目前总体来讲最流行, 表现最好的算法:
Convolution Neural Network (CNN)
MNIST
CNN, gpu, deep network, dropout, ensembles
结果达到接近人肉眼识别水平:
9,967 / 10,000 识别正确
以下是误识别的图片

其中很多对于人肉眼都不容易识别
之前的神经网络
相邻层之前所有的神经元都两两相连
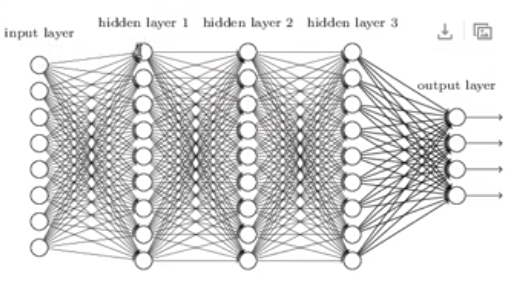
输入层: 图像像素值
输出层: 0-9
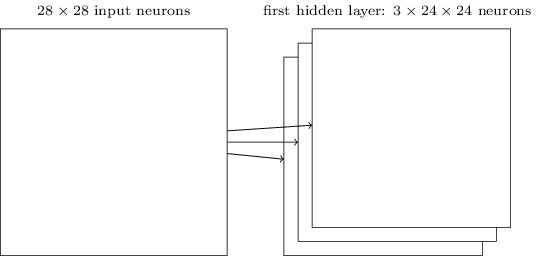
CNN结构很不一样(没有扁平化(把第二列接到第一列的后面,第三......)), 输入是一个二维的神经元 (28x28):

-------------------------------------------------------------------------------------------------------------------
Local receptive fields(5 x 5的小方块):

5 x 5条连接线
-------------------------------------------------------------------------------------------------------------------
构造第一个神经元

构造第2个神经元

28x28, 5x5 => 24x24
左向右,上向下
stride:每次移动多少。上例子stride=1
共享权重和偏向(shared weights and biases):
l:行
m:列
w:5x5
a:激活函数
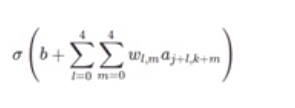
-------------------------------------------------------------------------------------------------------------------
对于第一个隐藏层, 所有神经元探测到同样的特征, 只是根据不同位置

(好处)保留图像原始的形状特征
-------------------------------------------------------------------------------------------------------------------
Feature map: 从输入层转化到输出层
以上3个feature maps, 每个是5x5
通常一些表现较好的方法都使用更多的feature map:

以上是学习出的, 根据5x5的feature map
浅色代表更小的权重(负数)
表明CNN在学习
共享的权重和偏向(weights, bias)大大减少了参数的数量:

对于每一个feature map, 需要 5x5=25个权重参数, 加上1个偏向b, 26个
如果有20个feature maps, 总共26x20=520个参数就可以定义CNN
如果像之前的神经网络, 两两相连, 需要 28x28 = 784 输入层, 加上第一个隐藏层30个神经元, 则需要784x30再加上30个b, 总共23,550个参数! 多了40倍的参数.

也可以写成:

Pooling layers:
浓缩神经网聚的代表性, 减小尺寸:

24x24 , 2x2 pooling => 12x12
多个feature maps:

重要特征点找到之后, 绝对位置并不重要, 相对位置更加重要
其他pooling: L2 pooling, 平方和开方
以上所有步骤结合在一起:

还是用Backpropagation, gradient descent解决