| Question | Answer |
|---|---|
| 所属课程 | 构建之法 |
| 作业要求 | 作业要求 |
| github地址 | https://github.com/zjc-123/WordCount/tree/master/201731062321 |
| 结对同学博客地址 | https://www.cnblogs.com/hanhaocom/p/11669499.html |
| 结对同学学号 | 201731062319 |

| PSP2.1 | Personal Software Process Stages | 估计耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 40 |
| Estimate | 估计做这个任务需要多少时间 | 45 | 50 |
| Development | 开发 | 900 | 1080 |
| Analysis | 需求分析(包括学习新技术) | 70 | 90 |
| Design Spec | 生成设计文档 | 20 | 20 |
| Design Review | 代码复审(和同事审核设计文档) | 30 | 45 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 40 | 30 |
| Design | 具体设计 | 60 | 70 |
| Coding | 具体编码 | 540 | 660 |
| Code Review | 代码复审 | 60 | 90 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 180 |
| Reporting | 报告 | 60 | 100 |
| Test Report | 测试报告 | 60 | 60 |
| Size Measurement | 计算工作量 | 20 | 20 |
| Postmortem &Process Improvement Pan | 事后总结,并提出过程改进计划 | 25 | 20 |
| 合计 | 1125 | 1395 |
1、基本功能
- 不得不说这题目也太长了吧,害我读了好久。在和结对队友阅览完题目后,经过讨论,我们觉得在此次的题目中有四个基本功能:一是统计整个文件的行数;二是统计文件的字符数(包括空格、换行符、标点);三是统计单词频率;四是输出单词长度有效词数。先是将题目要求的功能实现之后,再去考虑代码的规范优化。
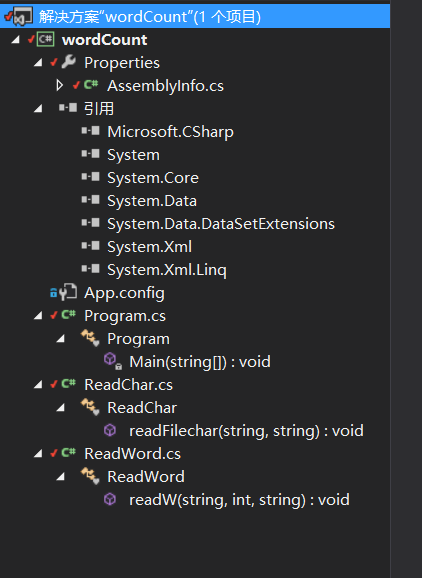
1、ReadWord.cs类:用于统计单词出现频率和计算指定单词长度的单词数。
2、ReadChar.cs类:用于统计文件的行数和字符个数。
3、program.cs:获取命令进行相应操作。
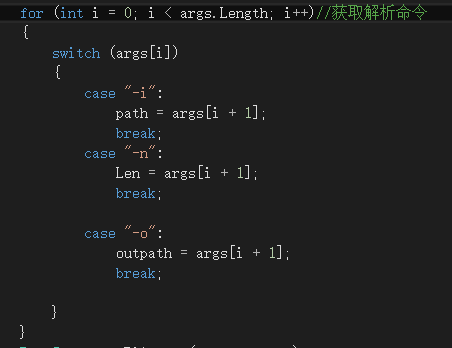
4、通过switch(args[i])解析命令
2、程序大致流程图

1、统计字符数和行数
正则表达式统计字符数和行数
string str = File.ReadAllText(path);
StreamWriter sw = File.AppendText(outpath);
int hz = Regex.Matches(str, @"[\u4E00-\u9FFF]").Count;//汉字
int en = str.Length;//字符
int num = Regex.Matches(str, @"\d").Count;//数字
int hang = Regex.Matches(str, @"\r").Count + 1;//行数
Console.WriteLine("汉字个数={0}\n字符个数(包括空格、标点、换行符)={1}\n数字个数={2}\n行数={3}", hz, en, num, hang);
2、统计单词频率和字典排序
- 利用正则表达式划分单词,用Dictionary的key和value记录单词和出现频率并进行排序
string paths = File.ReadAllText(path);
StreamWriter sw = File.AppendText(outpath);
Dictionary<string, int> frequencies = new Dictionary<string, int>();
frequencies = new Dictionary<string, int>();
string[] words = Regex.Split(paths, @"\W");
foreach (string word in words)
{
if (frequencies.ContainsKey(word))
{
frequencies[word]++;
}
else
{
frequencies[word] = 1;
}
if (word.Length < 4)
{
frequencies.Remove(word);
}
}
Dictionary<string, int> ff = frequencies.OrderByDescending(o => o.Value).ThenBy(p => p.Key).ToDictionary(p => p.Key, o => o.Value);//利用key和value排序
int count = 0;
Dictionary<string, int>.Enumerator hh = ff.GetEnumerator();
while (hh.MoveNext())
{
if (Len.Equals(hh.Current.Key.Length))
count = count + hh.Current.Value;
}
Console.WriteLine("文件中长度为" + Len + "的单词数:" + count + "个");
- 利用dictionary中的key和value进行排序
Dictionary<string, int> ff = frequencies.OrderByDescending(o => o.Value).ThenBy(p => p.Key).ToDictionary(p => p.Key, o => o.Value);//利用key和value排序
我们在互审过程中发现了很多大大小小的问题,有些是不影响代码的运行,但在输入一些字符后程序就退出或者出现异常了。特别严重的是文件位置字符串的输入,老是出现异常或者是null的问题,找不到路径的文件,后续的改进:我们增加了对输入的文件的路径字符串的限定和判断,这样就大大增加了程序的可靠性。又比如:在输出相应单词长度的字符的需求时,忘了限制字符串的长度,导致输出了一大串数据。
互审感悟:自己一个人敲代码效率可能会比两个人一起高,因为少了交流的工作,但很多时候会犯一些自己都觉得蠢的问题,因为觉得一切都是按照自己的思路来做的,虽然大的错误不会出现,但总会一楼一些小的问题。但这时候如果有一个队友和自己结对,他就会发现那些我忽视的细节问题,正所谓旁观者清嘛。
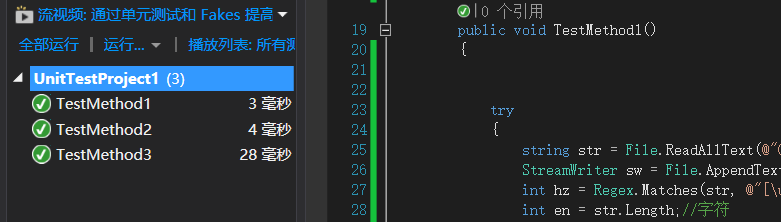
- 对其中的三个方法进行测试
- 性能测试
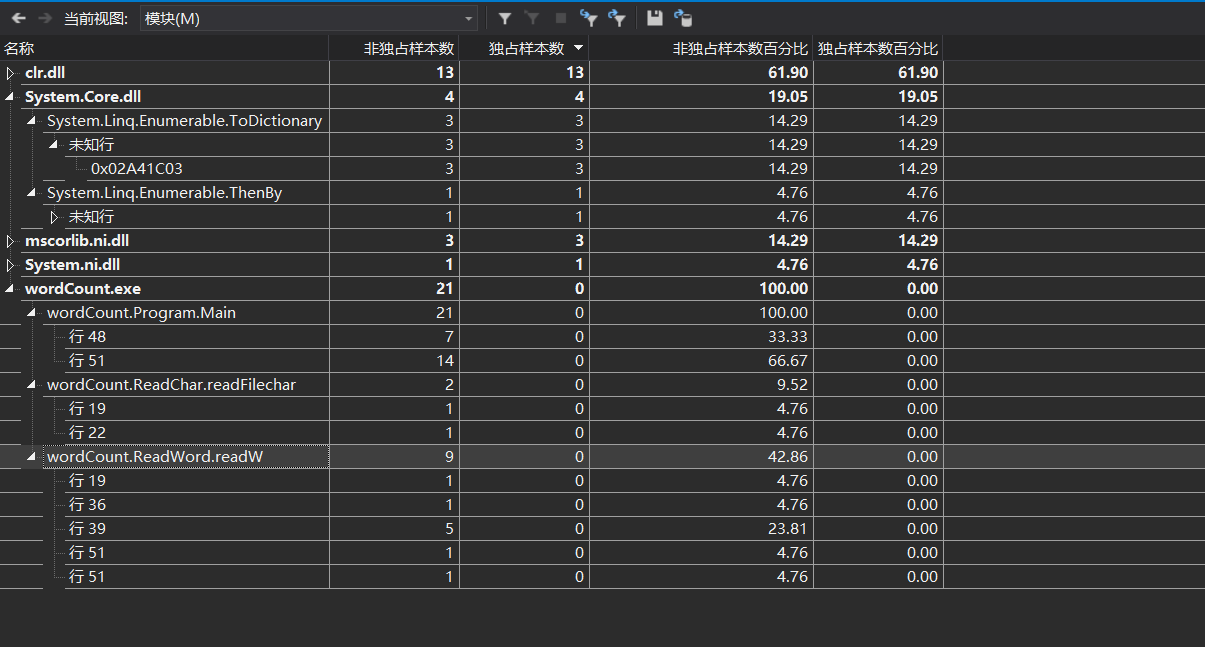
可见wordCount.ReadWord.ReadW 占用百分比最大,优化主要以这个为主,对代码进行优化,减少代码间的重复调用,减少循环的调用,降低耦合等。
- 在控制台运行
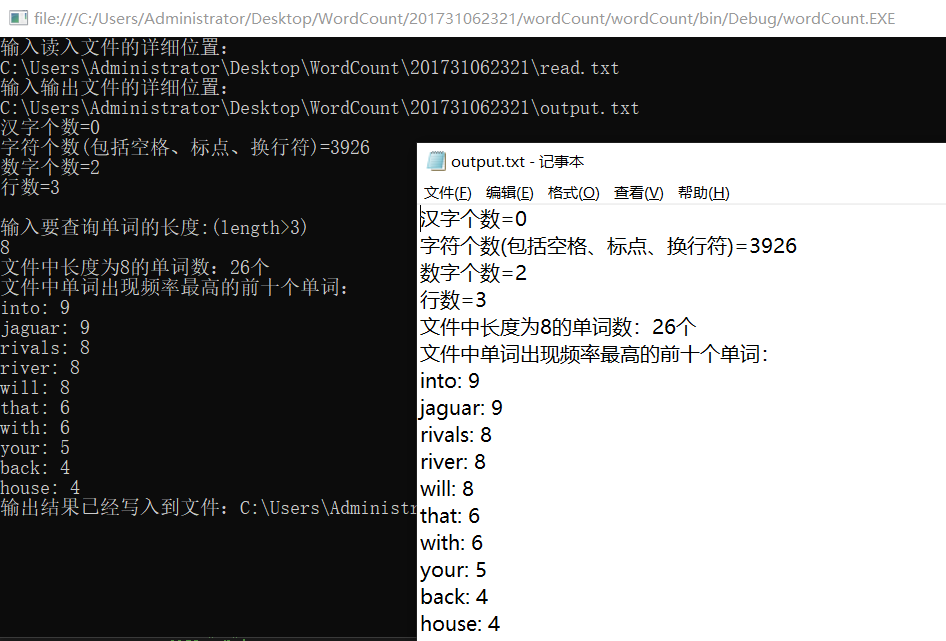
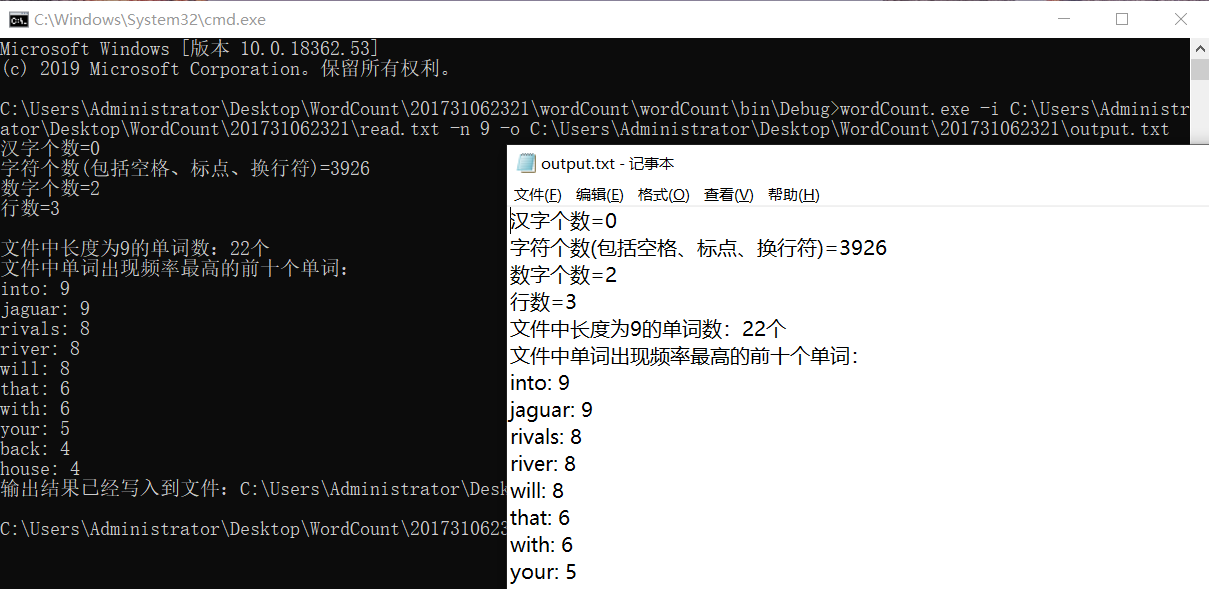
2.在命令行操作
这是第一次结对编程,刚开始总是不习惯,因为要挑两个人都有空的时间来一起完成任务,不习惯对方的编程习惯,但还好整个过程还算是和谐没有打架。这次最大的感悟就是,原来自己在敲代码时,有那么多的小错误没有发现,虽然这些错误不会影响程序的整体运行。两个人一起编程的的确确增加了效率,大大地减少了程序的错误,因为旁观者清,可以看到很多自己没在意的错误点。但两个人还是有不同的思想,在交流时要花时间去理解他这个地方为什么这么处理,这无疑 增加了编程的时间。因为减少了去排查错误的时间,总体上讲效率还是比一个人快