词法分析程序(Lexical Analyzer)要求:
- 从左至右扫描构成源程序的字符流
- 识别出有词法意义的单词(Lexemes)
- 返回单词记录(单词类别,单词本身)
- 滤掉空格
- 跳过注释
- 发现词法错误
程序结构:
输入:字符流(什么输入方式,什么数据结构保存)
处理:
–遍历(什么遍历方式)
–词法规则
输出:单词流(什么输出形式)
–二元组
单词类别:
1.标识符(10)
2.无符号数(11)
3.保留字(一词一码)
4.运算符(一词一码)
5.界符(一词一码)
| 单词符号 |
种别码 |
单词符号 |
种别码 |
| begin |
1 |
: |
17 |
| if |
2 |
:= |
18 |
| then |
3 |
< |
20 |
| while |
4 |
<= |
21 |
| do |
5 |
<> |
22 |
| end |
6 |
> |
23 |
| l(l|d)* |
10 |
>= |
24 |
| dd* |
11 |
= |
25 |
| + |
13 |
; |
26 |
| - |
14 |
( |
27 |
| * |
15 |
) |
28 |
| / |
16 |
# |
0 |
因为自己对运用Java语言编写程序比较熟悉,所以用Java编写了这次的词法分析程序。将字符与种别码分别对应起来,区分数字分隔符。
程序代码:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Scanner;
public class LexicalAnalyzer {
static String[] keyWords=new String[]{"main","if","then","while","do","static",
"int","double","struct","break","else",
"long","switch","case","typedef","char",
"return","const","float","short","continue",
"for","void","sizeof"}; //关键字种别码从1开始
static char ch;
static int index;
static int syn, sum=0, row;
static String str="";
static StringBuilder word=new StringBuilder(""); //建立StringBuilder,方便读取文字信息追加
public static void main(String[] args) {
index=0;
row=1;//从第一行开始扫描
System.out.println("请输入一段C语言源程序字符串(以#符号结束):");
BufferedReader bf=new BufferedReader(new InputStreamReader(System.in));
try{
do{
String testStr;
testStr=bf.readLine();
str+=testStr;
ch=testStr.charAt(testStr.length()-1); //读到单词最后一个字符
}while(ch!='#');
}catch(IOException e){
e.printStackTrace();
}
index=0; //重置单词字符索引
do{
Analyzer();
//输出数字及种别码
if (syn==26) {
System.out.println("("+syn+","+sum+")");
}
else if (syn==-1) {
System.out.println("没有该符号的种别码!!!");
}
else if (syn==-2) {
}
else {
System.out.println("("+syn+","+word+")");
}
}while(syn!=0);
}
static void Analyzer(){
//将单词容器清空
word.delete(0, word.length());
ch=str.charAt(index++);//获取单词每一个字符
//跳过空格
while(ch==' '){
ch=str.charAt(index++);
}
if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')){ //判断是关键字还是标识符
while((ch>='0'&&ch<='9')||(ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')){
word.append(ch);
ch=str.charAt(index++);
}
index--; //回退标记
syn=25;
String s=word.toString();
//判断为关键字
for(int i=0; i<keyWords.length; i++){
if(s.equals(keyWords[i])){
syn=i+1;
break;
}
}
}
//判断为是数字
else if((ch>='0'&&ch<='9')){
sum=0;
while((ch>='0'&&ch<='9')){
sum=sum*10+ch-'0';
ch=str.charAt(index++);
}
index--;
syn=26;
}
//判断为各种字符
else switch(ch){
case '<':
word.append(ch);
ch=str.charAt(index++);
//判断是否是<=
if(ch=='='){
word.append(ch);
syn=35;
}
//判断是否是<>
else if(ch=='>'){
word.append(ch);
syn=34;
}
//判断为<
else{
syn=33;
index--;
}
break;
case '>':
word.append(ch);
ch=str.charAt(index++);
//判断是否是>=
if(ch=='='){
word.append(ch);
syn=37;
}
//判断是>
else{
syn=36;
index--;
}
break;
case '*':
word.append(ch);
ch=str.charAt(index++);
//判断是否是**
if(ch=='*'){
word.append(ch);
syn=31;
}
//判断是*
else{
syn=13;
index--;
}
break;
case '=':
word.append(ch);
ch=str.charAt(index++);
//判断是否是==
if(ch=='='){
syn=32;
word.append(ch);
}
//判断是=
else{
syn=38;
index--;
}
break;
case '/':
word.append(ch);
ch=str.charAt(index++);
//判断是否是注释
if(ch=='/'){
while(ch!=' '){
ch=str.charAt(index++); //判断里面是否有空格
}
syn=-2;
break;
}
//判断是/
else{
syn=30;
index--;
}
break;
//判断是+
case '+':
syn=27;
word.append(ch);
break;
//判断是-
case '-':
syn=28;
word.append(ch);
break;
//判断是;
case ';':
syn=41;
word.append(ch);
break;
//判断是(
case '(':
syn=42;
word.append(ch);
break;
//判断是)
case ')':
syn=43;
word.append(ch);
break;
//判断是#
case '#':
syn=0;
word.append(ch);
break;
//判断是回车
case '\n':
syn=-2;
word.append(ch);
break;
//没有种别码
default:
syn=-1;
}
}
}
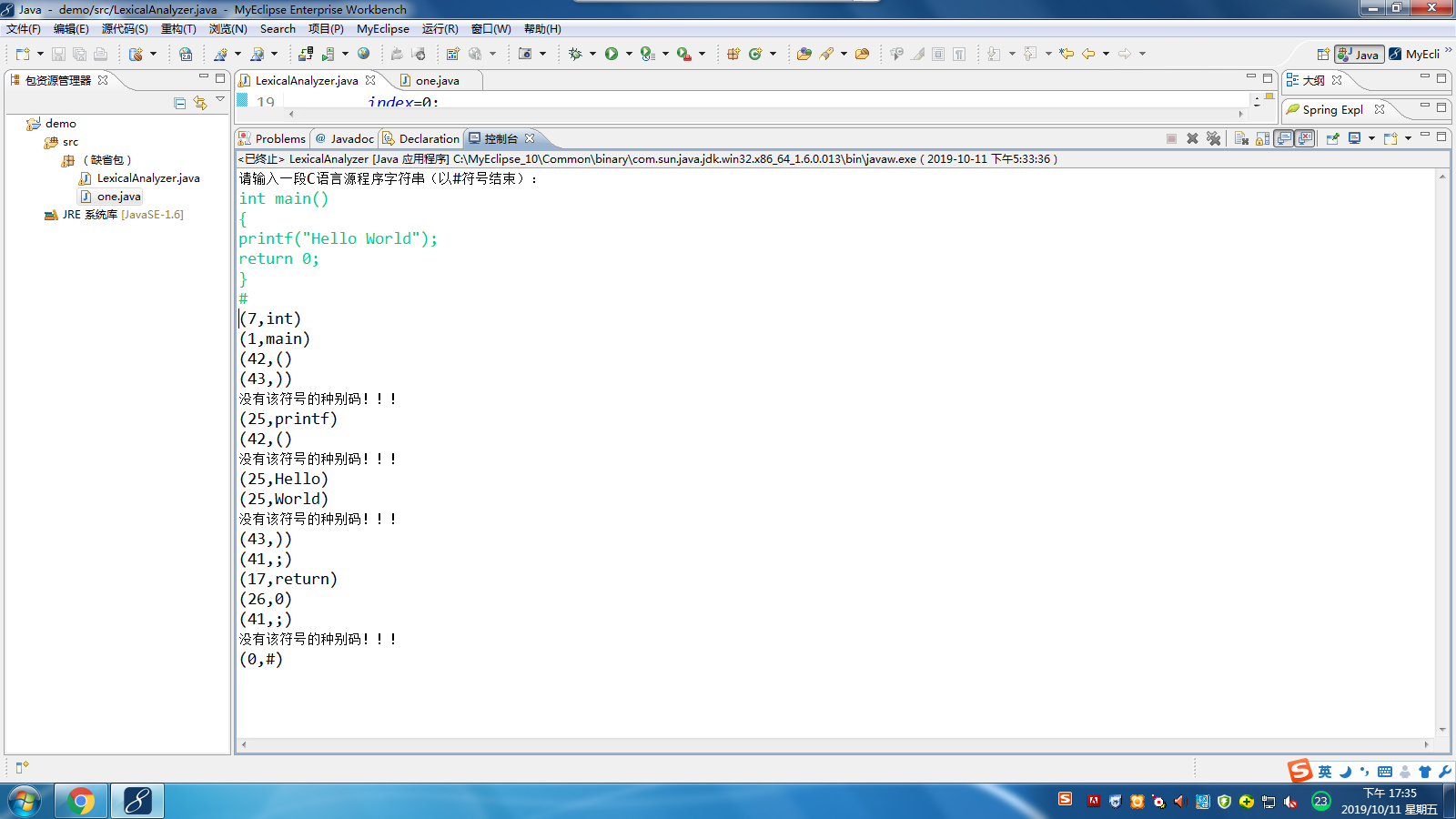
运行结果: