ElasticSearch7.x 全文搜索引擎
这里写目录标题
全文搜索
elasticSearch为什么比mysql更适合做搜索引擎
1.它会将该关键字(长度任意)即索引匹配到的所有⽹⻚返回(可以是非结构化数据)
2.搜索性能快,关系型数据库查询数据百分号前置索引失效
3.搜索灵活
4.非关系型数据库索引维护麻烦(在删除数据后要维护数的平衡)
适合全文索引引擎的场景
1.搜索的数据对象是⼤量的⾮结构化的⽂本数据
2.⽂本数据量达到数⼗万或数百万级别,甚⾄更多
3.需求⾮常灵活的全⽂搜索查询
4.数据大量读,写操作较少
elasticSearch安装与启动
1.下载安装包解压
tar -zxvf elasticSearch的安装包 -C /usr/local/elasticSearch
2.启动要求的配置
安装jdk8就可以,启动的时候会提示要用jdk11不管它
虚拟机内存要2G,内核2核 不然配置不够启不来
3.在bin目录启动
sh elasticsearch
4启动的问题
4.1要使用非root用户启动
root用户启动报错如下
Caused by: java.lang.RuntimeException: can not run elasticsearch as root
at
报错很明显“can not run elasticsearch as root”,所以切换到普通用户重新来吧
解决办法
//root用户下操作
//创建一个用户
adduser 用户名
//设置密码
passwd 用户名
//切换用户
su 用户名
4.2非root用户启动权限问题
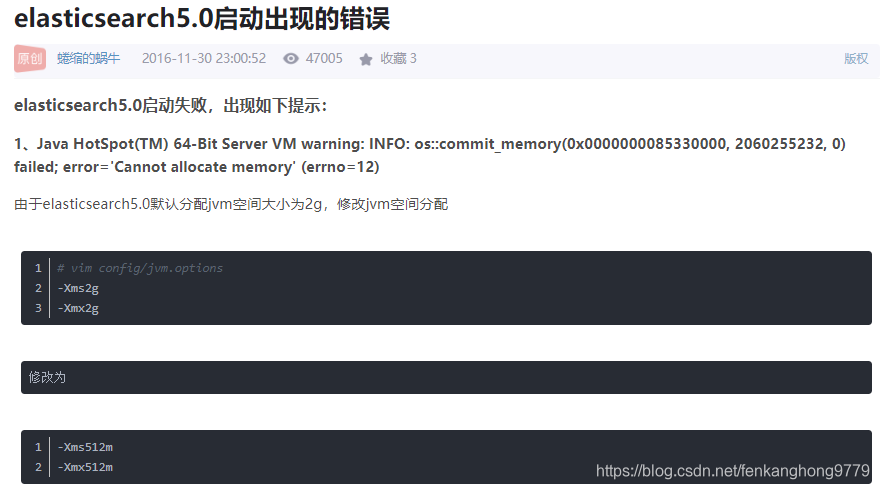
elasticsearch启动报错信息
java.nio.file.AccessDeniedException: /data/software/elasticsearch-6.2.4/config/jvm.options
问题原因:因为elasticsearh需要以非root的用户启动,启动会出现权限不够的情况
解决
在终端输入下面的命令即可(以root身份)
chown lizhiyu /usr/local/elasticsearch -R
chown 用户名 安装路径 -R
5.3ElasticSearch开启时端口不够用,修改linux中可用的端口数量
报错信息如下
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
[2]: max number of threads [3818] for user [es] is too low, increase to at least [4096]
[3]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决办法
1.修改 etc/security/limits.conf
vi /etc/security/limits.conf
2.在文件最后面加上
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096
3.修改sysctl.conf文件
执行
vi /etc/sysctl.conf
在文件最后面加上
vm.max_map_count=262144
4.配置重新生效
sysctl -p
5.重新启动
5.4在开启时成功启动,但是访问不成功
启动成功日志
问题描述
客户端使用ping ip 能通
telnet ip 9200 不通
浏览器输入ip:9200 访问不到
解决办法
1.关闭防火墙服务,并禁止开机启动(开启端口也可以)
sudo systemctl stop firewalld.service && sudo systemctl disable firewalld.service
2.在配置文件中添加访问权限(和redis类似)
修改elasticsearch.yml配置文件,允许外网访问时
vim config/elasticsearch.yml
增加
network.host: 0.0.0.0
5.5 ElasticSearch启动报错,bootstrap checks failed解决方案
修改elasticsearch.yml配置文件,在Discovery栏下加上“cluster.initial_master_nodes: [“node-1”]”,重启elasticsearch即可。如下所示:
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when this node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
#discovery.seed_hosts: ["host1", "host2"]
#
# Bootstrap the cluster using an initial set of master-eligible nodes:
#
cluster.initial_master_nodes: ["node-1"]
5.6最终访问成功
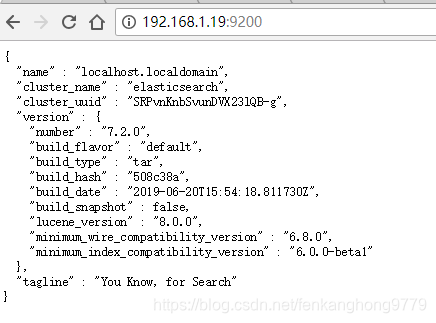
elasticsearch后台启动
ES中文分词器下载
ik 中文分词器,单独处理中文很强大
选择对应版本进行下载,下载后解压在es的plugins中,重启es即可
smartCN ⼀个简单的中⽂或中英⽂混合⽂本的分词器
一定要版本相同 否则会起不来
Kibana 安装
下载地址
运行 kibaba: 进入bin目录 直接运行 sh kibana 即可
选择对应ES版本进行下载,如果是集群要每台机器上都安装kibana
远程访问kibana界面被拒绝
- 检查端口是否开放;
- 修改config下面的配置文件,
因为Kibana 5.x 默认占用的地址是localhost(127.0.0.1)
将$KIBANA/config/kibaba.yml下的
server.host: “localhost” 更改为
server.host: “0.0.0.0” 或者自己的ip就可以了
然后访问 http://192.168.1.19:5601 (要加http 要不可能访问不通过)
进入Dev Tools 进行开发
后台运行 kibana
nohup sh kibana
logstash(日志窝)安装
官网
有什么用
可以将日志信息获得然后输出到指定位置
怎么用
首先下载logstash
logstash中有三个重要的组件 input filter output
input 指明日志的来源(数据库,redis,文件,http)
filter 对获得的日志进行处理 (对获得的数据可以正则截取)
output 指明日志输出到哪里(http,csv,es)
简单配置案例
创建一个配置文件logstash-filter.conf,文件中指明要使用的input、output、filter,代码如下
input {
#从文件读取日志信息
file {
path => "/var/log/messages"
type => "system"
start_position => "beginning"
}
}
filter {
}
output {
#标准输出
elasticsearch {
hosts => ["localhost:9200"]
index => "logstash-test-%{type}-%{host}"
}
}
运行
bin/logstash -f logstash-filter.conf