10月20日模拟赛题解
A 纸牌
Description
桌面上有 \(n\) 张纸牌,每张纸牌的正反两面各写着一个整数,初始时正面朝上。现在要求你翻动最少的纸牌,使得朝上的数字中最少有一半的数字是相同的,或判断无解。
Limitations
\(1 \leq n \leq 3 \times 10^5\),所有输入数据都是不大于 \(10^9\) 的非负整数。
Solution
签到题,注意到因为要求至少有一半的数字相同,并且一共只有 \(2n\) 个数字,所以最终可以作为相同数字的数不超过 \(4\) 个。用 map/hash 随便维护一下出现次数,然后枚举超过一半的数字,暴力判断即可。
Code
#include <cstdio>
#include <map>
#include <vector>
const int maxn = 300005;
int n, ans = maxn, dn;
int a[maxn], b[maxn];
std::map<int, int> oc;
std::vector<int> ansv;
int main() {
freopen("card.in", "r", stdin);
freopen("card.out", "w", stdout);
qr(n); dn = (n >> 1) + (n & 1);
for (int i = 1; i <= n; ++i) {
qr(a[i]); qr(b[i]);
if (a[i] != b[i]) {
if (++oc[a[i]] == dn) {
ansv.push_back(a[i]);
}
if (++oc[b[i]] == dn) {
ansv.push_back(b[i]);
}
} else {
if (++oc[a[i]] == dn) {
ansv.push_back(a[i]);
}
}
}
if (ansv.size() == 0) {
puts("Impossible");
return 0;
}
for (auto v : ansv) {
int cnt = 0;
for (int i = 1; i <= n; ++i) {
cnt += a[i] == v;
}
ans = std::min(ans, dn - cnt);
}
printf("%d\n", std::max(0, ans));
}B 后缀树组
Description
给定一个长度为 \(n\) 的字符串,对每个位置 \(i\) ,取它和它后面 \((m - 1)\) 个字符共 \(m\) 个字符作为第 \(i\) 个子串。(如果到达结尾,则子串长度为 \(n - i + 1\))。现在将这 \(n\) 个子串按照第一个字符所在的位置排成一排,要将他们按照字典序排序,每次只能交换相邻字符串,求最少交换次数。
Limitations
对于全部的数据,\(1 \leq m \leq n \leq 50000\),字符串只含小写字母
对于前 \(60\%\) 的数据,\(1 \leq n \leq 5000\)。
另有 \(10\%\) 的数据, \(1 \leq m \leq 5\)
另有 \(10\%\) 的数据,字符串随机生成。
Solution
首先的结论是,将一个序列按照不降序排序且只能交换相邻两项,则最优的交换次数是这个序列的逆序对数。证明上可以考虑先将最大的元素移动到序列末尾,所需要的移动次数是该最大元素所贡献的逆序对个数,然后去掉序列末尾元素,对剩下的序列继续排序,以此做数学归纳即可。
因此只要知道每个子串的字典序排名,我们就可以 \(O(n \log n)\) 的求出答案。
考虑前 \(60\%\) 的数据,可以 \(O(nm)\) 的找出每个子串,然后排序,用冒泡去 \(O(n^2)\) 的求出逆序对个数。不过大概只有 zxy 这个 sb 会拿冒泡去求逆序对了(
对于 \(m \leq 5\) 的数据,排好序用 BIT 或者 mergesort 求一下就好了。
对于字符串随机的数据,我们注意到在比较字典序的时候,第一个字符相同从而进入下一位比较的概率是 \(\frac{1}{25 \times 26}\),再进行一位比较的概率是上面这个概率的平方,类似的,我们发现每次期望比较的次数非常小,不会超过 \(5\),因此排序的时间复杂度就是 \(O(nT \log n)\),其中 \(T\) 是字符串随机意义下期望的两串比较次数。但是注意到把所有的字串都求出来会爆空间,所以直接在原串上扫就行了。不够大概只有 zxy 这个 铁憨憨 会把所有的子串都求出来叭(
对于全部的数据,我们考虑比较两个字符串字典序的过程,从前往后扫两个串的前缀,只要有某个长度使得两个串在该长度对应字符不同,就可以通过这个字符来比较两个串的字典序,因此我们考虑找到两个字符串的第一个不同的前缀。而这个前缀的长度是可以二分的,即若找到了某个长度使得两个串的该长度前缀长度不同,第一个不同的前缀的长度一定不大于这个长度,否则第一个不同的前缀长度一定大于这个长度。
而判断两个串的前缀是否相同可以用HASH来解决。这样就可以做到时间复杂度 \(O(n \log n \log m)\) 了,其中 \(O(\log m)\) 是二分的复杂度。
至于怎么求一个优秀的与字符顺序有关但是与字符位置无关(因为要求 \(ab\) 和 \(ba\) 不同,要求与顺序有关,但是如 \(abab\),要求判断前两个字符组成的字符串与后两个字符组成的字符串相同,要求与字符位置无关)的 hash 函数,可以对原串 hash 一遍,然后对原串的差分 hash 一遍,然后对原串的二阶差分 hash 一遍,一直 hash 下去就好了(
Code
(80 pts)
#include <cstdio>
#include <algorithm>
typedef long long int ll;
const int maxn = 50005;
int n, m, ans;
int v[maxn], w[maxn];
char S[maxn];
struct BIT {
int A[maxn];
inline int lowbit(const int x) { return x & -x; }
inline void update(int x, const int v) { do A[x] += v; while ((x += lowbit(x)) <= n); }
inline int query(int x) { int _ret = 0; do _ret += A[x]; while (x -= lowbit(x)); return _ret; }
};
BIT tree;
bool cmp(const int &a, const int &b);
int main() {
freopen("sort.in", "r", stdin);
freopen("sort.out", "w", stdout);
scanf("%d %d\n%s", &n, &m, S + 1);
for (int i = 1; i <= n; ++i) { v[i] = i; }
std::sort(v + 1, v + 1 + n, cmp);
for (int i = 1; i <= n; ++i) {
w[v[i]] = i;
}
for (int i = 1; i <= n; ++i) {
ans += tree.query(n) - tree.query(w[i]);
tree.update(w[i], 1);
}
qw(ans, '\n', true);
return 0;
}
inline bool cmp(const int &a, const int &b) {
for (int len = 1, i = a, j = b; len <= m; ++i, ++j, ++len) {
if ((i > n) || (j > n)) {
return i > n;
} else if (S[i] != S[j]) {
return S[i] < S[j];
}
}
return a < b;
}(std)
#include <cstdio>
#define mo 1000000007
#define N 50055
int f[N],s[N],tmp[N],n,m,i,ch,ans;
long long hash[N],pow[N];
//二分+哈希求以i开头的和以j开头的两个子串哪个字典序更小
bool lessThanOrEqual(int i, int j)
{
if (i == j) return true;
int l, r, k;
long long hsi, hsj;
//二分求i和j开始从左向右第一位不同的位
l = 0;
r = m+1;
if (n-j+2 < r) r = n-j+2;
if (n-i+2 < r) r = n-i+2;
while (r-l > 1)
{
k = (l+r)/2;
//子串[i,i+k-1]的哈希值
hsi = hash[i+k-1]-hash[i-1]*pow[k]%mo;
if (hsi < 0) hsi += mo;
//子串[j,j+k-1]的哈希值
hsj = hash[j+k-1]-hash[j-1]*pow[k]%mo;
if (hsj < 0) hsj += mo;
if (hsi == hsj) l = k; else r = k;
}
//s[i+l]和s[j+l]是第一位不同的位
if (l == m) return true;
return s[i+l] < s[j+l];
}
//归并排序
void sort(int l, int r)
{
if (l == r) return;
int mi = (l+r)/2;
sort(l, mi);
sort(mi+1, r);
int i=l, j=mi+1;
int nt = l;
while (i<=mi || j<=r)
{
bool ilej;
if (i > mi) ilej = false;
else
if (j > r) ilej = true;
else ilej = lessThanOrEqual(f[i],f[j]);
if (ilej) tmp[nt++] = f[i++];
else
{
tmp[nt++] = f[j++];
//从右区间取数时,右区间和左区间之间产生了继续对
//累加答案
ans += mi-i+1;
}
}
for (i=l; i<=r; ++i) f[i] = tmp[i];
}
int main()
{
freopen("sort.in", "r", stdin);
freopen("sort.out", "w", stdout);
scanf("%d%d", &n, &m);
hash[0] = 0;
pow[0] = 1;
for (i=1; i<=n; ++i)
{
for (ch=getchar(); ch<=32; ch=getchar());
s[i] = ch-96;
//预处理hash[i]=子串[1,i]的哈希值
hash[i] = (hash[i-1]*29+s[i])%mo;
//预处理pow[i]=29^i
pow[i] = pow[i-1]*29%mo;
f[i] = i;
}
s[n+1] = 0;
sort(1, n);
printf("%d\n", ans);
return 0;
}C 巧克力
有一块分成 \(n \times m\) 个格子的矩形巧克力,虽然形状上很规整但质量分布并不均匀,每一格有各自的重量 \(w_{i, j}\),用 \(n \times m\) 个正整数表示。你需要将这一整块巧克力切成 \(k\) 小块,要求每块都是矩形,且它们的重量分别为 \(a_1 \sim a_k\)。一块巧克力的重量等于它包含的所有格子的重量之和。
切巧克力的时候,你可以每次选一块大的巧克力,沿着某条格线横向或纵向将其切成两块小的巧克力。切下来的小块巧克力可以继续切割。切割路线不能是折线或斜线。任何时候当前的所有巧克力块都必须是矩形的。
对于给定的巧克力和分割要求,请你判断是否存在一个切割方案满足上述要求。
共有 \(T\) 组数据,时限 \(2s\)。
Limitations
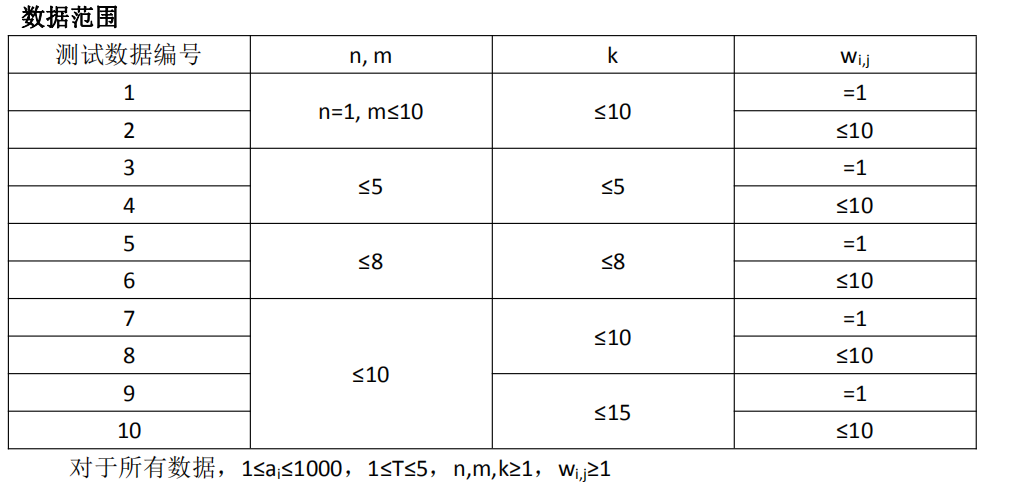
Solution
Algorithm \(1\)
判断一下 a 加起来是否等于 \(m\),当 \(w\) 恒等于 \(1\) 且只有一行的时候,只要按照 \(a\) 去一个一个切即可。
可过测试点:\(1\)。期望得分 \(10~pts\)
Algorithm \(2\)
爆搜切几刀从哪里切,注意到每切一块都会有一块新的巧克力产生,因此最多切 \(k\) 刀,而对于每块巧克力,都只有 \(O(n + m)\) 种切法,因此搜索树的深度为 \(k\),每个节点有 \((n + m)\) 个孩子。爆搜的复杂度为 \(O(T~(n + m) ^ k)\)。
可通过测试点:\(1,~2,~3,~4\),期望得分 \(40~pts\)
Algorithm \(3\)
像 zxy 那个 铁憨憨 一样读错题,以为每切一刀都必须满足一个 \(a\),然后写个垃圾爆搜,也能得到 \(40 pts\)。
Algorithm \(4\)
注意到 \(k\) 非常小,因此非常适宜状压。
设 \(f_{i, j, x, y, S}\) 为左上角为 \((i, j)\),右下角为 \((x,~y)\) 的矩形,是否满足 \(a\) 的状态为 \(S\) 的情况,转移只要枚举那一刀在哪里切得满足了哪些情况即可。写成记搜非常好写。
时间复杂度 \(O(T n^2 m^2 (n + m) 3^k)\)。空间复杂度 \(O(n^2m^2 \times 3^k)\)。
可通过测试点:\(1~\sim 6\),期望得分 \(60~pts\)
Algorithm \(5\)
注意到复杂度的瓶颈在状态数上,考虑优化状态。
我们发现对于一个确定了左上角和右上角的矩形,如果再确定了它要满足的 \(a\) 之和,那么他的左下角和右下角就可以确定了。因此我们发现只要确定了 \(i,~j,~x\) 和 \(S\),那么 \(y\) 就可以被确定了,因此在搜索的时候将矩形和不等于 \(S\) 状态下 \(a\) 之和的状态剪掉,那么搜到的状态数就变成了 \(O(n^2 m \times 2^k)\) 。
于是这样的时间复杂度 \(O(T \times n^2 \times m\times (n + m) \times 3^k)\)。
可通过测试点:\(1~\sim 8\),期望得分 \(80~pts\)。
Algorithm \(6\)
对于 \(w = 1\) 的点,我们注意到相当于拿一些小矩形拼成这样一个大矩形。由于各个小矩形完全相同,我们不需要记录具体该矩形是第几行第几列。因此可以设 \(f_{i, j, S}\) 是长为 \(i\),宽为 \(j\) 的矩形,能否拼出状态为 \(S\) 的 \(a\),转移时依然可以枚举这一刀是怎么切的。
时间复杂度 \(O(n \times m \times (n + m) \times 3^k)\)。
可通过测试点:\(1,~3,~5,~7,~9\),期望得分 \(50~pts\)。
Algorithm \(7\)
注意到在转移的时候,我们已经枚举了转移到哪个集合,那么我们就不再需要去枚举从哪里切这一刀,因为a的和是确定的,竖向和横向都最多只有一种切刀的方法,具体在哪里切这一刀,可以二分这个位置。这样转移的复杂度就被优化到了 \(O(\log m)\)。总时间复杂度 \(O(n^2 m 3^k \log m)\)。可以通过全部的测试点。
期望得分 \(100~pts\)。
Code
(80分)
#include <cstdio>
#include <cstring>
typedef long long int ll;
const int maxn = 11;
const int maxt = 1030;
bool vis[maxn][maxn][maxn][maxn][maxt], frog[maxn][maxn][maxn][maxn][maxt];
int n, m, k, T;
int MU[maxn][maxn], A[maxn], sum[maxn][maxn], val[maxt];
void work();
void clear();
bool dfs(const int x, const int y, const int z, const int w, const int S);
int main() {
freopen("chocolate.in", "r", stdin);
freopen("chocolate.out", "w", stdout);
qr(T);
while (T--) {
clear();
work();
}
return 0;
}
void clear() {
memset(A, 0, sizeof A);
memset(MU, 0, sizeof MU);
memset(val, 0, sizeof val);
memset(vis, 0, sizeof vis);
memset(sum, 0, sizeof sum);
memset(frog, 0, sizeof frog);
n = m = k = 0;
}
void work() {
qr(n); qr(m); qr(k);
for (int i = 1; i <= n; ++i) {
for (int j = 1; j <= m; ++j) {
qr(MU[i][j]);
sum[i][j] = sum[i - 1][j] + sum[i][j - 1] - sum[i - 1][j - 1] + MU[i][j];
}
}
for (int i = 0; i < k; ++i) {
qr(A[i]);
}
int ALL = (1 << k) - 1;
for (int S = 1; S <= ALL; ++S) {
for (int i = 0; i < k; ++i) if (S & (1 << i)) {
val[S] += A[i];
}
}
puts(dfs(1, 1, n, m, ALL) ? "yes" : "no");
}
bool dfs(const int x, const int y, const int z, const int w, const int S) {
bool &thisv = vis[x][y][z][w][S], &thisf = frog[x][y][z][w][S];
if (thisv) { return thisf; }
thisv = true;
if ((sum[z][w] - sum[x - 1][w] - sum[z][y - 1] + sum[x - 1][y - 1]) != val[S]) {
return false;
}
if ((S & (S - 1)) == 0) {
return thisf = true;
}
for (int i = x; i < z; ++i) {
for (int S0 = S; S0; S0 = (S0 - 1) & S) if (dfs(x, y, i, w, S0) && dfs(i + 1, y, z, w, S ^ S0)) {
return thisf = true;
}
}
for (int i = y; i < w; ++i) {
for (int S0 = S; S0; S0 = (S0 - 1) & S) if (dfs(x, y, z, i, S0) && dfs(x, i + 1, z, w, S ^ S0)) {
return thisf = true;
}
}
return false;
}(std)
#include <cstdio>
#include <list>
#define MAXK 15
#define N 11
struct Quad
{
int a, b, c, d;
Quad(int _a, int _b, int _c, int _d): a(_a), b(_b), c(_c), d(_d) {}
};
std::list<Quad> lf, lfx, lfy;
char f[N][N][N][1<<MAXK],fx[N][N][N][1010],fy[N][N][N][1010];
int sumx[N][N][N],sumy[N][N][N],suma[1<<MAXK],bg[1<<MAXK],ed[1<<MAXK],c[15000000],e[MAXK+1],a[20],
n,m,K,i,j,l,r,T,sta,nc,w;
/*
求:以j1为左边界、j2为右边界、i1为上边界的矩形中,下边界为多少的矩形
重量和是w。如果不存在则返回-1
用二分求
*/
int calcx(int j1, int j2, int i1, int w)
{
// fx[j1][j2][i1][w]用于记录该子问题有没有被求结果
// 已求结果则直接返回结果
if (fx[j1][j2][i1][w] != 0) return fx[j1][j2][i1][w];
// 未求结果,将该状态加入待清空队列
lfx.push_back(Quad(j1,j2,i1,w));
// 二分求i2的位置
int l, r, k;
l = i1-1;
r = n+1;
while (r-l > 1)
{
k = l+r>>1;
if (sumx[j1][j2][k]-sumx[j1][j2][i1-1] <= w) l = k; else r = k;
}
if (sumx[j1][j2][l]-sumx[j1][j2][i1-1] != w) l = -1;
return fx[j1][j2][i1][w]=l;
}
/*
求:以i1为上边界、i2为下边界、j1为左边界的矩形中,右边界为多少的矩形
重量和是w。如果不存在则返回-1
和上面对称
*/
int calcy(int i1, int i2, int j1, int w)
{
if (fy[i1][i2][j1][w] != 0) return fy[i1][i2][j1][w];
lfy.push_back(Quad(i1,i2,j1,w));
int l, r, k;
l = j1-1;
r = m+1;
while (r-l > 1)
{
k = l+r>>1;
if (sumy[i1][i2][k]-sumy[i1][i2][j1-1] <= w) l = k; else r = k;
}
if (sumy[i1][i2][l]-sumy[i1][i2][j1-1] != w) l = -1;
return fy[i1][i2][j1][w]=l;
}
/*
求(i1,j1)~(i2,j2)的矩形能否切出sta中的巧克力
*/
bool work(int i1, int i2, int j1, int j2, int sta)
{
//记忆化:求过了则直接返回
if (f[i1][i2][j1][sta] != 0) return f[i1][i2][j1][sta]==1;
if (bg[sta] == ed[sta]) return true;
//未求过,将该状态加入待清空队列
lf.push_back(Quad(i1,i2,j1,sta));
int i, sta2, x, y;
//枚举sta的每个非空真子集
for (i=bg[sta]; i<ed[sta]; ++i)
{
sta2 = c[i];
//尝试横向切
x = calcx(j1,j2,i1,suma[sta2]);
if (x != -1)
if (work(i1,x,j1,j2,sta2) && work(x+1,i2,j1,j2,sta-sta2))
{
f[i1][i2][j1][sta] = 1;
return true;
}
//尝试纵向切
y = calcy(i1,i2,j1,suma[sta2]);
if (y != -1)
if (work(i1,i2,j1,y,sta2) && work(i1,i2,y+1,j2,sta-sta2))
{
f[i1][i2][j1][sta] = 1;
return true;
}
}
f[i1][i2][j1][sta] = -1;
return false;
}
void dfs(int sta, int t)
{
if (t == MAXK)
{
if (sta > 0) c[nc++] = sta;
return;
}
if (sta&e[t]) dfs(sta-e[t], t+1);
dfs(sta, t+1);
}
int main()
{
freopen("chocolate.in", "r", stdin);
freopen("chocolate.out", "w", stdout);
e[0] = 1;
for (i=1; i<=MAXK; ++i) e[i] = e[i-1]*2;
//预处理每个sta有哪些非空真子集,连续存储在队列c中
nc = 1;
for (sta=1; sta<e[MAXK]; ++sta)
{
bg[sta] = nc; //bg表示sta的子集在c中的开头位置
dfs(sta, 0); //dfs求sta的非空真子集
--nc;
ed[sta] = nc; //ed表示sta的子集在c中的结尾位置
}
scanf("%d", &T);
while (T--)
{
scanf("%d%d%d", &n, &m, &K);
for (i=1; i<=n; ++i)
for (j=1; j<=m; ++j)
{
scanf("%d", &w);
//sumy[i][j][k]:从第i行到第j行,从第1列到第k列构成的矩形的重量和
sumy[i][i][j] = sumy[i][i][j-1]+w;
//sumx[i][j][k]:从第i列到第j列,从第1行到第k行构成的矩形的重量和
sumx[j][j][i] = sumx[j][j][i-1]+w;
}
for (l=1; l<n; ++l)
for (r=l+1; r<=n; ++r)
for (j=1; j<=m; ++j) sumy[l][r][j] = sumy[l][r-1][j]+sumy[r][r][j];
for (l=1; l<m; ++l)
for (r=l+1; r<=m; ++r)
for (i=1; i<=n; ++i) sumx[l][r][i] = sumx[l][r-1][i]+sumx[r][r][i];
for (i=1; i<=K; ++i) scanf("%d", &a[i]);
//求出{ai}的各个子集的重量和
//suma[sta]:sta中的巧克力的总重量
for (sta=0; sta<e[K]; ++sta)
{
suma[sta] = 0;
for (i=sta, j=1; i>0; i>>=1, ++j)
if (i&1) suma[sta] += a[j];
}
// 如果所有ai的总重量!=巧克力的总重量
if (suma[e[K]-1] != sumy[1][n][m])
{
printf("no\n");
continue;
}
//lf、lfx、lfy用于记录哪些状态被记忆化了,用于之后清零
lf.clear();
lfx.clear();
lfy.clear();
if (work(1,n,1,m,e[K]-1)) printf("yes\n");
else printf("no\n");
//清零记忆化过的状态
for (std::list<Quad>::iterator it=lf.begin(); it!=lf.end(); ++it) f[it->a][it->b][it->c][it->d] = 0;
for (std::list<Quad>::iterator it=lfx.begin(); it!=lfx.end(); ++it) fx[it->a][it->b][it->c][it->d] = 0;
for (std::list<Quad>::iterator it=lfy.begin(); it!=lfy.end(); ++it) fy[it->a][it->b][it->c][it->d] = 0;
}
return 0;
}