| Github项目地址 | Github项目地址 |
|---|---|
| 这个作业要求在哪里 | 作业要求的链接 |
| 结对同伴的链接 | 同伴链接 |
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 55 |
| · Estimate | · 估计这个任务需要多少时间 | 90 | 90 |
| Development | 开发 | 60 | 75 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 35 |
| · Design Spec | · 生成设计文档 | 15 | 18 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 20 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 5 | 5 |
| · Design | · 具体设计 | 30 | 40 |
| · Coding | · 具体编码 | 120 | 150 |
| · Code Review | · 代码复审 | 40 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 50 | 70 |
| Reporting | 报告 | 100 | 120 |
| · Test Report | · 测试报告 | 50 | 55 |
| · Size Measurement | · 计算工作量 | 20 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 15 | 10 |
| 合计 | 685 | 823 |
一、项目思路及其总结
- a.解题思路描述。
- 拿到题目后,仔细阅读理清题意。题目需要我们对文本中的字符、单词、单词频率、有效总行数进行统计
- 进行模块划分除主函数之外只需要一个类,七个函数,每个函数不同的功能。其次根据个人编程能力的强弱进行分配
- 先将待统计的文档读入,利用正则表达式统计出符合题目要求的单词并放入字典并返回
- 将字典转换成数组,并根据频率排序从高到低进行排序,若频率一样按照字母顺序
- 对数组中的字符、单词、单词频率、有效总行进行统计
- 对每个功能进行封装,使代码更简洁
- b.设计实现过程
大体上,除了主函数这个类,还有一个大类getFile(),在getFile这个类中有七个方法,有一个公共方法getDic 这个方法用于获得字典,存入字典中的是长度大于四且不以数
字开头的单词以及他们出现的次数,这个方法会返回一个Hashtable,方法getWordFre()方法将字典按照单词出现的次数进行排序,并返回一个动态数组。其他的,可以直接调用,getWordFre这个方法利用返回的数组进行相应功能的实现。单元测试是对这几个方法所
对应的功能进行相应的测试。 - c.代码规范
- 适当使用空行,来增加代码的可读性
- 方法的命名,一般将其命名为动宾短语,一个方法只完成一个任务
- 常用缩进和换行,使代码层次清晰,明了
- 对泛型进行循坏时,尽量foreach
- 缩进和间隔:缩进用TAB,不用 SPACES
- 注释需和代码对齐
- 避免写太长的方法。一个典型的方法代码在1~25行之间。
- d.代码说明
public Hashtable getDic(string pathName, ref Hashtable wordList) //getDic:从文本文件中统计词频保存在Hashtable中
{
StreamReader sr = new StreamReader(pathName);
string line;
line = sr.ReadLine(); //按行读取
while (line != null)
{
MatchCollection mc;
Regex rg = new Regex("[0-9A-Za-z-]+"); //用正则表达式匹配单词
mc = rg.Matches(line);
for (int i = 0; i < mc.Count; i++)
{
Regex regNum = new Regex("^[0-9]");
string mcTmp = mc[i].Value.ToLower(); //大小写不敏感
if (mcTmp.Length >= 4 && regNum.IsMatch(mcTmp) == false)//字符长度大于4且不以数字开头
{
if (!wordList.ContainsKey(mcTmp)) //第一次出现则添加为Key
{
wordList.Add(mcTmp, 1);
}
else //不是第一次出现则Value加
{
int value = (int)wordList[mcTmp];
value++;
wordList[mcTmp] = value;
}
}
else
continue;
}
line = sr.ReadLine();
}
sr.Close();
return wordList;
}getDic(string pathName, ref Hashtable wordList)这个方法用于从文本中将每个词提取出来,并统计出每个词词频放到Hashtable中,然后用StreamReader打开文件,
用while实现按行读取,在循环体中,用正则表达式匹配每一行的单词,while中的for循环用于对匹配出来的单词进行按条件剔除,符合条件的加入字典,不符合的剔除,最后返回一个Hashtable
public ArrayList getWordFre(string pathName, ref Hashtable wordList)
{
getFile Wordlist = new getFile();
Hashtable Wordlist_fre = new Hashtable();
Wordlist_fre = Wordlist.getDic(pathName, ref wordList);
ArrayList keysList = new ArrayList(Wordlist_fre.Keys);
keysList.Sort();
string tmp = String.Empty;
int valueTmp = 0;
for (int i = 1; i < keysList.Count; i++)
{
tmp = keysList[i].ToString();
valueTmp = (int)wordList[keysList[i]];//次数
int j = i;
while (j > 0 && valueTmp > (int)wordList[keysList[j - 1]])
{
keysList[j] = keysList[j - 1];
j--;
}
keysList[j] = tmp;//j=0
}
return keysList;
}getWordFre(string pathName, ref Hashtable wordList)将传递过来的wordList进行按频率排序,并将Hashtable转换成动态数组并返回
public void write(string outputPath, ref Hashtable wordList, int lines, int words, int characters, int wordsOutNumFla, int wordsOutNum,int m,string inputPath)
{
getFile Wordlist = new getFile();
ArrayList keysList = new ArrayList();
ArrayList keysList1 = new ArrayList();
keysList1 = Wordlist.getPhrase(inputPath, outputPath, ref wordList, m);
keysList = Wordlist.getWordFre(outputPath, ref wordList);
StreamWriter sw = new StreamWriter(outputPath);
sw.WriteLine("characters:{0}", characters);
sw.WriteLine("words:{0}", words);
sw.WriteLine("lines:{0}", lines);
if (wordsOutNumFla == 1)
{
wordsOutNum = wordsOutNum;
}
else
wordsOutNum = 10;
for (int i = 0; i < wordsOutNum; i++)
{
sw.WriteLine("<{0}>:{1}", keysList[i], wordList[keysList[i]]);
}
sw.WriteLine("以下是长度为{0}的词组:\n",m);
foreach (string j in keysList1)
{
sw.WriteLine("<{0}>:{1}", j, 1);
}
sw.Flush();
sw.Close();
}写入文件还是比较简单,但是有一个小细节就是在打开文件之后一定要关闭所打开的文件,不然如果要对文件进行二次追加写入的时候回报错,
我之前分两次写入文件的,然后又忘记了在第一次打开文件之后进行关闭,导致了报错一定要记住
这个方法,传入了需要写入文件的总字符数、单词数、频率,以及频率最高的单词的个数的标志位wordsOutNumFla,
通过wordsOutNumFla这个来判断是输出默认的十个最高频率单词,还是使用-n参数后面的数字
- e 收获
- 一开始拿着这个题目头都大了说个实话,首先是因为我对C#是很陌生的,随后和我的同伴一起针对这次作业如何实现进行查阅一定的相关资料,
知道了在C#中对于统计文本中的单词可以借助字典来实现,所以又去查找了字典相关的资料,然后慢慢的了解了该如何去实现我们想要的功能。其次因为这次的个人作业是结对编程,
可以两个一起来实现代码模块,相比较于一个人的话就会轻松很多,因为两个人结对编程的话,一个人写,一个人审查,如果有问题可以及时纠正,明白自己出错的地方,
而如果是我自己一个人写的话,往往只能通过编译器报错来告诉我哪里错了,自己一个人是很难发现的,这样就可以节省一定的时间。在解决项目问题的关键代码上,这部分花的时间很多,
第一个是因为刚学的知识应用不熟悉,第二个因为自己技术确实不到位,但是通过大量的时间最终还是做出来了,所以世上无难事只怕有心人吧。
- 在我第一次实现代码的时候,是没有进行模块的划分的,就只有两个类,一个程序入口,另一个类实现所有功能,这也就导致我自己的代码,非常乱,非常复杂,
我自己都找不到相应的功能是在哪里进行实现的,如果运行报错,找半天都找不到错误的地方,就浪费了大量的时间,然后第二次我将我的代码进行了模块的划分,
划分出了七个方法,每个方法独立,同时可以调用其他的方法,这样一来,就比我第一次的代码看着简洁了许多。
- 一开始拿着这个题目头都大了说个实话,首先是因为我对C#是很陌生的,随后和我的同伴一起针对这次作业如何实现进行查阅一定的相关资料,
二、单元测试
- 在没有封装之前,我们对各自的代码进行了代码互审
- 对getHangNum进行测试,一下是代码
[TestMethod]
public void getHangNum()
{
int lines;
int m = 3;
string input_path = "C:/Users/罗伟诚/Desktop/input.txt", out_put = "C:/Users/罗伟诚/Desktop/out.txt";
Hashtable wordList = new Hashtable();
ArrayList keysList = new ArrayList();
getFile c = new getFile();
keysList = c.getWordFre(input_path, ref wordList);
lines = c.getHangNum(input_path);
}
测试出来如上图所示,没有问题
- 对 getWordNum1进行测试
[TestMethod]
public void getWordNum1()
{
int words;
int m = 3;
string input_path = "C:/Users/罗伟诚/Desktop/input.txt", out_put = "C:/Users/罗伟诚/Desktop/out.txt";
Hashtable wordList = new Hashtable();
Hashtable wordList1 = new Hashtable();
ArrayList keysList = new ArrayList();
getFile c = new getFile();
keysList = c.getWordFre(input_path, ref wordList);
words = c.getWordNum(input_path);
}- 对getCharactersNum1进行测试
[TestMethod]
public void getCharactersNum1()
{
int words, characters = 0, wordsOutNum = 0, wordsOutNumFla = 0, inputPathFla = 0, outputPathFla = 0;
int m = 3;
string input_path = "C:/Users/罗伟诚/Desktop/input.txt", out_put = "C:/Users/罗伟诚/Desktop/out.txt";
Hashtable wordList = new Hashtable();
Hashtable wordList1 = new Hashtable();
ArrayList keysList = new ArrayList();
getFile c = new getFile();
keysList = c.getWordFre(input_path, ref wordList);
words = c.getWordNum(input_path);
}
- 三个测试写在一个类中,一起进行测试,测出来都通过了
- 之前三个测试都是用的同一个文件进行测试的,接下来,用准备的十个测试样例进行上述操作
- 代码测试覆盖率,由于这个是离线版,没有测试覆盖率
三、异常处理
- 关于路径的异常处理,因为这里需要用户输入路径,又无法用Direct 这个路径检查函数来判断,所以我就自己设置了一个标志位
try
{
if (inputPathFla == 1 || outputPathFla == 1)
{
Hashtable wordList = new Hashtable();
Hashtable wordList1 = new Hashtable();
ArrayList keysList = new ArrayList();
getFile c = new getFile();
keysList = c.getWordFre(input_path, ref wordList);
lines = c.getHangNum(input_path);
words = c.getWordNum(input_path);
characters = c.getCharactersNum(input_path);
c.write(out_put, ref wordList, lines, words, characters, wordsOutNumFla, wordsOutNum,m,input_path );
Console.WriteLine("写入文件完成,请前往{0}查看\n", out_put);
}
else
{
Console.WriteLine("请使用 -i 参数和 -o 参数指定输入和输出路径\n");
}
}
catch (Exception e)
{
Console.WriteLine("请检查输入路径是否正确");
}
- 这是路径输入正常的情况

- 这是路径输入错误的情况
四、代码改进
- 一开始其实没有想着用字典的,因为想着用自己已有的知识看能不能解决,但是用字符串和数组都不好解决,会导致代码过长,冗杂
- 使用字典之后,我只需要用一个类,将文本文档中的数据提取出来存入字典,之后的操作可以直接使用字典就行了,非常的方便。
- 统计字符,之前采用的方法效率很低,后来采用的正则表达式,提高了效率
- 效率分析及最耗时的函数如下
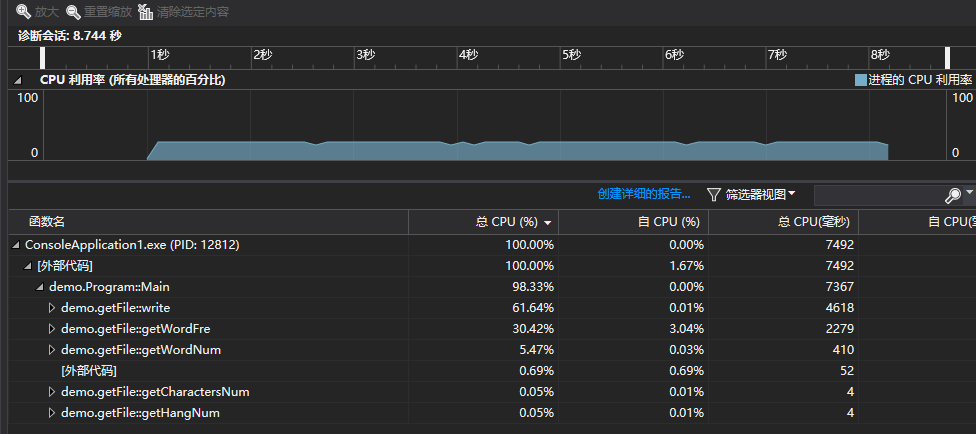
五、代码复审
- 一开始因为我不是用的正则表达式,来提取单词,在张鹏的提示下,学习了一点点关于正则表达式的知识,并应用于程序中,因为之前我自己的没有用正则表达式的代码没有保存,所以附上现在的正则表达式的代码
- 用正则表达式,在处理数据比较多的时候,可以提高处理的速度(所以还是很感谢张鹏同学的提醒)
MatchCollection mc;
Regex rg = new Regex("[A-Za-z]+"); //用正则表达式匹配单词
mc = rg.Matches(line);
for (int i = 0; i < mc.Count - m + 1; i++)
{
Regex regNum = new Regex("^[0-9]");
string mcTmp = "";
int t = i;
for (int q = 0; q < m; q++)
{
mcTmp += mc[t].Value.ToLower() + " ";
t++;
}
k.Add(mcTmp);
}六、总结
通过这次结对编程,总结了一下结对编程的好处
- 可以互相监督,不容易偷懒:两个人一起工作需要互相配合,如果偷懒就会拖延进度
- 可以互相学习,两个人的编程基础不一样,想法也不一样,在某些方面可能我厉害些,有些方面他厉害些,所以可以相互促进
- 多双眼睛,更少的bug:两个人相互监督工作,可以增强代码质量,并减少BUG
- 结对编程确实可以达到1+1>2的效果