经常出现文档显示乱码,探究一下背后的原因。
ASCII
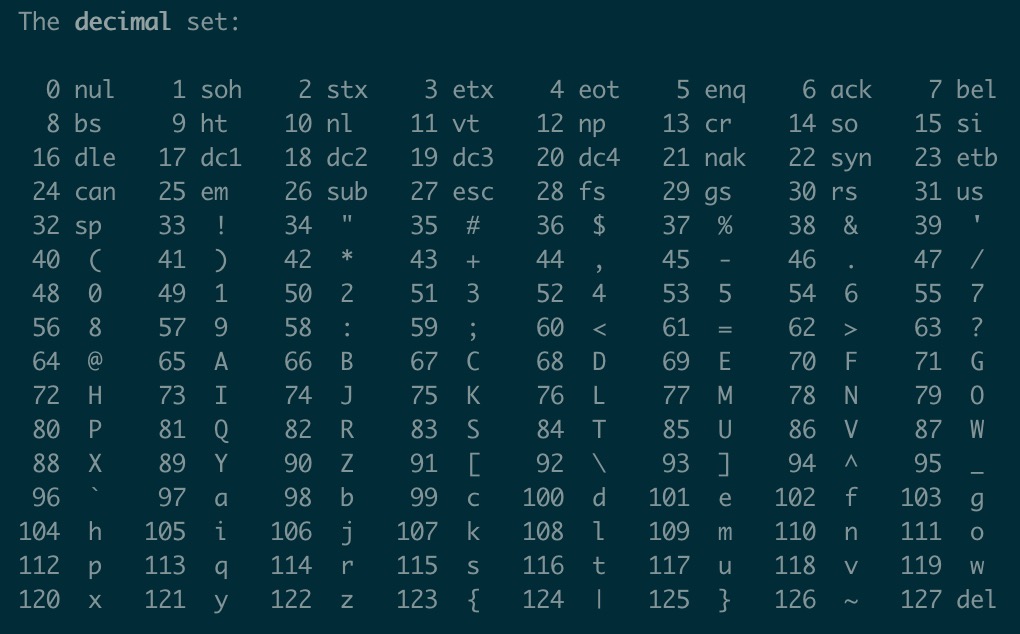
最早计算机发明的时候只用显示英文加一些符号,一个字节就够用了,这就是ASCII码,规定了一个字节范围类字符与二进制数值之间的映射关系,在终端下执行man ascii,即可看到下表。比如字符A对应的值是65二进制(01000001)。
GB2312,GBK,GB18030
单个字节最多只能表示256个字符,这就表示不了汉字了,于是出现了双字节字符集,用两个字节表示一个汉字。GB2312是上世纪80年代出现的,主要收录简体汉字和符号;90年代出现GBK,扩展了繁体字等;2000年后出现了GB18030,收录了少数民族文字。GB字符集是向前兼容的。
Unicode
GB字符集解决了汉字显示的问题,但没有解决在一个文档中同时显示多种文字的问题,如同时在一个文档中显示中文与日文,Unicode字符集就是为了解决这个问题而出现的。它收录了人类所有的字符,每个字符都有一个唯一的二进制编码,这就解决了在同一份文档中显示所有文字的问题。
UTF-8
Unicode只规定了字符的编码,但并没有规定这些编码怎么存储,有的字符对应15个比特位,有的字符则对应30个比特位。于是出现了多种编码方式,如UTF-8,UTF-16,UTF-32,其中UTF-8是一种变长编码方式,最能节省空间,已成为Unicode编码方式的事实标准。
总结
GB编码与Unicode是不同的字符编码集,它们之间毫无关系。文档出现乱码就是读取文档时使用的编码方式与文档实际存储的编码方式不一致导致的。