下面的操作 都是是kibana 中的 dev Tools工具操作的
一、索引
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。
-
#查看所有索引相关信息
-
GET /_cat/indices?v
-
#创建索引
-
PUT customer
-
#查看所有索引相关信息
-
GET customer
-
#删除索引
-
DELETE customer
-
#查看索引的文档总数
-
GET kibana_sample_data_ecommerce/_count
-
-
#查看前10条文档,了解文档格式
-
POST kibana_sample_data_ecommerce/_search
-
{
-
}
二、文档CRUD
一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以 JSON(Javascript Object Notation)格式来表示。

1 create 创建文档
_create 指定类型为create并不是type名称 默认是_doc 指定 ID 如果已经存在,就报错
-
#create document. _create 指定类型为create并不是type名称 默认是_doc 指定 ID 如果已经存在,就报错
-
PUT users/_create/
1
-
{
-
"user" :
"Jack2",
-
"post_date" :
"2019-05-15T14:12:12",
-
"message" :
"trying out Elasticsearch"
-
}
-
如果是id是1文档存在 在创建就会报错

2 index 创建文档
index和 create不一样地方:index 如果文档不错,就索引新的文档。如果文档存在就覆盖原有的文档内容。版本信息+1

3 GET查询索引
get 根据文档id查询 文档内容

4 Update 修改文档
update 修改文档 不会删除原文档 而是在 文档的基础上更新文档中的字段内容
# _update 才会根据文档中字段信息 在原文档上增加字段 必须带有doc
POST users/_update/1/
{
"doc":{
"post_date" : "2019-05-18T14:12:12",
"message" : "trying out ElasticsearchOut",
"phone" : "1806185",
"pubtest":[1,2,3],
"pubtest2":"[1,2,3]"
}
}

5 DELETE 删除文档
### Delete by Id
# 删除文档
DELETE users/_doc/1
6 查看索引的 maping 信息
maping 相当于表的 schema
GET users/_mapping

三 文档批量操作
bulk api 批量操作
1、bulk相当于数据库里的bash操作。
2、引入批量操作bulk,提高工作效率,你想啊,一批一批添加与一条一条添加,谁快?
3、bulk API可以帮助我们同时执行多个请求
4、bulk的格式:
action:index/create/update/delete
metadata:_index,_type,_id
request body:_source (删除操作不需要加request body)
{ action: { metadata }}
{ request body }
单条操作失败不会影响其他操作
5、bulk里为什么不支持get呢?
答:批量操作,里面放get操作,没啥用!所以,官方也不支持。
6、create 和index的区别
如果数据存在,使用create操作失败,会提示文档已经存在,使用index则可以成功执行。
7、bulk一次最大处理多少数据量?
bulk会把将要处理的数据载入内存中,所以数据量是有限制的,最佳的数据量不是一个确定的数值,它取决于你的硬件,你的文档大小以及复杂性,你的索引以及搜索的负载。
一般建议是1000-5000个文档,如果你的文档很大,可以适当减少队列,大小建议是5-15MB,默认不能超过100M,可以在es的配置文件(即$ES_HOME下的config下的elasticsearch.yml)中。
-
### Bulk 操作 批量操作,其中一步错误,不影响其他操作
-
-
PUT _bulk
-
{
"index":{
"_index":
"test",
"_id":
"1"}}
-
{
"name":
"dukun",
"post_date" :
"2019-05-18T14:12:12",
"age":
18,
"phone" :
"1806185",
"sex":
"男"}
-
{
"index":{
"_index":
"test",
"_id":
"2"}}
-
{
"name":
"dukun02",
"post_date" :
"2019-05-18T14:12:12",
"age":
25,
"phone" :
"19888",
"sex":
"男"}
-
{
"create":{
"_index":
"test",
"_id":
"3"}}
-
{
"name":
"dukun03",
"post_date" :
"2019-05-19T14:12:12"}
-
{
"update":{
"_index":
"test",
"_id":
"3"}}
-
{
"doc" :{
"name":
"dukun04",
"phone" :
"1806185",
"age":
28,
"sex":
"男"}}
-
{
"delete":{
"_index":
"test",
"_id":
"4"}}
mget 批量读取
批量操作可以减少网络连接所带来的开销,提供性能。
-
##批量查询mget
-
GET /_mget
-
{
-
"docs":[
-
{
-
"_index" :
"test",
-
"_id" :
"1"
-
},
-
{
-
"_index" :
"test",
-
"_id" :
"3"
-
}
-
]
-
}
-
##批量查询mget url中指定索引 可以简化如下
-
GET
test/_mget
-
{
-
"ids":[1,2,3]
-
}
-
#批量查询mget 中_source过滤默认_source字段会返回所有的内容,
-
你也可以通过_source进行过滤。
-
比如使用_source,_source_include 包含字段,_source_exclude 查询排除字段.
"_source" :
false 不显示字段
-
GET
test/_mget
-
{
-
"docs":[
-
{
"_id":
"1",
-
"_source" :
false
-
},
-
{
"_id":
"1",
-
"_source" :
true
-
},
-
{
"_id":
"2",
-
"_source" : [
"name",
"age"]
-
},
-
{
-
"_id":
"3",
-
"_source":{
-
"include":[
"name",
"age",
"sex"]
-
}
-
},
-
{
-
"_id":
"3",
-
"_source":{
-
"exclude":[
"name",
"age",
"sex"]
-
}
-
}
-
-
]
-
}
批量查询 _msearch

使用match_all进行查询,并且只返回第一个文档。如果没有指定size的值,则默认返回前10个文档
也可以指定返回从哪个文档开始,返回多少文档.
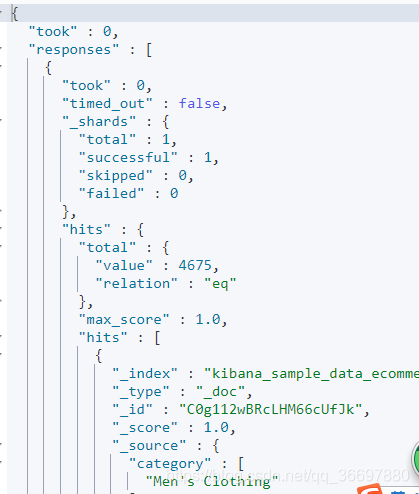
took —— Elasticsearch执行这个搜索的耗时,以毫秒为单位
timed_out —— 指明这个搜索是否超时
_shards —— 指出多少个分片被搜索了,同时也指出了成功/失败的被搜索的shards的数量
hits —— 搜索结果
hits.total —— 能够匹配我们查询标准的文档的总数目
hits.hits —— 真正的搜索结果数据(默认只显示前10个文档)