生物医学大数据
重点:蛋白质定量
新蛋白可以是全新的蛋白质,也可以是知结构但未知功能的蛋白质,也可以是知道结构有新功能的蛋白质。
新蛋白鉴定可以使用以下方法。
基于基因组,可以基因组中的coding区数据库变成理论上的蛋白质数据库,利用密码子翻译出氨基酸,为准确可以有三种版本,可以敲除1个碱基,2个碱基,3个碱基等,同时考虑正反链因素,就有3*2=6种可能性。基于转录组翻译情况,采用搜索已知蛋白质信息数据库,准确率高。denovo方法,即从头测序的综合比较方法,可信度基于打分值或p-value等,
可以综合使用以上方法。
拿到原始数据后,因为许多蛋白质低峰度的部分不易被MSMR察觉,同时分析时是分时段取样,量更少,更加不易定量,所以将此数据过滤。可以使用pFind进行开放式搜索以先查全后查准的原则,为了缩小大误差而搜库,为了缩小小误差而过滤。
蛋白质鉴定概率计算是得到的置信度基于数据导向不是研究导向,即没有对单个蛋白做鉴定概率的计算,只有对同一批次数据所做的计算,同时不能直接合并不同数据处理后的数据。这也是多批次质控需要注意的内容。多搜索引擎使用2个引擎最佳,组合模式是mascot+X。
蛋白质翻译后会进行修饰。关于修饰的的现状是低谱图鉴定率,即蛋白质修饰没鉴定到,因此这些无法识别的修饰使得蛋白表达量被低估。修饰分为体内修饰、体外修饰和氨基酸突变,体内修饰是自然情况,翻译后修饰,大部分修饰是体内修饰。体外修饰是人为修饰,在实验研究中使用。氨基酸突变是通过氨基酸磷酸化扩大蛋白质种类。
具体而言,磷酸化有10^4 or 10^5种,泛素化可规模化鉴定,糖基化比较复杂,难以鉴定。
修饰鉴定原理是将正常和修饰两种谱图比对,y值变大则证明修饰存在。鉴定困难在于修饰种类多,修饰量少低丰度难察觉,修饰往往在动态变化,比如磷酸化的种类是发生或不发生^位点数。修饰研究的内容,有以下四个方面,包括修饰鉴定,修饰定量,修饰作用网络,新修饰的鉴定。
常规修饰鉴定流程用于对已存在的修饰进行鉴定:

首先指定修饰类型,修饰类型包括固定修饰和可变修饰,固定修饰是某位点100%发生修饰,可变修饰是某位点不一定发生修饰。通过数据库搜索,找到该修饰的修饰类型、修饰肽段和修饰位点。在质控时,对于体外修饰可以直接肽段质检;对于体内修饰,高丰度蛋白可以将修饰与非修饰分开再肽段质检,对于低丰度蛋白先卡质量值后肽段质检。肽段质控后进行位点质控,eg:phosphors软件可针对磷酸化修饰的鉴定。
探索新修饰可采用非限制性修饰鉴定:
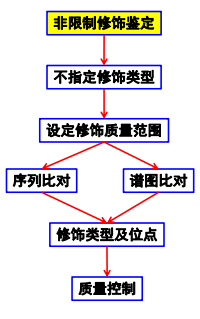
虽然不指定修饰类型,但规定修饰质量范围,通过与数据库中存在修饰信息进行序列比对或图谱比对,找到修饰类型和修饰位点,最后质控。
可以综合使用以上两种方法,取少样本加入不指定修饰类型,然后得到修饰类型,根据得到的修饰类型加入到常规修饰鉴定的流程中去,从而指定修饰类型。常用软件有mascot。
虽然可变修饰多使得搜库的灵敏度下降,但是首先保证准确度。可使用多批次搜库策略,即每次一种修饰作为一次搜寻,有n种修饰则并行n次搜寻,而不是N种修饰同时搜寻。
修饰鉴定与生物学过程,通过测得代谢途径中的所有物质的修饰来解释生物学过程。