上几篇博客我们大致讲了一下mysql的底层结构,什么B+tree,什么Hash需要回行啊,再就是讲了mysql优化的explain,这次我们来说说mysql的锁。
mysql锁
锁从性能上分为乐观锁(用版本对比来实现)和悲观锁,乐观锁的性能要比悲观锁高。
从对数据库操作的类型分,分为读锁和写锁(都属于悲观锁)
读锁(共享锁):针对同一份数据,多个读操作可以同时进行而不会互相影响。除锁以外的线程只可读,不可以写入。
写锁(排它锁):当前写操作没有完成前,它会阻断其他写锁和读锁。除锁以外的线程不可以做任何操作。
从对数据操作的粒度分,分为表锁和行锁,再就是不常提到的间隙锁。
我们主要来说表锁和行锁,还有我们的间隙锁。
注意:有锁等待的几乎都为悲观锁
表锁
顾名思义,加了表锁,会将整张表锁住。开销很小,加锁很快,不会出现死锁;锁定粒度大,发生锁冲 突的概率最高,并发度最低;
我们来看几条命令。以student表为例
加表锁:lock table 表名称 read(write),表名称2 read(write);
lock table student write;
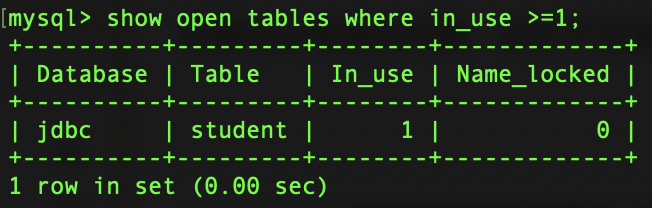
查看表状态(是否被加锁):
show open tables;
内有有一个列为In_use为1的即为已有锁存在。
解锁表:unlock tables;
unlock tables;
行锁
每次操作锁住一行数据。开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度最高。
说到这要提到我们的ACID了,我们来复习一下。
A(atomicity)原子性:
即事务要么全部做完,要么全部不做,不会出现只做一部分的情形,如A给B转帐,不会出现A的钱少了,B的钱却没有增加的情况,要么全部成功,要么全部失败(回滚)。这一系列的动作可以视为一个原子。
C(consistency)一致性:
指的是事务从一个状态到另一个状态是一致的,如A减少了100,B不可能只增加30。
I(isolation)隔离性:
即一个事务在没有完成数据的提交修改时,对其它事务是不可见的。当然这里有个隔离级别的概念,在不同隔离级别下,这里会有不同的表现形式。
D(durability)持久性:
一旦事务提交,则所做修改就会被永久保存到数据库中。
然后就是我们的并发事务处理带来的问题,先过一遍这些都会造成什么后果。
更新丢失(Lost Update)
当两个或多个事务选择同一行,然后基于最初选定的值更新该行时,由于每 个事务都不知道其他事务的存在,就会发生丢失更新问题–最后的更新覆盖了由其 他事务所做的更新。
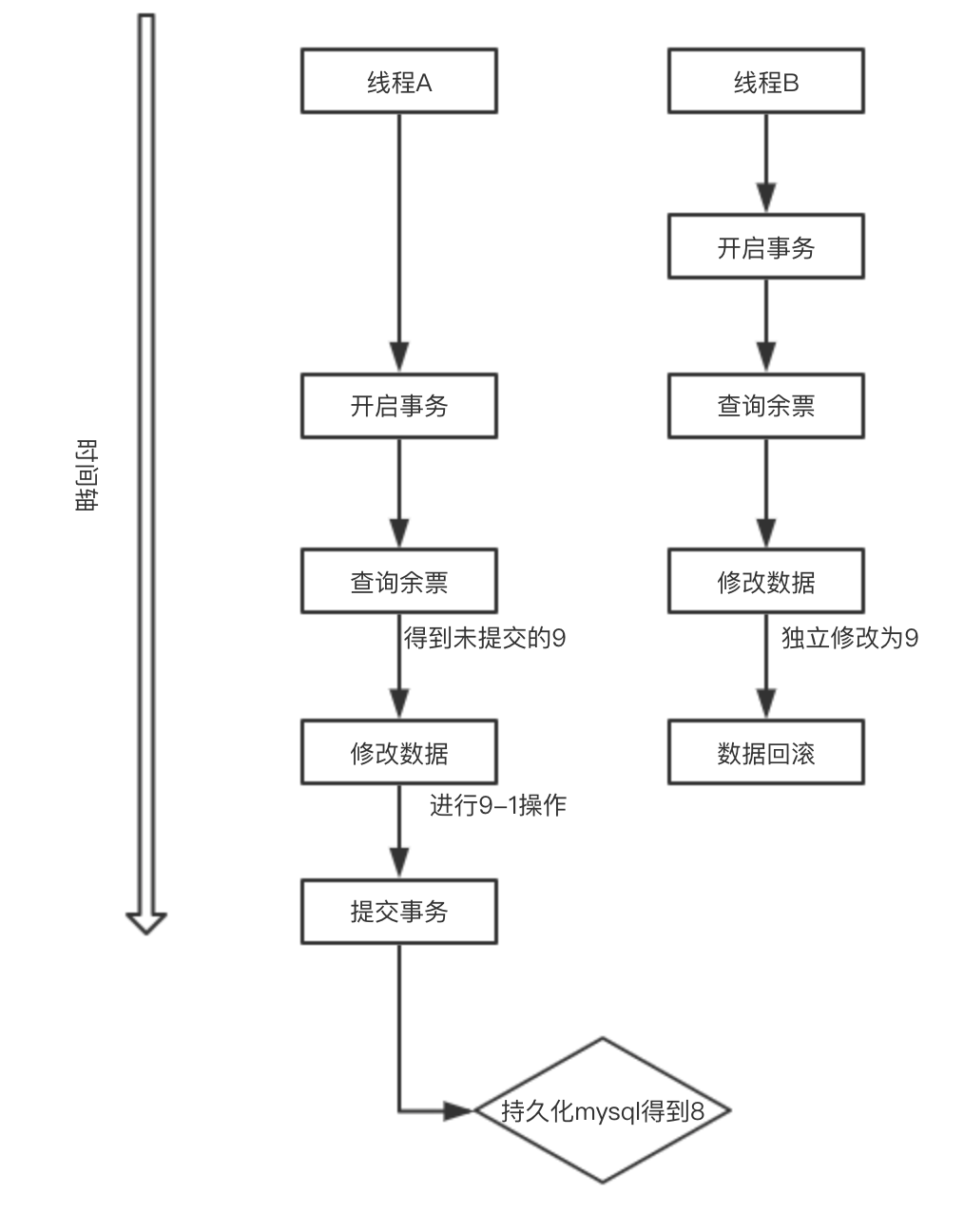
举例:比如我们同时开启两个线程去售票,卖一张少一张,我们线程A开启事务,同时我们开启线程B,同时查询到余票为10张,卖一张吧。A卖了一张,10-1,剩余9张,我们B线程也卖了一张也是10-1,也剩余9张,提交A,提交B,我们明明卖了两张票,可是数据库得到的确实9,只卖了一张票。

脏读(Dirty Reads)
一个事务正在对一条记录做修改,在这个事务完成并提交前,这条记录的数 据就处于不一致的状态;这时,另一个事务也来读取同一条记录,如果不加控 制,第二个事务读取了这些“脏”数据,并据此作进一步的处理,就会产生未提 交的数据依赖关系。这种现象被形象的叫做“脏读”。 一句话:事务A读取到了事务B已经修改但尚未提交的数据,还在这个数据基 础上做了操作。此时,如果B事务回滚,A读取的数据无效,不符合一致性要求。
不可重读(Non-Repeatable Reads)
一个事务在读取某些数据后的某个时间,再次读取以前读过的数据,却发现 其读出的数据已经发生了改变、或某些记录已经被删除了!这种现象就叫做“不 可重复读”。 一句话:事务A读取到了事务B已经提交的修改数据,不符合隔离性。
幻读(Phantom Reads)
一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象就称为“幻读”。 一句话:事务A读取到了事务B提交的新增数据,不符合隔离性
后面的两个说完MVCC机制也就知道是怎么回事了,暂时放在这里。
这些问题我们再回到我们的数据库吧。

一般都设置为可重复读的。数据库的事务隔离越严格,并发副作用越小,但付出的代价也就越大,因为事务隔离实质上就是使事务在一定程度上“串行化”进行,这显然与“并发”是矛盾的。 同时,不同的应用对读一致性和事务隔离程度的要求也是不同的,比如许多应用
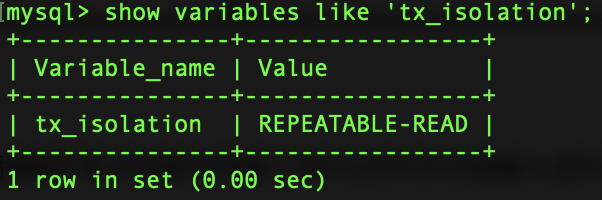
对“不可重复读"和“幻读”并不敏感,可能更关心数据并发访问的能力。 常看当前数据库的事务隔离级别: show variables like 'tx_isolation'; 设置事务隔离级别:set tx_isolation='REPEATABLE-READ';
其余的可以自己去尝试一下,读未提交READ-UNCOMMITTED,读已提交READ-COMMITTED,可串行化SERIALIZABLE;
MVCC:
这个超级重要,懂了这个上面的几乎都懂了~!

英文全称为Multi-Version Concurrency Control,翻译为中文即 多版本并发控制。这个概念很抽象,我们并不知道他控制的是什么。
举一个栗子来说一下,假设我们的MySQL表里有两个虚拟的字段,一个叫开启事务ID,一个叫删除事务ID,都为自增的。再开启事务时不会给予任何数值,在执行第一条SQL时,给予开启事务ID一个数字,我们假设为0,但是不给与提交事务ID(还是为空)。以我们给出的学生表为例上图说话。
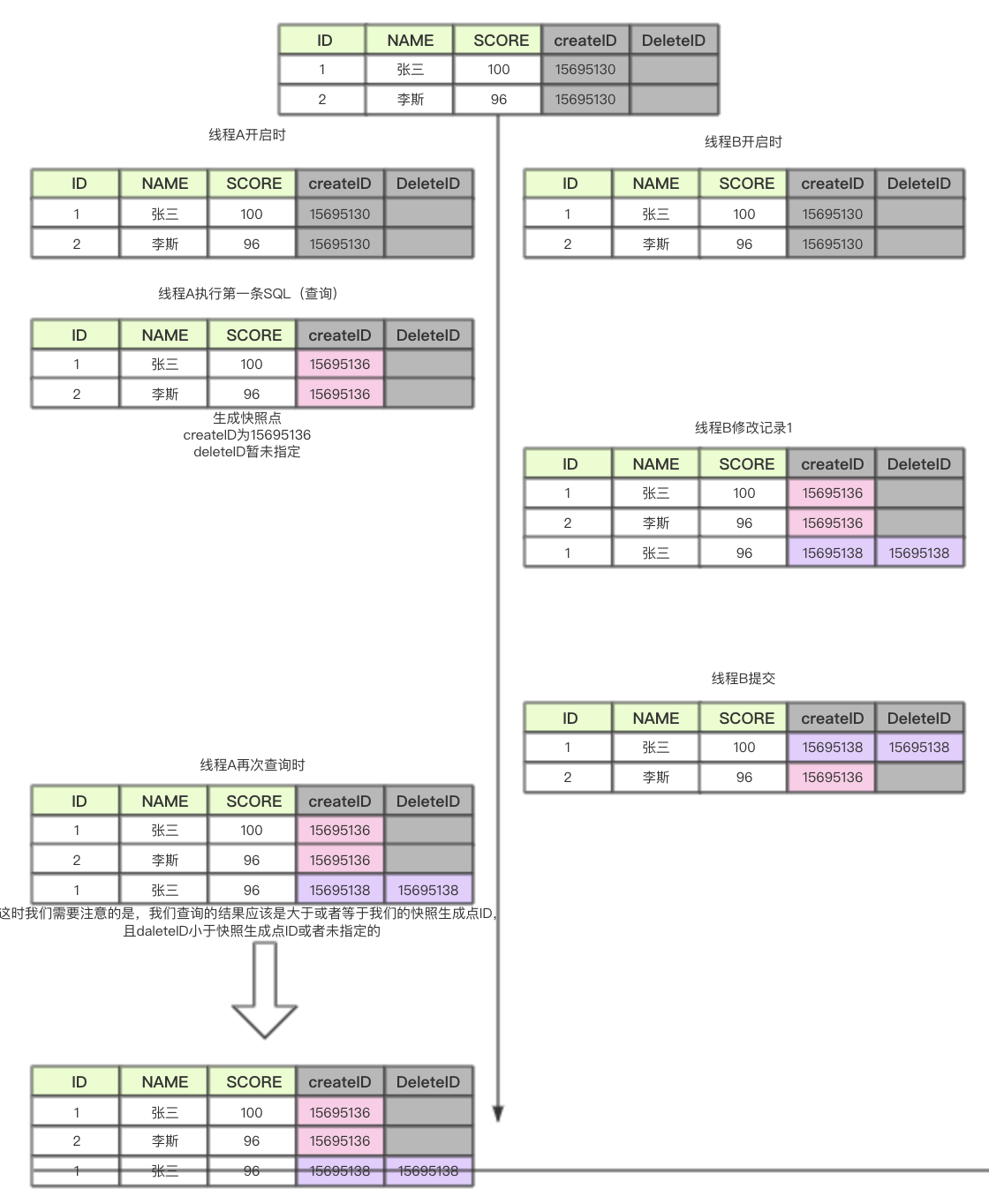
简单说一下图的意思,我们每次在运行sql的时候,都会以时间戳生成一个快照版本号,如果是查询SQL,会把这个版本号更新到我们的createID字段,增删改操作会把我们的版本号更新到的deleteID字段,每个线程事务之间版本号是独立的,对于我们的下一次查询来说,我们会查询数据中createID大于等于我们的快照版本号,且deleteID小于我们的当前的快照版本号ID的数据。MVCC一般在可重复读的隔离级别,但同时在读已提交也是试用的。MVCC缺点是会保存多个快照版本,造成了空间的冗余,但是保证了每个线程的独立操作。
间隙锁
简单说一下间隙锁,如果我们的表ID是自增的,我们写一个开启事务,我们写一条修改SQL
update student set name = '1111' where id>8 and id<22;
也就是说,不管你有没有id为8~22的数据,这时都对小于8的最大ID到大于22的最小ID这个范围加了锁,这断范围是禁止你新增和修改的,其余位置是可以的。看你的表结构
比如你的表是
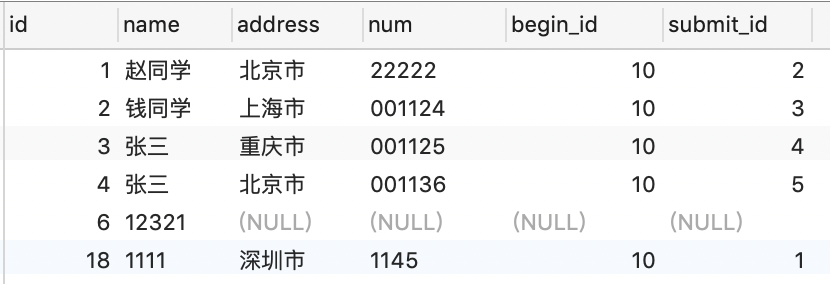
sql为 update student set name = '1111' where id>8 and id<22; 其实我们加锁的范围是(6~22)的范围开区间都是不可以操作的 。
锁升级:
我们内部的InnoDB的锁是加在索引上的,也就是说,我们update或者delete时后面的where条件尽力要跟索引字段。
锁的分析:
分别表示为
Innodb_row_lock_current_waits: 当前正在等待锁定的数量
Innodb_row_lock_time: 从系统启动到现在锁定总时间长度(等待总时长)
Innodb_row_lock_time_avg: 每次等待所花平均时间(等待平均时长)
Innodb_row_lock_time_max:从系统启动到现在等待最长的一次所花时间
Innodb_row_lock_waits:系统启动后到现在总共等待的次数(等待总次数)
死锁
也就是相互的锁等待造成死锁。
查看近期死锁日志信息:show engine innodb status\G; 大多数情况mysql可以自动检测死锁并回滚产生死锁的那个事务,但是有些情况mysql没法自动检测死锁
尽可能让所有数据检索都通过索引来完成,避免无索引行锁升级为表锁,合理设计索引。
尽量缩小锁的范围,尽可能减少检索条件范围,避免间隙锁。
尽量控制事务大小,减少锁定资源量和时间长度,涉及事务加锁的sql
尽量放在事务最后执行
尽可能低级别事务隔离

