涉及依赖关系的任务。在实践中,许多专家已经证明,更为复杂的体系结构是解决许多任务的关键。其中一个原因是梯度消失问题(Hochreiter于1991年、Bengio等人于1994年提出),它使得简单的RNN难以学习长期依赖关系。成功的RNN体系结构,如LSTM(Hochreiter和Schmidhuber于1997年提出)通常包含能够改善梯度消失问题的记忆机制(memory mechanisms)。
一个更基本的问题是,学会检测长期依赖关系涉及一个根本困难的信用分配问题:在缺乏事先信息的情况下,任何过去的事件都可能是当前事件的原因。诸如记忆机制之类的体系结构特性对隐式先验进行了编码,这可能有助于解决信用分配问题。记忆机制允许模型在任意长的时间范围内记住过去的信息,这样就可以将信用分配给遥远过去的事件。我们试图通过创建一个新的记忆结构来编码一个额外的隐含的时间层次的先验。特别地,我们建议通过嵌套来选择性地访问内存,作为在内存中构建时间层次结构的一种方法。
尽管之前有一些关于分层内存的工作,LSTM(和变体)仍然是顺序任务中最流行的深度学习模型,例如在字符级语言建模中。特别是,默认的堆栈LSTM体系结构使用一组相互堆叠的LSTM来处理数据,一个层的输入是前一层的输出。在这项工作中,我们提出并探索了一种新的嵌套LSTM体系结构(NLSTM),我们将其设想为堆叠LSTM的潜在替代方案。
在NLSTMs中,LSTM内存单元可以访问内部内存,它们可以使用标准的LSTM门选择性地读写内存。这个关键特性允许模型实现一个比传统堆叠LSTM更有效的时间层次结构。在NLSTM中,(外部)记忆细胞可以自由地选择性地将相关的长期信息读写到内部细胞中。相反,在堆叠的LSTMs中,上层激活(类似于内部记忆)被直接访问以产生输出,因此必须包含与当前预测相关的所有短期信息。换句话说,堆叠的LSTM和嵌套的LSTM之间的主要区别是NLSTM实现了对内部内存的选择性访问,这释放了内在记忆去记忆和处理更长的时间尺度上的事件,即使这些事件与当前并不相关。
我们的可视化结果表明,NLSTM的内部记忆实际上比堆叠LSTM中的高级记忆在更长的时间尺度上运行。我们的实验还表明,NLSTMs在广泛的任务范围内优于堆叠LSTMs。
二、Related Work
在神经网络和强化学习的背景下,研究了处理长期依赖的有效时间层次的学习问题。对这一主题的全面回顾超出了我们的范围,我们回顾了最近的一些作品,并着重于我们方法的独特之处。

长时间尺度的学分分配是强化学习的核心问题。RL中的选项框架(Sutton et al., 1999)支持对称为选项的临时抽象操作序列进行长期规划。选择一个选项相当于临时制定一个子策略,然后在每个时间步(或其自己的选项)中选择基本操作。虽然学习选项受到了一些关注(Stolle和Precup, 2002;包括一些最近的基于梯度的方法(Arulkumaran et al., 2016;到目前为止,大多数成功的应用程序都使用了手工制作的选项。
2.1 Deep learning approaches to temporal abstraction
目前,RNNs经常被堆叠在一起,在每个时间步长上形成一个多层前馈网络。Hermans和Schrauwen(2013)认为叠加可能导致更抽象、更长期的特征;Zhang等人(2016)认为情况可能并非如此。与堆叠不同,嵌套还增加了重复深度,这可以提高性能Zhang等(2016)。Pascanu等人(2013)将多层输入、输出或循环连接作为叠加的替代;其深层复发连接可增加复发深度,但并不常用。然而,多层输入连接已被用于最先进的语音识别(Hannun et al., 2014;Amodei等人,2016)系统;这些系统还合并了堆叠的RNNs。
我们的模型基于流行的长短时记忆(LSTM)架构(Hochreiter和Schmidhuber,1997)。LSTMs的隐藏状态包括内部记忆细胞,它们使用身份连接来存储长期记忆。LSTM遗忘/记忆门(Gers et al.,1999)允许记忆通过这些身份连接上的(自适应)乘法衰减被遗忘。
基于LSTMs或受LSTMs启发而提出的各种各样的网络体系结构(Graves等,2007;Cho等人,2014;Chung等,2014;Kalchbrenner等人,2015;Danihelka et al ., 2016;Cheng等,2016)。也许最受欢迎和众所周知的是门控复发单元(GRU) (Cho等,2014;Chung等人,2014)。GRUs功能类似于LSTMs,但它们没有任何内部内存,整个隐藏状态暴露给外部计算单元。这与我们的工作方向相反,我们的工作重点是创造更多的内部记忆 。最近的一些作品也将更多的总隐藏状态分配到内部记忆中(Cheng et al.,2016;但不是以一种涉及嵌套的方式。Greff等(2015);Jozefowicz等(2015)评估LSTMs和GRUs的体系结构变体;Greff等人(2015)删除了标准LSTMs的组件,而Jozefowicz等人(2015)使用进化搜索过程来搜索更大范围的可能模型。
LSTM 记忆门允许该模型以不同的速率动态衰减不同单元的内存,但不明确鼓励不同单元建模不同的时间依赖级别。其他的一些工作试图在递归模型的先验中对时间层次进行编码。单位之间的时间层次结构可以手工显式编码,如Clockwork RNNs (Koutnik et al., 2014)和分级RNNs (Hihi和Bengio, 1996)。这种方法似乎很脆弱;模型最好能学会在适当的时间范围内操作。Chung等人(2015)提出了一种完全可微的方法来解决这个问题,其基础是添加额外的门控机制。这种工作的一个缺点是模型大小在层次结构的层数中呈二次增长。最近,Chung等人(2016)使用直通式估计器(Hinton,2012;(yoshu Bengio, 2013)来训练一个模型,该模型可以对何时更新不同的循环单位做出“清晰”的二进制决策。
最近在深度学习方面的工作考虑使用受计算机内存架构启发的新内存机制来扩展RNN架构(Graves等,2014;Joulin and Mikolov, 2015;Grefenstette et al., 2015)和神经短期记忆机制(Ba et al., 2016)。存储和访问内存为梯度流提供了路径,但是,就像在RNNs中一样,当序列变长时,使用时间反向传播在计算上变得非常昂贵。这个问题的标准解决方案是在一定的时间步长的情况下截断梯度流。Zaremba和Sutskever(2015)尝试在训练神经图灵机(NTMs)的背景下使用强化学习(具体来说,是reinforcement algorithm (Williams, 1992))来解决这个问题。
三、Nested LSTMs
直观上,LSTM 中的输出门会编码仍旧值得记忆的信息,这些记忆可能与当前的时间步骤不相关。嵌套 LSTM 根据这一直观理解来创造一种记忆的时间层级。访问内部记忆以同样的方式被门控,以便于长期信息只有在情景相关的条件下才能选择性地访问。
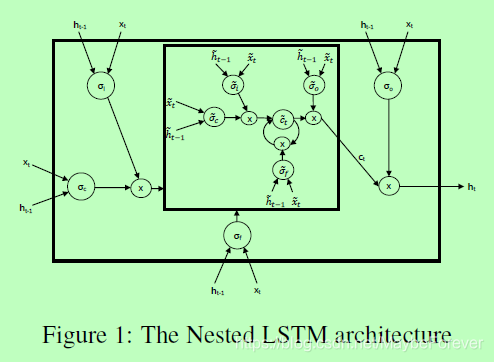
3.1 The architecture
在 LSTM 网络中,单元状态的更新公式和门控机制可以表示为以下方程式:
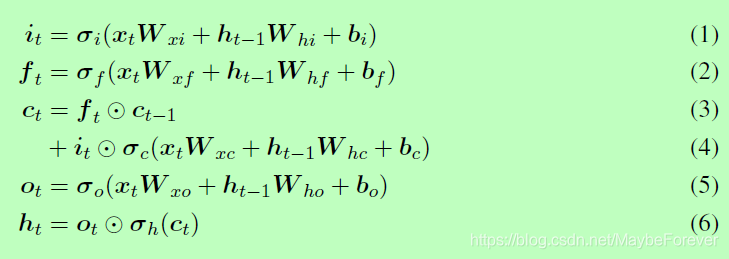
这些方程式与 Graves (2013) 等人定义的是非常相似的,但不包括 peephole 连接。
Nested LSTM 使用已学习的状态函数 ct = mt(ft⊙ct−1, it⊙gt) 来替代 LSTM 中计算 ct 的加运算。我们将函数的状态表示为 m 在时间 t 的内部记忆(inner memory),我们会调用该函数以计算 ct 和 mt+1。我们可以使用另一个 LSTM 单元来实现该记忆函数,因此如上图 1 所示就生成了 Nested LSTM。同样,该记忆函数能够由另一个 Nested LSTM 单元替换,因此就能构建任意深的嵌套网络。
给定以上所述的架构特性,NLSTM 中记忆函数的输入和隐藏状态为:
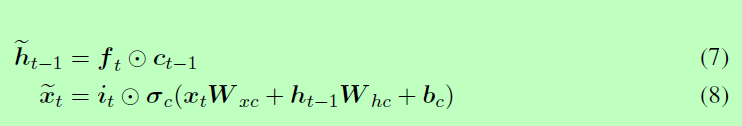
特别的,注意如果记忆函数是加性的,那么整个系统将退化到经典的 LSTM,因此记忆单元的状态更新为:

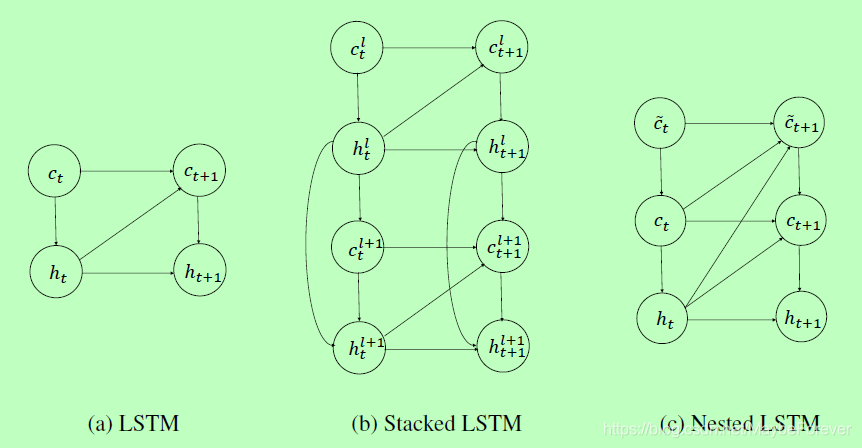
图2:LSTM、堆叠 LSTM 和嵌套 LSTM 的计算图。隐藏状态、外部记忆单元和内部记忆单元分别由 h、c 和 d 表示。当前隐藏状态可以直接影响下一个内部记忆单元的内容,而内部记忆单元只通过外部记忆单元才影响隐藏状态。
在本论文提出的 Nested LSTM 变体架构中,我们会使用 LSTM 作为记忆函数,且内部 LSTM 的运算方式由以下一组方程式控制:
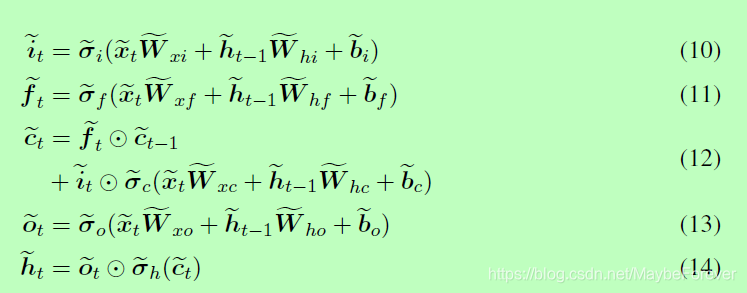
现在,外部 LSTM 的单元状态更新方式为:

四、Experiments
我们评估嵌套的LSTMs对各种数据集和任务:宾夕法尼亚大学树图资料库语料库(Marcus et al ., 1993)和更大的Text8数据集(2011年Mahoney)(代表标准字符级语言建模,Text8远大于宾夕法尼亚大学树图资料库语料库),中国诗生成数据集(张和Lapata, 2014)(这需要字符级语言建模在小得多的序列用更少的时间依赖性比很常见,但字符数显著高于通常在英语),MNIST瞥见任务(Ba et al., 2016)(这是一个分类任务,但它包含时间依赖性)。我们展示了,尽管这些任务代表了不同的场景和目标,嵌套的LSTM始终如一地比相应堆叠的LSTM基线(具有相当数量的参数)提高性能。
在接下来的所有实验中,我们对嵌套的LSTM和堆叠的LSTM基线的超参数进行了相同的初始化。虽然我们明确指定了超参数,但除非另有说明,我们使用的超参数与Krueger等人(2016)使用的超参数相同;Cooijmans等人(2016)。我们首先初始化嵌套和堆叠LSTMs输入盖茨(将输入向量从词汇数量的元素cell_size数量的元素)使用Glorot Glorot初始化方案和Bengio(2010),而所有其他盖茨LSTM(其他输入,记得盖茨和输出,最后输出门)初始化使用正交初始化萨克斯et al。(2013)。
我们还试图通过调整隐藏单元的数量来尽可能接近地匹配不同堆叠的LSTM基线的参数。虽然这在2层叠加的基线中是可能的,但是在单层或3层叠加的LSTM中实现起来稍微困难一些。相应地,我们展示了两个单层LSTMs的结果:一个参数数目与参考文献相同,另一个参数数目比我们的模型大。我们还选择了三层叠加LSTM的隐藏单元数来超过我们模型所使用的参数数。因此,我们的模型与2层叠加的LSTM具有相同数量的参数,相比于较大的单层LSTM和3层叠加的LSTM,我们的模型处于劣势,但是优于所有这些基线。
4.1 Visualization(可视化)
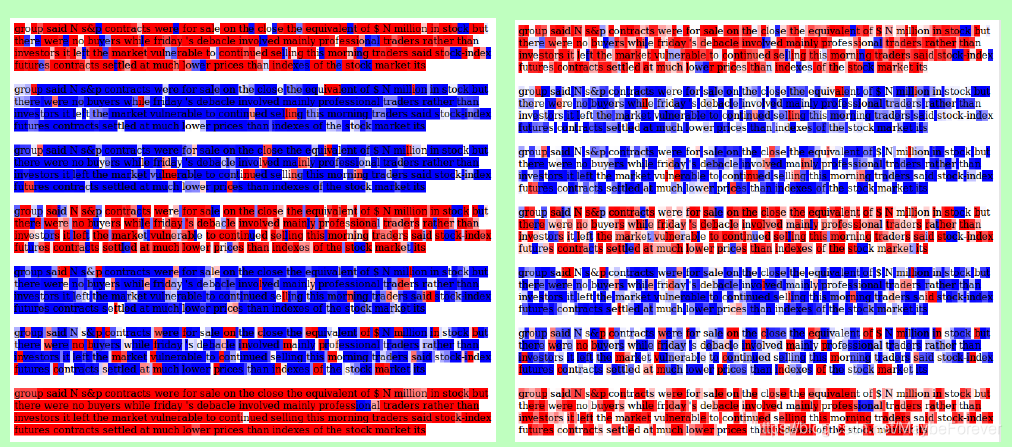
图 3:关于内部单元(图左)和外部单元(图右)的输入特征的单元激活的可视化。红色表示负单元状态值,蓝色表示正单元状态值。更深的颜色表示更大的值。对于内部 LSTM 的状态,对 tanh(ct tilde)进行了可视化(因为 ct tilde 未约束),而对于外部 LSTM 的状态,则直接可视化了 ct。
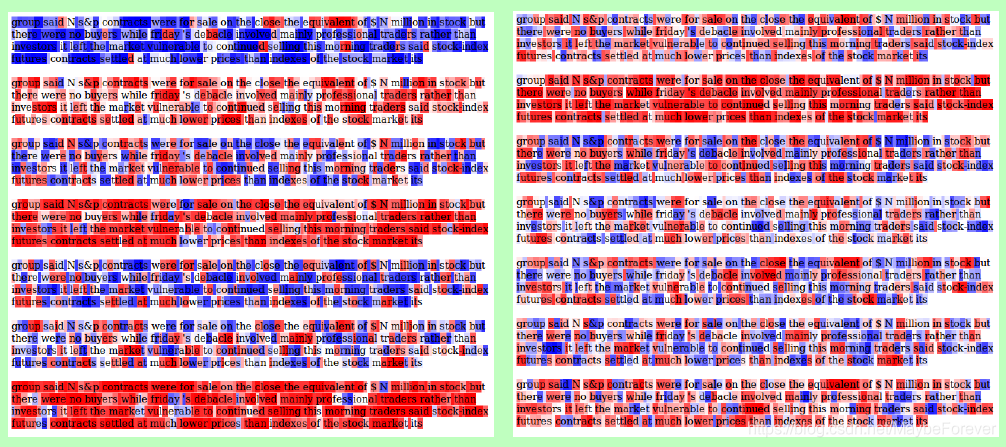
图 4:tanh(ct^n)的可视化,表征第一(图右)和第二(图左)堆栈层的输入字符的单元激活。红色表示负单元状态值,蓝色表示正单元状态值。更深的颜色表示更大的值。
我们在图3中显示了结果的可视化。已经显示了可视化的单元格是模型的前七个单元格。从可视化中,我们可以看到,在许多时间步长中,内部LSTM的细胞激活趋于相对一致,而外部LSTM的细胞激活波动得更快。这个可视化演示了NLSTM层次结构按预期工作:外部内存在更短的时间范围内运行,并使用内部内存存储更长的信息。
我们将其与图4中2层叠加的LSTM基线的类似可视化进行对比。虽然较高的层内存(它离输入“更远”)的运行时间比较低的层内存更长,但它的波动仍然比NLSTM的内部细胞更快。这表明NLSTM能够跨多个嵌套记忆层有选择地处理和记忆信息,从而使模型能够在更长的时间段内记忆信息,并支持我们的直觉,即嵌套记忆结构可以形成更有效的时间层次结构。
4.2 Penn Treebank Character-level Language Modeling
Penn Treebank的数据集(Marcus等人,1993年)包含大约100万个单词,包含一个标准的训练:验证:测试分割。我们在这个数据集上训练模型来执行字符级预测,给定一个输入序列,并测量负对数似然(NLL)损失和每个字符的位(BPC,定义为NLL除以ln2)。
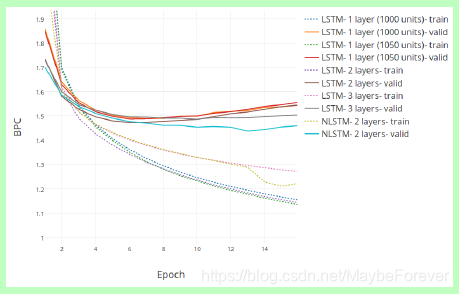
图 5:在 PTB 的测试和验证集上的 BPC(bits per character)vs. Epoch 曲线。
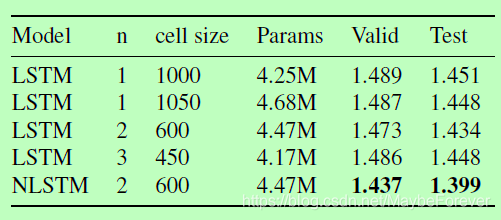
表 1:嵌套 LSTM 和多个基线模型的 BPC 损失的对比。测试(test)的 BPC 损失分别和各个模型在最小验证(valid)BPC 值的 epoch 的损失相关。
4.3 Chinese Poetry Generation
这里,我们使用了中国诗歌生成数据集Zhang和Lapata(2014)的子集,该子集由四行诗组成,每个四行诗有5个字符,标准指定的序列:validation:test split。这个任务与PTB任务有显著的不同:序列长度(结果是8个时间依赖项的长度)要短得多,但是字符数(超过5000个)要大两个数量级。
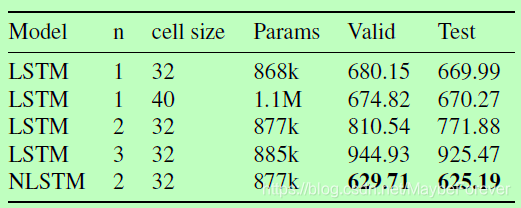
表 2:嵌套 LSTM 和多个基线模型在中文诗歌生成数据集(Chinese Poetry Generation dataset)上的困惑度的对比。
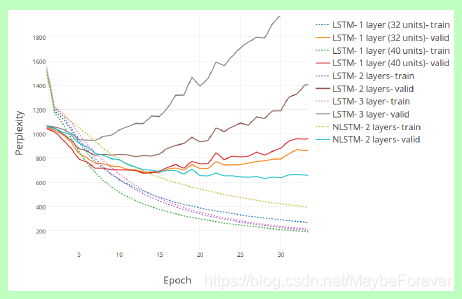
图 6:在中文诗歌生成的测试和验证集上进行字符级预测,Perplexity作为epoch的函数。
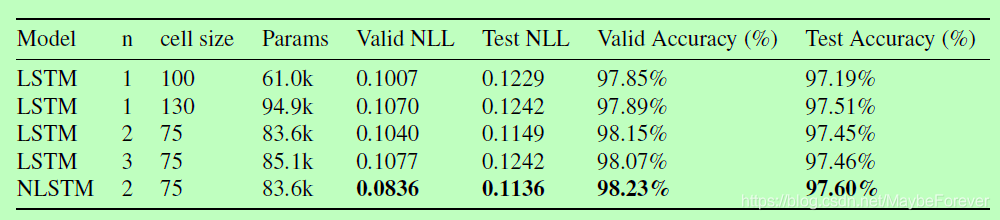
表 3:嵌套 LSTM 和多个基线模型在 MNIST Glimpses 任务上的 NLL(负对数似然度)和准确率的对比。其中采用的 epoch 是每个模型在验证集上有最高准确率的 epoch。和 NLL 相似,模型的验证 NLL 被用于确定测试 NLL 的 epoch。

图 7:在 MNIST Glimpses 的训练集和验证集上的 NLL(图左)和误差率(图右)vs. Epoch 的曲线图。
4.4 MNIST Glimpses
在验证和测试数据集上,嵌套的LSTM在NLL和错误百分比方面都优于(堆叠的)LSTM基线。特别是,与性能次之的模型(从2层堆叠的LSTM的1.85%降至1.77%)相比,它减少了4.3%的验证误差,而验证NLL几乎减少了17%(从单层LSTM的0.1007降至0.0836)。
4.5 text8
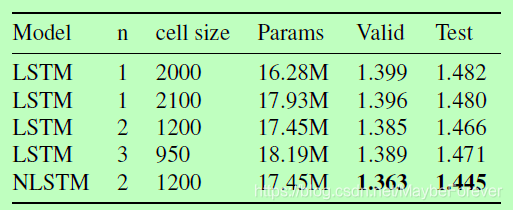
表4:嵌套LSTM的BPC与text8任务的各种基线

图8:text8的训练集和验证集的字符级预测的BPC与epoch曲线
五、Conclusions
嵌套LSTM (NLSTM)是LSTM模型的简单扩展,它通过嵌套而不是堆叠来增加深度。NLSTM的内部内存单元形成一个内部内存,它只能通过外部内存单元访问其他计算元素,实现了一种时间层次结构。在我们的实验中,NLSTMs在参数数量上优于堆叠LSTMs,并且与堆叠LSTMs相比,NLSTMs的记忆细胞激活具有更明确的时间层次。因此,NLSTM是堆叠模型的一个很有前途的替代方案。