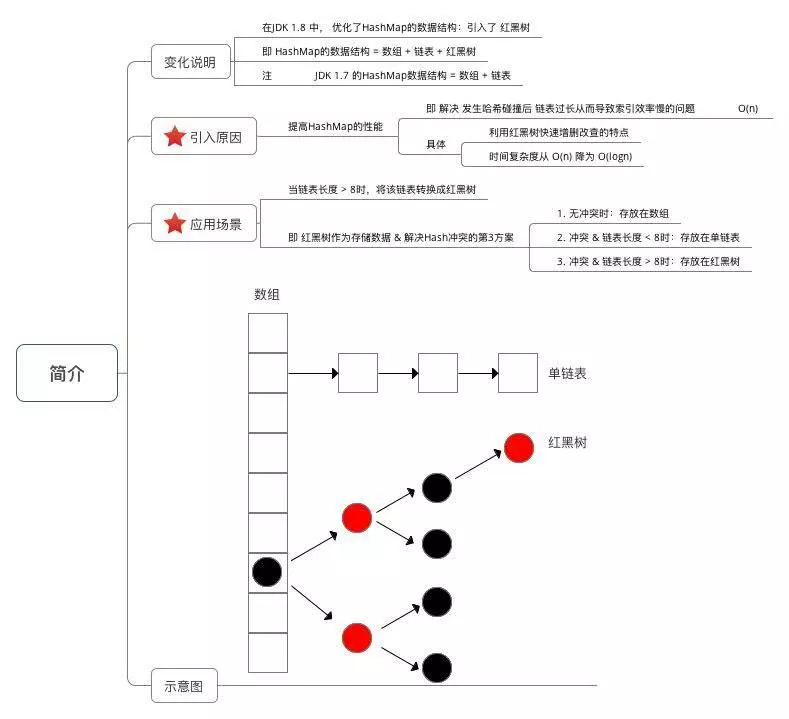
1.0 数据结构
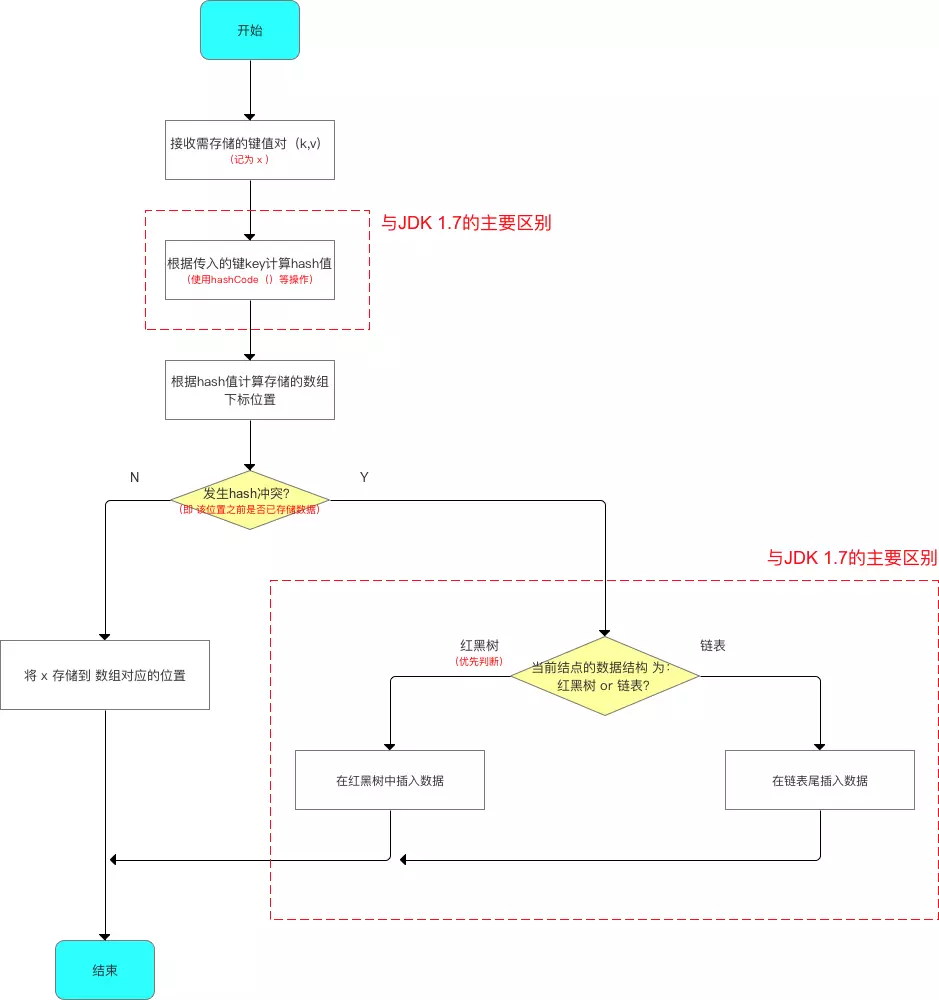
2.0 存储流程
3.0 数组元素 & 链表节点的实现类
HashMap中的数组元素 & 链表节点 采用 Node类 实现,与jdk1.7相比只是把Entry换了个名字
HashMap中的红黑树节点 采用 TreeNode 类 实现
/** * 红黑树节点 实现类:继承自LinkedHashMap.Entry<K,V>类 */ static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> { // 属性 = 父节点、左子树、右子树、删除辅助节点 + 颜色 TreeNode<K,V> parent; TreeNode<K,V> left; TreeNode<K,V> right; TreeNode<K,V> prev; boolean red; // 构造函数 TreeNode(int hash, K key, V val, Node<K,V> next) { super(hash, key, val, next); } // 返回当前节点的根节点 final TreeNode<K,V> root() { for (TreeNode<K,V> r = this, p;;) { if ((p = r.parent) == null) return r; r = p; } }
4.0 源码分析
4.1 hash扰动函数的变更

4.2put函数变更
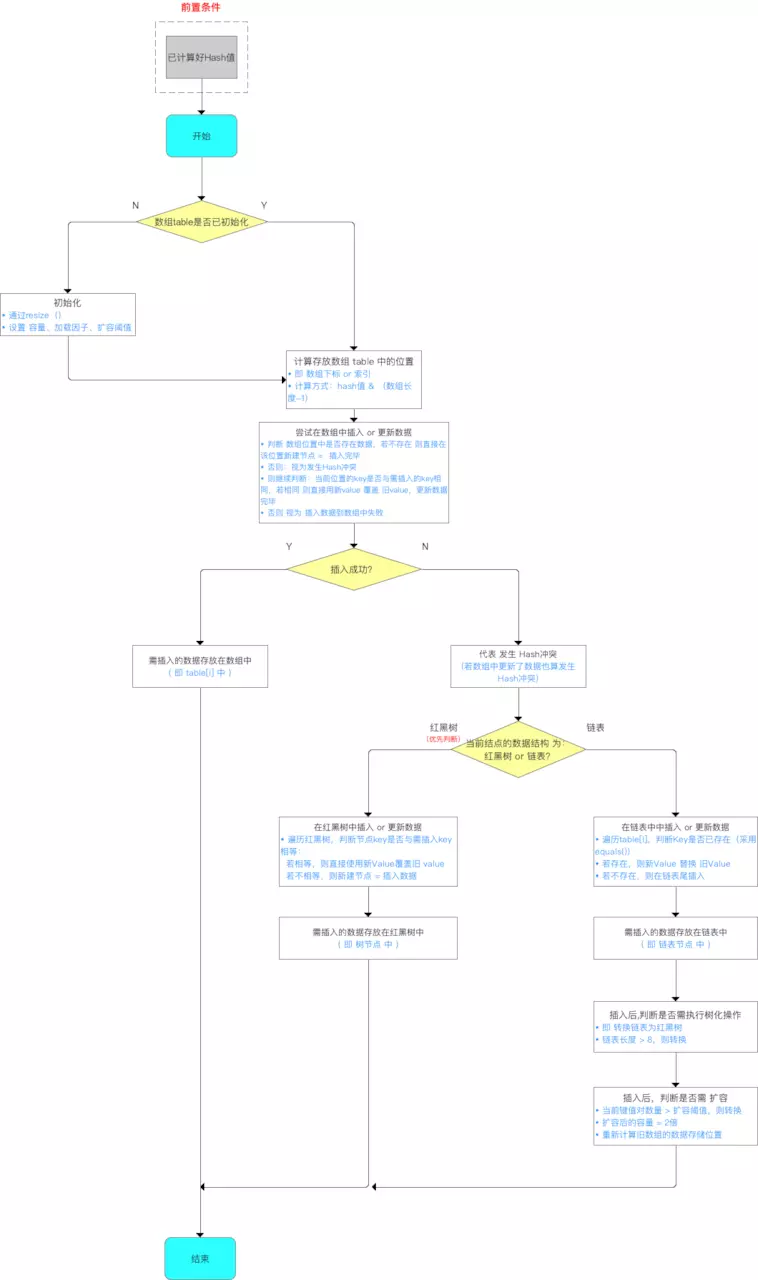
/** * 分析2:putVal(hash(key), key, value, false, true) */ final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; // 1. 若哈希表的数组tab为空,则 通过resize() 创建 // 所以,初始化哈希表的时机 = 第1次调用put函数时,即调用resize() 初始化创建 // 关于resize()的源码分析将在下面讲解扩容时详细分析,此处先跳过 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; // 2. 计算插入存储的数组索引i:根据键值key计算的hash值 得到 // 此处的数组下标计算方式 = i = (n - 1) & hash,同JDK 1.7中的indexFor(),上面已详细描述 // 3. 插入时,需判断是否存在Hash冲突: // 若不存在(即当前table[i] == null),则直接在该数组位置新建节点,插入完毕 // 否则,代表存在Hash冲突,即当前存储位置已存在节点,则依次往下判断:a. 当前位置的key是否与需插入的key相同、b. 判断需插入的数据结构是否为红黑树 or 链表 if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); // newNode(hash, key, value, null)的源码 = new Node<>(hash, key, value, next) else { Node<K,V> e; K k; // a. 判断 table[i]的元素的key是否与 需插入的key一样,若相同则 直接用新value 覆盖 旧value // 判断原则:equals() if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; // b. 继续判断:需插入的数据结构是否为红黑树 or 链表 // 若是红黑树,则直接在树中插入 or 更新键值对 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); ->>分析3 // 若是链表,则在链表中插入 or 更新键值对 // i. 遍历table[i],判断Key是否已存在:采用equals() 对比当前遍历节点的key 与 需插入数据的key:若已存在,则直接用新value 覆盖 旧value // ii. 遍历完毕后仍无发现上述情况,则直接在链表尾部插入数据 // 注:新增节点后,需判断链表长度是否>8(8 = 桶的树化阈值):若是,则把链表转换为红黑树 else { for (int binCount = 0; ; ++binCount) { // 对于ii:若数组的下1个位置,表示已到表尾也没有找到key值相同节点,则新建节点 = 插入节点 // 注:此处是从链表尾插入,与JDK 1.7不同(从链表头插入,即永远都是添加到数组的位置,原来数组位置的数据则往后移) if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); // 插入节点后,若链表节点>数阈值,则将链表转换为红黑树 if (binCount >= TREEIFY_THRESHOLD - 1) treeifyBin(tab, hash); // 树化操作 break; } // 对于i if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; // 更新p指向下一个节点,继续遍历 p = e; } } // 对i情况的后续操作:发现key已存在,直接用新value 覆盖 旧value & 返回旧value if (e != null) { V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); // 替换旧值时会调用的方法(默认实现为空) return oldValue; } } ++modCount; // 插入成功后,判断实际存在的键值对数量size > 最大容量threshold // 若 > ,则进行扩容 ->>分析4(但单独讲解,请直接跳出该代码块) if (++size > threshold) resize(); afterNodeInsertion(evict);// 插入成功时会调用的方法(默认实现为空) return null; } /** * 分析3:putTreeVal(this, tab, hash, key, value) * 作用:向红黑树插入 or 更新数据(键值对) * 过程:遍历红黑树判断该节点的key是否与需插入的key 相同: * a. 若相同,则新value覆盖旧value * b. 若不相同,则插入 */ final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab, int h, K k, V v) { Class<?> kc = null; boolean searched = false; TreeNode<K,V> root = (parent != null) ? root() : this; for (TreeNode<K,V> p = root;;) { int dir, ph; K pk; if ((ph = p.hash) > h) dir = -1; else if (ph < h) dir = 1; else if ((pk = p.key) == k || (k != null && k.equals(pk))) return p; else if ((kc == null && (kc = comparableClassFor(k)) == null) || (dir = compareComparables(kc, k, pk)) == 0) { if (!searched) { TreeNode<K,V> q, ch; searched = true; if (((ch = p.left) != null && (q = ch.find(h, k, kc)) != null) || ((ch = p.right) != null && (q = ch.find(h, k, kc)) != null)) return q; } dir = tieBreakOrder(k, pk); } TreeNode<K,V> xp = p; if ((p = (dir <= 0) ? p.left : p.right) == null) { Node<K,V> xpn = xp.next; TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn); if (dir <= 0) xp.left = x; else xp.right = x; xp.next = x; x.parent = x.prev = xp; if (xpn != null) ((TreeNode<K,V>)xpn).prev = x; moveRootToFront(tab, balanceInsertion(root, x)); return null; } } }