什么是HashMap
hashMap在我们的编程中,应用非常广范。那么HashMap内部到底是怎么存储数据呢,我们先来看看下图。
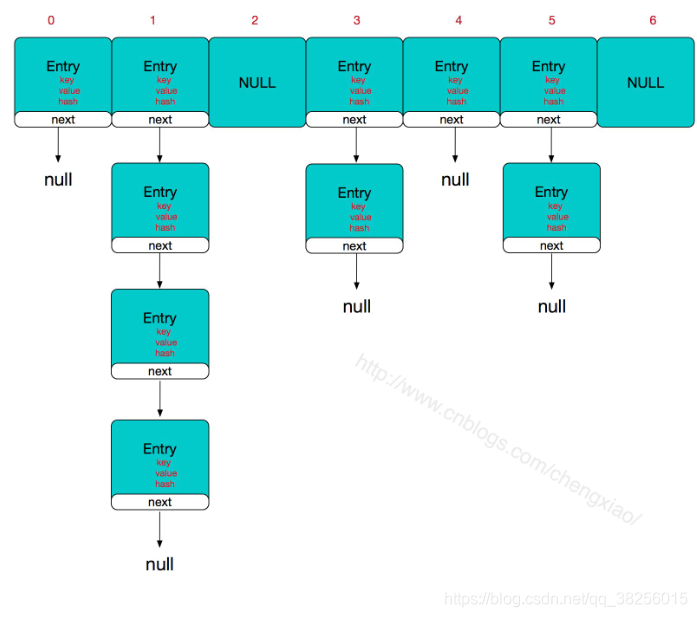
HashMap是通过维护数组和链表的方式,来存储数据。在上图中X轴是数组,每个数组包含一个链表,通过hash值在查找数组的索引和插入数据。
HashMap基本原理
- 我们在向HashMap中插入一个数据时,首先会判断key是否为空,为空则查找Entry[0],不为null,则根据key.hashcode()计算二次Hash值。
- 根据Hash值对数组长度求余,找到对应的索引index。
- 找到对应的数组索引后,然后key值对应的数据插入链表。
HashMap源码分析
首先,我们会通过new一个HashMap的方式创建一个HashMap对象。这时,会创建HashMpa的数据大小。需要注意的是,我们在查找数据索引时,是通过按位与的方式,所以数组的大小为2的N次方。
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}
在上面的代码中,我们通过一个while循环,向左移位capacity变量来确定数组大小。
数组创建好后,我们会向HashMap中插入数据。插入数据是根据key的hash值来判断插入的位置。前面提到过,插入的索引是通过二次hash值对数组长度求余得到的。
static int indexFor(int h, int length) {
return h & (length-1);
}
那么二次hash的过程是什么呢?我们首先会调用key.hashcode方法,将得到的值传入hash方法中,得到二次hash值。
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
在这里有一个默认规则选择31,是因为31是一个奇素数,它在做乘法的时候可以被移位和减法代替,有更好的性能。
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
二次Hash的原因是因为在做位与操作时,总是从低位计算,数组长度确定的情况下,高位为0。那么,在hash值大于数组长度时,高位不会参与运算,会导致数据堆积在一个数组上,降低性能。
解决Hash冲突的方法有以下几种:
1.开发地址法
2.再哈希发
3.链地址法(HashMap采用这种方法)
4.建立公共溢出区
HashMap的put方法
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
插入数据时,会判断key是否为空,为空则调用putForNullKey方法。在该方法中,获取第一个数组的链表,如果该链表中存在某个结点的key值为null,就替换成新结点,并返回旧结点。否则创建一个新的结点。
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
当key不为null时,根据key值二次hash计算索引。判断链表中的结点的hash值和key值是否匹配要插入的数据,如果这两个值都匹配上,说明该链表中存在该结点,则替换这个结点,并返回旧结点。否则,创建一个新的结点。
在插入数据后,modCount++,这个属性是被volatile修饰的,那么该数据改变时,其他线程也会看见。在HashMap的迭代过程中,会先将该值赋值,并在后续操作中,先判断被赋值的数是否等于modCount,不等于则说明其他线程修改了modCount,并抛出异常。
创建一个新结点的方法如下
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
HashMap的get方法
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
这这里,我们需要提醒的是,HashMap是非安全性的,当多线程操作时,可能导致死循环。如果一个线程在查询一个数据时,另外一个线程删除了该结点,会导致无法查找到结点,一直循环下去。get方法也是根据二次hash的索引值,匹配hash值和key值是否相等,匹配成功返回value。