MySQL之索引优化(一)
模拟数据
CREATE TABLE staffs(
id INT PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(24) DEFAULT NULL COMMENT'姓名',
`age` INT NOT NULL DEFAULT 0 COMMENT'年龄',
`pos` VARCHAR(20) NOT NULL DEFAULT'' COMMENT'职位',
`add_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT'入职时间'
)CHARSET utf8 COMMENT'员工记录表';
INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('z3',22,'manager',NOW());
INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('July',23,'dev',NOW());
INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('2000',23,'dev',NOW());
INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES(NULL,23,'test',NOW());
ALTER TABLE staffs ADD INDEX index_staffs_nameAgePos(`name`,`age`,`pos`)
查看索引顺序

索引优化案例
- 最佳左前缀法则
- 全值匹配
- 索引列上不计算
- 范围之后全失效
- 覆盖索引多使用
- 使用不等会失效
- 使用NULL值要小心
- 模糊查询加右边
- 字符串加单引号
- 尽量不用or查询
最佳左前缀法则
查询时从索引的最左列开始并且不跳过索引中的列
过滤条件要使用索引必须按照索引建立的顺序,依次满足,一旦跳过某个字段,索引后面的字段都无法被使用
多列索引是先按照第一列进行排序,然后在第一列排好序的基础上再对第二列排序,如果没有第一列的话,直接访问第二列,那第二列肯定是无序的,直接访问后面的列就用不到索引
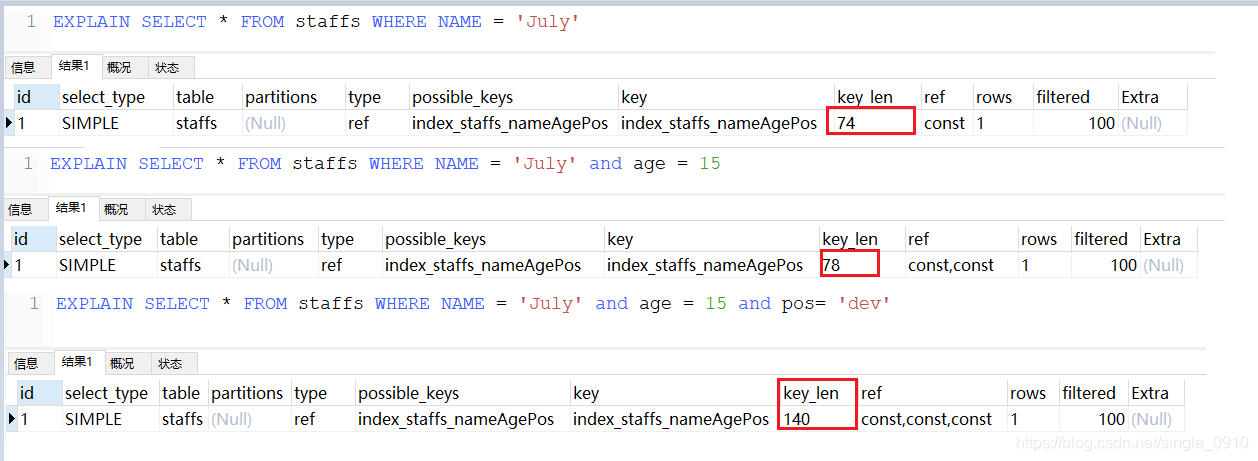
按索引顺寻进行查询
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July'
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' and age = 15
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' and age = 15 and pos= 'dev'
不按索引顺序查询
EXPLAIN SELECT * FROM staffs WHERE age = 15 and pos= 'dev' --跳过第一个索引
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' and pos= 'dev' -- 跳过第二个索引
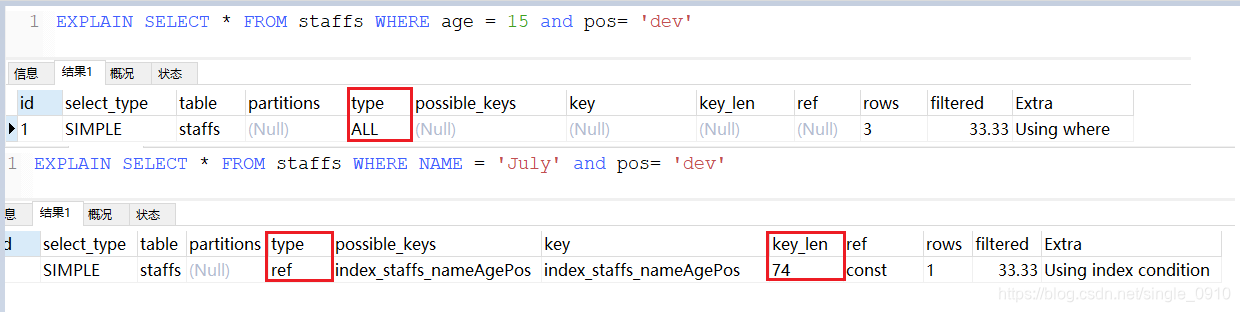
全值匹配
查询的字段按照顺序在索引中都可以匹配,此时速度最快。
索引列上不计算
不在索引列上做任何操作(计算、函数、(自动 or 手动)类型转换),可能会导致索引失效而转向全表扫描
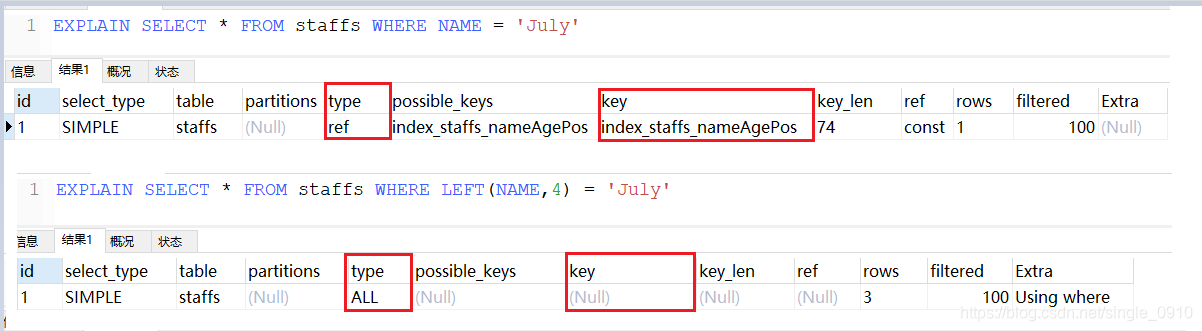
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July'
EXPLAIN SELECT * FROM staffs WHERE LEFT(NAME,4) = 'July' --使用函数
EXPLAIN SELECT * FROM staffs WHERE NAME = '2000'
EXPLAIN SELECT * FROM staffs WHERE NAME = 2000 --使用类型转换
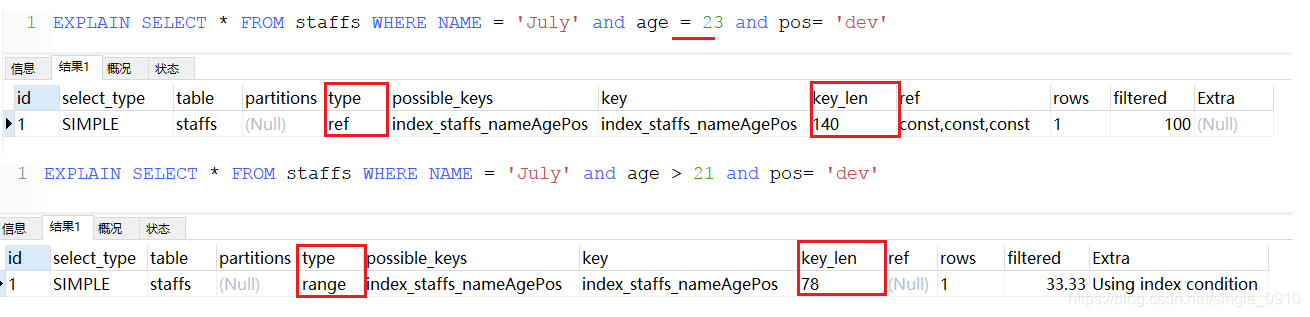
范围之后全失效
使用范围查询后,如果范围内的记录过多,会导致索引失效,因为从自定义索引映射到主键索引需要耗费太多的时间,反而不如全表扫描来得快
建议:将可能做范围查询的字段的索引顺序放在最后
覆盖索引多使用
使用覆盖索引(Using index)会提高检索效率:只访问索引列的查询(索引列和查询列一致,尽量不使用select *)
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' and age = 23 and pos= 'dev'
EXPLAIN SELECT NAME,age,pos FROM staffs WHERE NAME = 'July' and age = 23 and pos= 'dev'
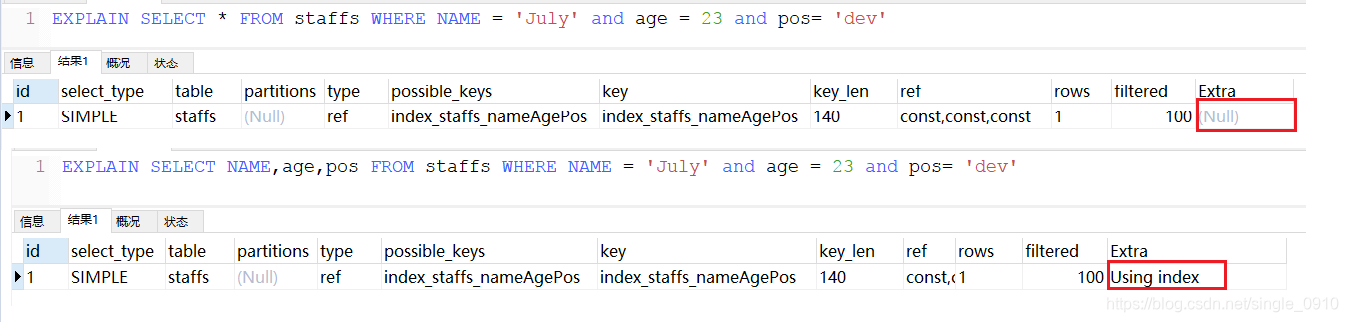
使用不等会失效
在使用不等于(!= 或者<>)时,可能会导致索引失效
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July'
EXPLAIN SELECT * FROM staffs WHERE NAME != 'July'
EXPLAIN SELECT * FROM staffs WHERE NAME <> 'July'
在低版本的MySQL数据库中以下案例会导致索引失效,而我使用的是MySQL 8,数据库内部进行了优化,虽然索引没有失效,但是type从ref变为range,性能明显有些下降
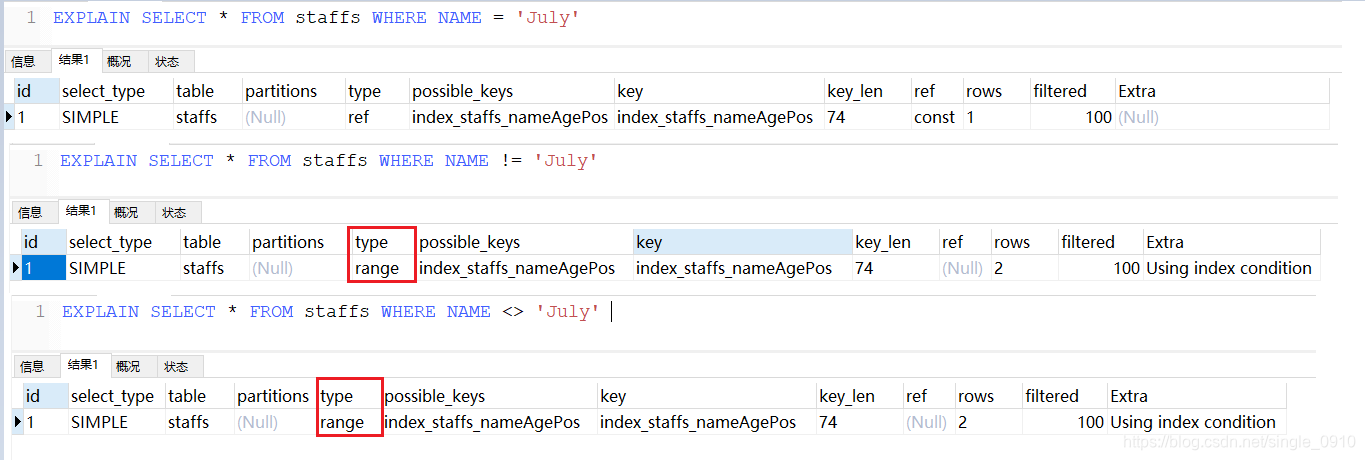
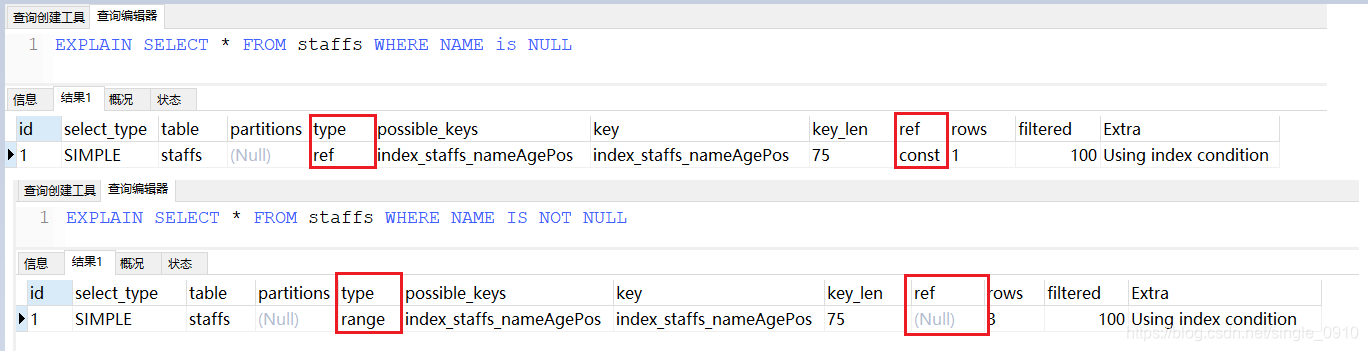
使用NULL值要小心
如果允许字段为空,则
- IS NULL 不会导致索引失效
- IS NOT NULL 会导致索引失效
模糊查询加右边
like查询以通配符%开始会导致索引失效,转而变成全表扫描
EXPLAIN SELECT * FROM staffs WHERE NAME like '%July%' --左右都有通配符
EXPLAIN SELECT * FROM staffs WHERE NAME like '%July' --模糊查询加左边
EXPLAIN SELECT * FROM staffs WHERE NAME like 'July%' --模糊查询加右边
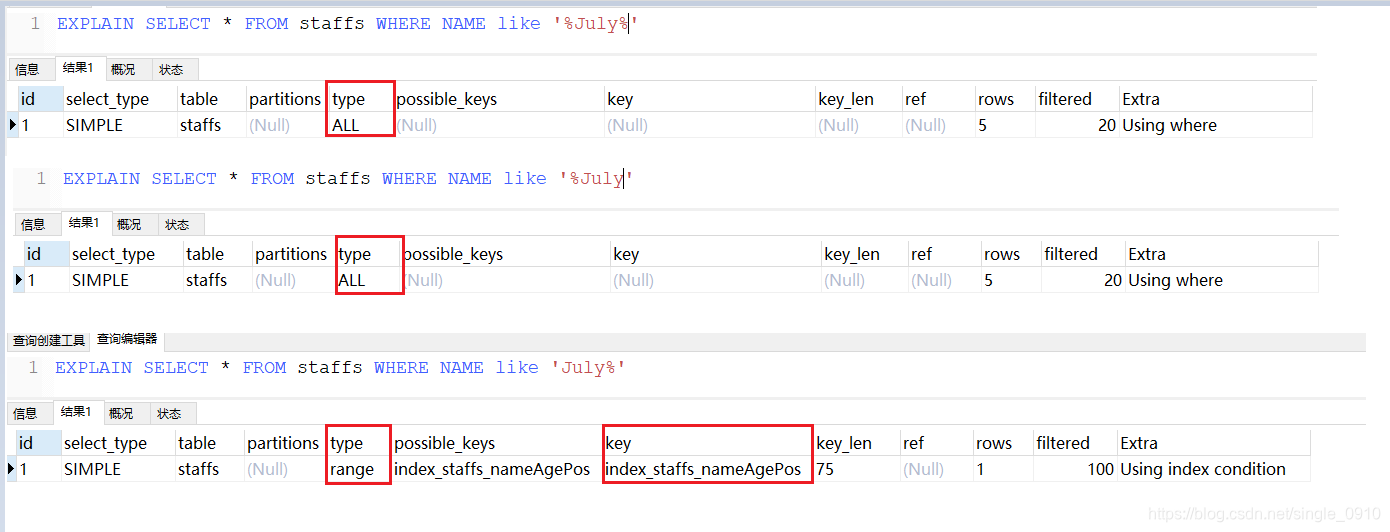
问题: 解决like ‘%字符串%’ 索引不生效的方法:使用覆盖索引(查询的字段尽量和索引字段匹配)
字符串加单引号
EXPLAIN SELECT * FROM staffs WHERE NAME = '2000'
EXPLAIN SELECT * FROM staffs WHERE NAME = 2000 --使用类型转换
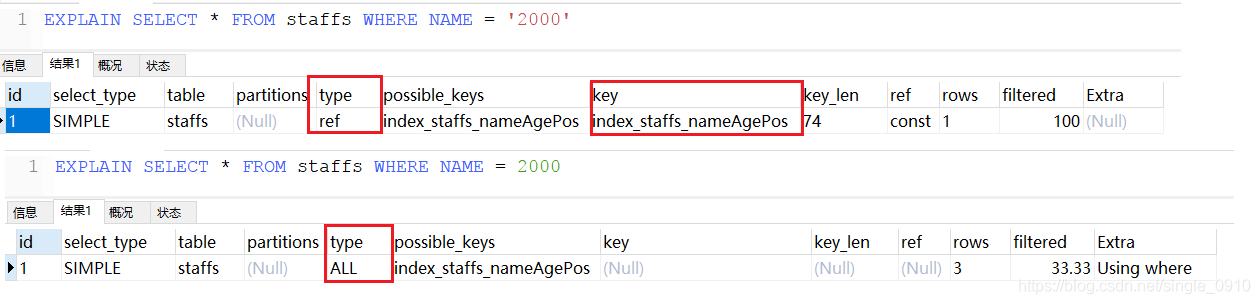
尽量不用or查询
SELECT * FROM staffs WHERE NAME = 'July' OR NAME = 'z3'
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' OR NAME = 'z3'
使用or之后type变为range
简单面试题
create table test03(
id int primary key not null auto_increment,
c1 char(10),
c2 char(10),
c3 char(10),
c4 char(10),
c5 char(10));
insert into test03(c1,c2,c3,c4,c5) values ('a1','a2','a3','a4','a5');
insert into test03(c1,c2,c3,c4,c5) values ('b1','b2','b3','b4','b5');
insert into test03(c1,c2,c3,c4,c5) values ('c1','c2','c3','c4','c5');
insert into test03(c1,c2,c3,c4,c5) values ('d1','d2','d3','d4','d5');
insert into test03(c1,c2,c3,c4,c5) values ('e1','e2','e3','e4','e5');
create index idx_test03_c1234 on test03(c1,c2,c3,c4);
执行计划分析
案例A
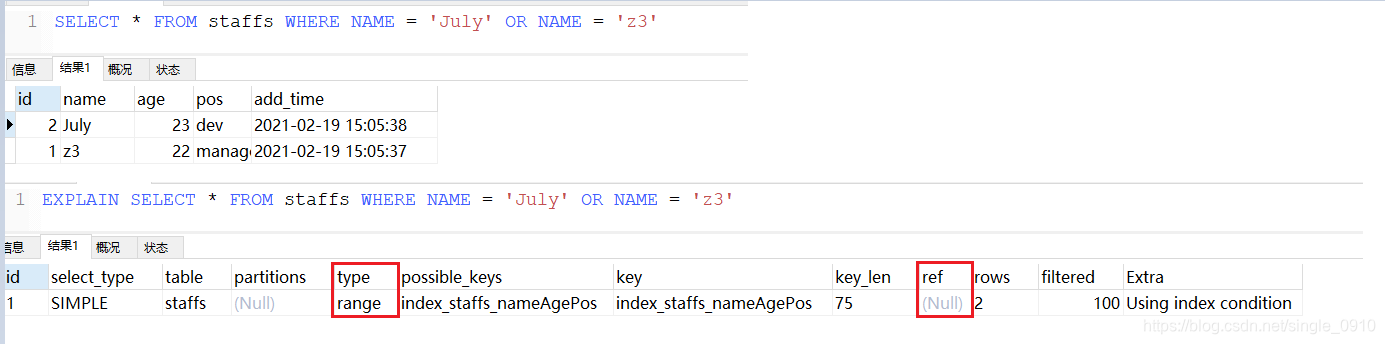
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1'
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' and c2 = 'a2'
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' and c2 = 'a2' and c3 = 'a3'
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' and c2 = 'a2' and c3 = 'a3' and c4 = 'a4'
案例B
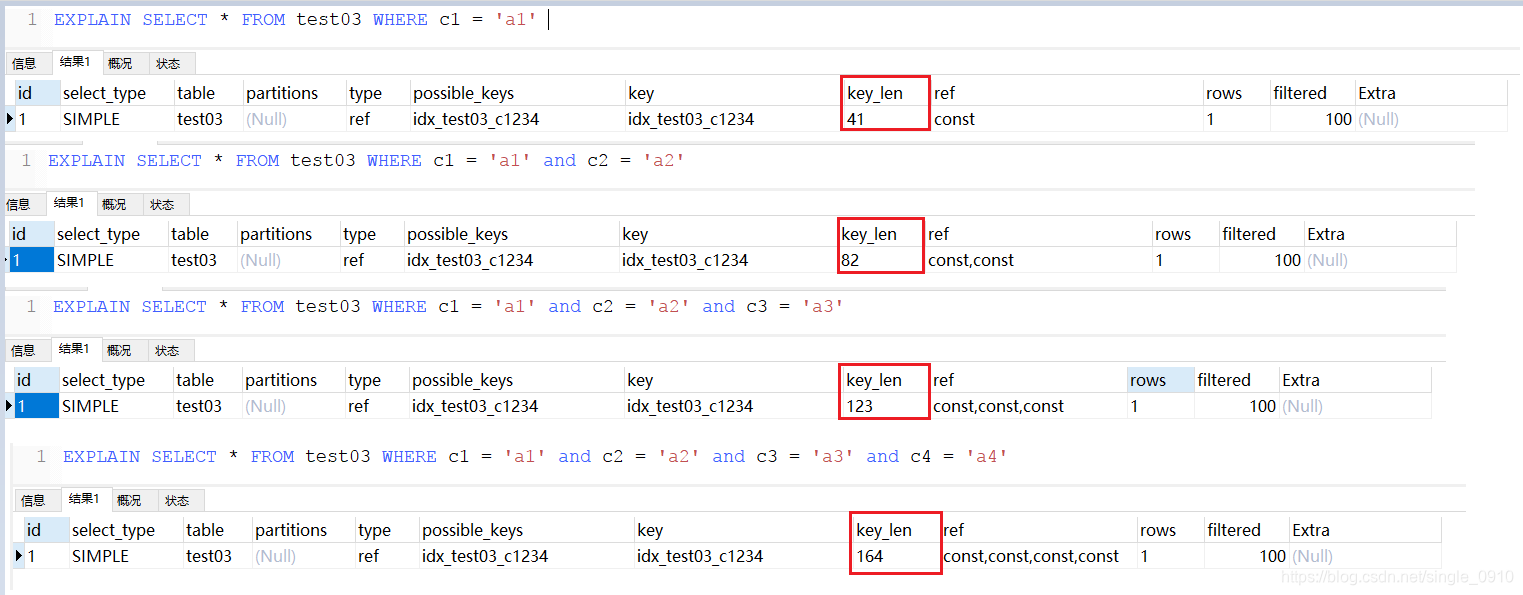
EXPLAIN SELECT * FROM test03 WHERE c4 = 'a4' and c3 = 'a3' and c2 = 'a2' and c1 = 'a1' --MySQL内部优化,依然使用索引
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' and c2 = 'a2' and c4 = 'a4' and c3 > 'a3'
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' and c2 = 'a2' and c4 = 'a4' ORDER BY c3 --c3用于排序
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' and c2 = 'a2' ORDER BY c3
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' and c2 = 'a2' ORDER BY c4 --出现文件排序

案例C
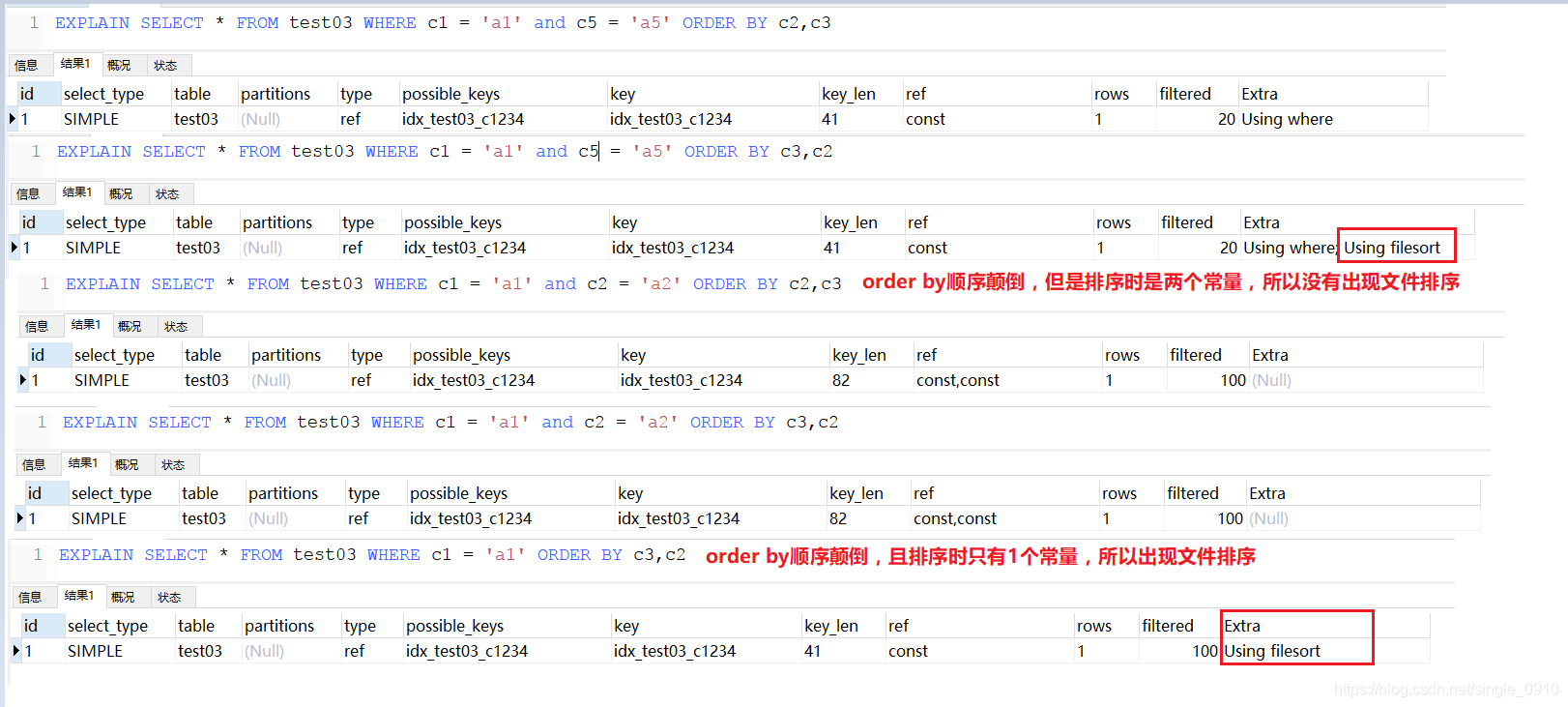
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' and c5 = 'a5' ORDER BY c2,c3
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' and c5 = 'a5' ORDER BY c3,c2
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' and c2 = 'a2' ORDER BY c2,c3
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' and c2 = 'a2' ORDER BY c3,c2
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' ORDER BY c3,c2
案例D
我的数据库没法执行下面的案例,所以只有SQL语句,截图我没有验证过
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' AND c4 = 'a4' GROUP BY c2,c3
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' AND c4 = 'a4' GROUP BY c3,c2

- 一般order by是范围
- group by是分组,所以要先排序,所以会有临时表出现

优化口诀
全值匹配我最爱,最左前缀要遵守;
带头大哥不能死,中间兄弟不能断;
索引列上少计算,范围之后全失效;
Like百分写最右,覆盖索引不写星;
不等空值还有or,索引失效要少用;
VAR引号不可丢,SQL高级也不难!