1. 创建表
CREATE TABLE IF NOT EXISTS `article` (
`id` BIGINT(10) NOT NULL AUTO_INCREMENT,
`author_id` INT(10) NOT NULL,
`category_id` INT(10) NOT NULL,
`views` INT(10) NOT NULL,
`comments` INT(10) NOT NULL,
`title` VARCHAR(10) COLLATE utf8_unicode_ci NOT NULL,
`content` TEXT COLLATE utf8_unicode_ci NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
2. 添加数据
INSERT INTO article(author_id,category_id,views,comments,title, content)
VALUES (1,1,1,1,'1','1'), (2,2,2,2,'2','2'),(1,1,3,3,'3','3');
3. 查询
SELECT * FROM article;


4. 需求
查询category_id 为1 且comments 大于1 的情况下,views 最多的article_id.
5. SQL
SELECT id, author_id FROM article WHERE category_id =1 AND comments>1 ORDER BY views DESC LIMIT 1;
6. 索引优化分析过程
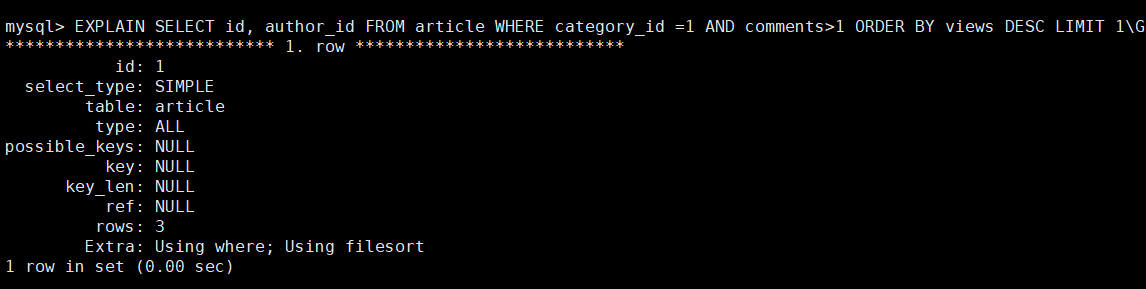
type = ALL : 全表扫描
key = NULL : 没有用到索引,
Extra 中还出现了Using filesort , 产生了二次排序
结论: 垃圾,需要优化。
(1) 第一次创建索引
先查看article原有索引
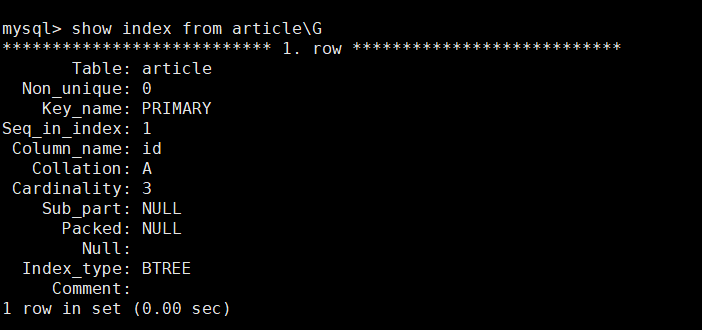
就一主键primary索引。与where ,order by 使用列没得任何关系 ,所以不走索引正常。
下面根据where,order by字段创建一个多列索引
create index idx_c_c_v on article(category_id,comments, views);

再次查看索引
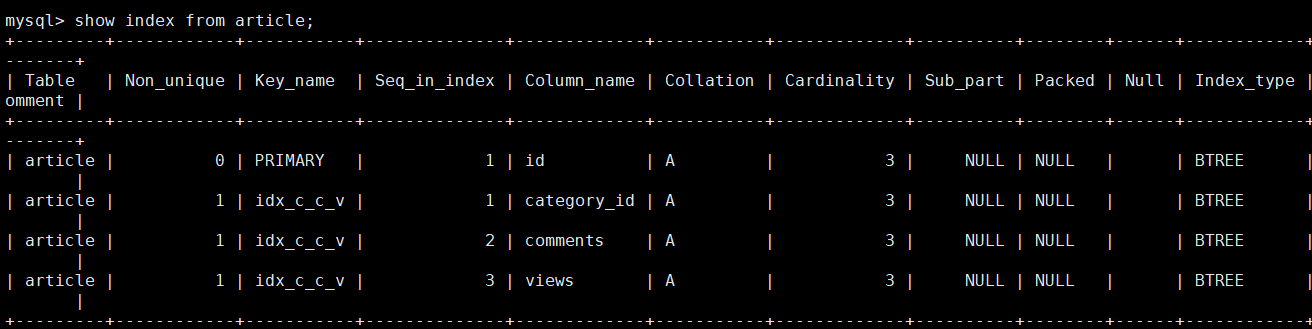
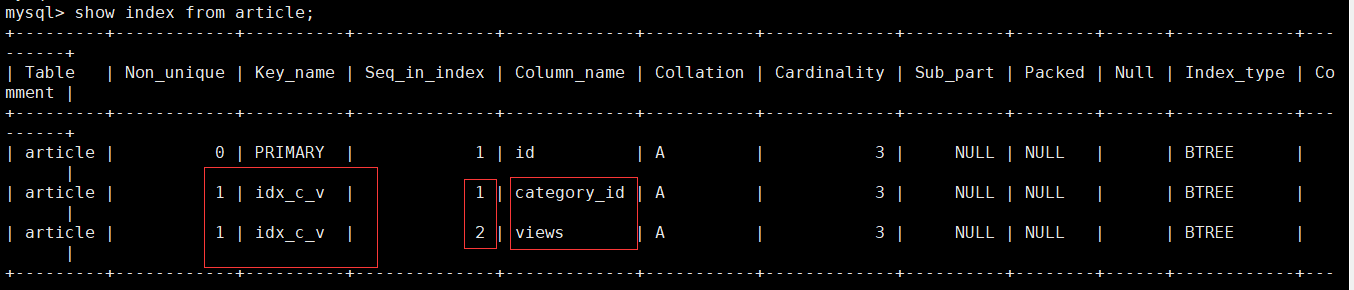
注意索引inx_c_c_v, Seq_in_index 表示索引列查找顺序 ,以上为例 ,表示在使用inx_c_c_v时,先找category_id,再找comments,最后找views。
创建索引之后,我们再分析一下 SELECT id, author_id FROM article WHERE category_id =1 AND comments>1 ORDER BY views DESC LIMIT 1的执行计划。
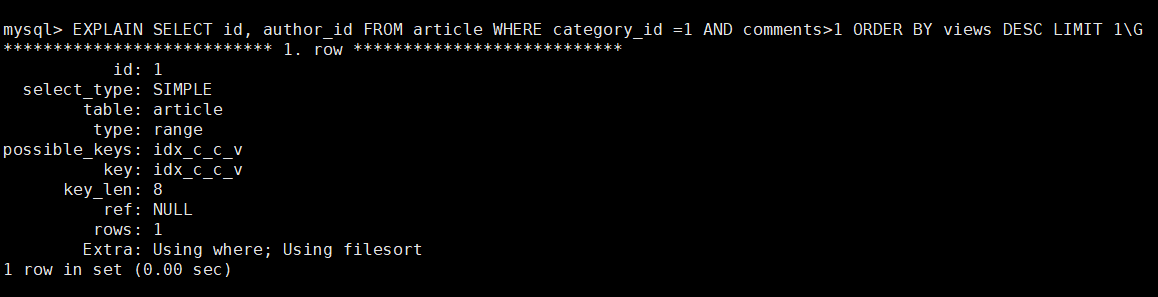
type=range : 范围扫描 ,比之前的type = ALL全表扫描效率要高。
key = inx_c_c_v : 使用了创建的索引。 OK,
Extra : Using filesort , 。。。。。。这个坑货还在。。。。
接着我们再来看下面这个执行计划
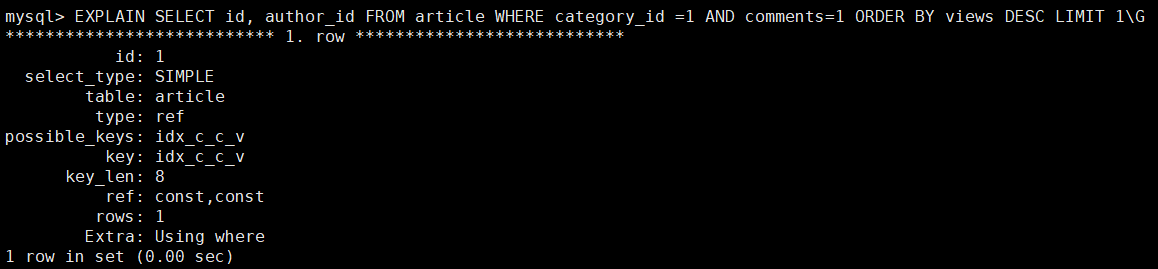
type = ref : 非唯一索引扫描 ,比上面的range 范围扫描效率高呀
key = inx_c_v_v : 使用了索引
ref = const,const : 两个常量,优秀!
Extra ,干掉了Using filesorting
通过对比,我们不难发现,inx_c_c_v不变的情况下,仅是由于查询语句的不同,直接造成执行计划的巨大差异。 其根本原因是comment> 1是个type=range范围查询,它会导致该索引列之后索引列失效,即是(category --√--- comments -----×--views)
所以,index_c_v_v这个索引不行呀,都是因为comments造成的, 所以我们建索引时,不要它,试试!
drop index idx_c_c_v on article;

(2) 第二次创建索引
create index idx_c_v on article(category_id,views);

查看表索引。。。
最后来看一下explain SELECT id, author_id FROM article WHERE category_id =1 AND comments>1 ORDER BY views DESC LIMIT 1\G
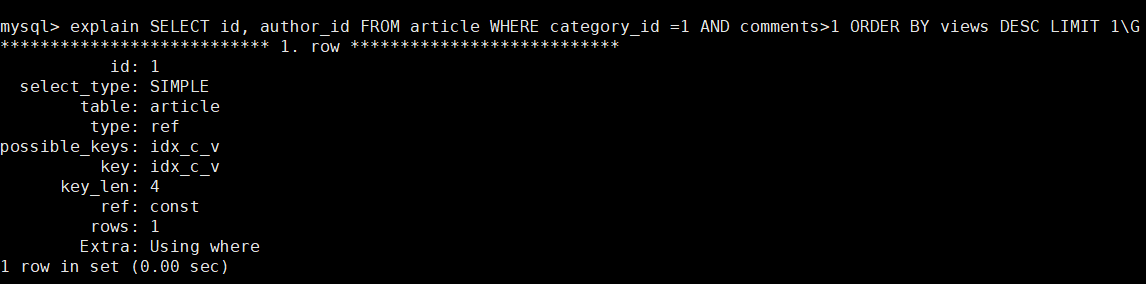
type = ref : 完美
ref = const : 完美
Extra ,没有Using filesort, 也算完美!
总之,还可以吧!
7. 总结
相同的索引 ,select 语句的差别也会造成不同的执行计划,性能差别距大
创建索引时,范围查询需要 特别注意。